[Spring Data JPA] @Transactional에 대하여.
함께 읽으면 좋은 이전 글들
이번 글에서는 필자가 개인적으로 Spring data JPA와 @Transactional 에 대해 헷갈려하거나 모호하게 이해했던 내용들, 그리고 관련 자료조사를 하면서 새롭게 알게 된 사실들을 기존 지식들과 함께 정리해보고자 한다.
DB transaction과 @Transactional 의 차이
문득 DB에서의 transaction이란 개념과 Spring data JPA에서 사용하는 @Transactional 이 서로 다른 점이 있나, 라는 생각이 들어 이 점에 대해 잠시 살펴보고자 한다.
DB에서의 transaction은 데이터베이스의 상태 변화를 위해 수행하는 더 이상 분할할 수 없는 논리적 작업 단위로, 하나라도 실패하면 안되는 작업들을 모아놓는 것이 특징이다. MariaDB와 같은 DBMS에서는 이를 위해 COMMIT , ROLLBACK 등의 TCL(Transaction Control Language)를 이용하여 transaction을 실질적으로 수행할 수 있다.
이러한 개념은 사실 Spring data JPA에서의 @Transactinoal 에서도 똑같이 적용된다. JPA에서도 똑같이 하나의 작업 단위에 대해 해당 작업이 모두 성공하면 commit, 하나라도 실패하면 rollback 시키는 연산을 한다.
이렇듯 개념적으로는 둘 다 차이가 없다고 본다. 단지 @Transactional 은 transaction이라는 기능을 JPA에 구현한 것이다.
public void insertOne() {
EntityManagerFactory factory = Persistence.createEntityManagerFactory("myjpa");
EntityManager manager = factory.createEntityManager();
EntityTransaction transaction = manager.getTransaction();
try {
transaction.begin();
Products products = Products.builder()
.name("냉동피자")
.price(10000)
.category("food")
.build();
manager.persist(products);
transaction.commit();
} catch (Exception e) {
System.out.println("=== DB 작업 중 에러 발생! ===");
e.printStackTrace();
// 오류 발생 시 이전까지의 작업들을 모두 취소하고 이전 커밋으로 되돌아감.
transaction.rollback();
} finally {
manager.close();
factory.close();
}
}
코드 1-1. hibernate를 이용하여 insert 작업을 하는 메서드 코드 예시. JPA에서도 commit() , rollback() 등이 있어 DBMS에서의 TCL과 동일한 작업을 수행한다.
다만 @Transactional 의 경우 JPA에서 사용하는 것이다보니 일반 DBMS와 달리 JPA에 특화된 여러 사실들이 있다. 다음 챕터부터 이에 대해 기술한다.
@Transactional 을 사용하는 경우는 언제?
순수 DB로 따지면 DML에 해당하는 DB 작업을 할 경우, 해당 메서드에 @Transactional 을 붙이곤 했다. 프레젠테이션(컨트롤러), 서비스, 영속성 계층으로 구성된 레이어드 아키텍처의 경우 보통 서비스 계층에서 영속성 계층으로부터 데이터를 얻어와 비즈니스 로직을 작성하고, 반대로 서비스 계층에서 DB 상태 변화를 위해 영속성 계층을 이용하기도 하므로, 해당 어노테이션은 주로 서비스 계층에서 자주 사용하곤 한다. 그런데 문득 ‘DB 작업이라면 무조건 @Transactional 을 사용해야하는건가? 어쩌면 나도 모르게 안써도 되는 곳에 너무 남발하는 건 아닐까’라는 생각이 들었다. 그래서 이 챕터에서는 @Transactional 을 언제 사용하면 좋을지에 대해 서술한다.
Dirty checking과 @Transactional
JPA 이용 시 DB의 특정 데이터 값을 변경(update)하고자 하는 경우, 2가지 방법을 사용할 수 있겠다. 하나는 save() 를 이용하는 방법이고, 또 하나는 dirty checking을 이용하는 방법이다. 영속성 컨텍스트(Persistence context) 내부의 1차 캐시 저장소에는 영속 상태의 엔티티 객체들의 정보인 스냅샷이 저장되어 있다. dirty checking의 경우 트랜잭션이 끝나는 시점에서 실제 엔티티 객체와 엔티티 스냅샷을 비교하여 이 둘의 정보가 다르다면 정보가 업데이트되었다고 감지하고, UPDATE 쿼리문을 생성하여 영속성 컨텍스트 내 SQL 저장소에 저장한 다음 이를 DB에 반영하는 방식이다. 이러한 dirty checking 방식을 이용할 경우, 엔티티 객체 내에서 변경된 일부 값만 선택적으로 업데이트되기에 save() 방식처럼 변경되지 않는 값까지 입력해줄 필요가 없다는 편의성이 있다. 또한 dirty checking 시에는 굳이 save() 를 호출하지 않아도 변경된 값이 자동으로 반영된다1.
@Override
@Transactional
public BookResponse updateBook(int id, BookRequest bookRequest) {
if (!bookRepository.existsById(id)) {
return null;
}
Book updateBook = Book.builder()
.id(id)
.name(bookRequest.getName())
.price(bookRequest.getPrice())
.build();
updateBook = bookRepository.save(updateBook);
return BookResponse.toDto(updateBook);
}
코드 2-1. save() 방식을 이용한 객체 값 업데이트 코드 예시.
@Override
@Transactional
public BookResponse updateBook(int id, BookRequest bookRequest) {
Optional<Book> targetBookOpt = bookRepository.findById(id);
if (targetBookOpt.isEmpty()) {
return null;
}
Book targetBook = targetBookOpt.get();
targetBook.setName(bookRequest.getName());
targetBook.setPrice(bookRequest.getPrice());
return BookResponse.toDto(targetBook);
}
코드 2-2. dirty checking을 이용한 엔티티 객체 값 업데이트 코드 예시.
그런데 문득 필자는 ‘dirty checking 시에는 무조건 해당 메서드에 @Transactional 을 적용해야하나’란 의문이 들었다. 그래서 코드 상으로 해당 어노테이션을 적용할 때와 그렇지 않을 때를 비교해보니 해당 어노테이션이 없으면 dirty checking이 되지 않아 DB 상에서 값 변경이 일어나지 않음을 확인하였다. 따라서 dirty checking 시에는 반드시 @Transactional 을 적용해야한다.
다음은 https://github.com/hibernate/hibernate-orm 에 있는 코드 일부이다.
/**
* Flushes a single entity's state to the database, by scheduling
* an update action, if necessary
*/
@Override
public void onFlushEntity(FlushEntityEvent event) throws HibernateException {
final Object entity = event.getEntity();
final var entry = event.getEntityEntry();
final var session = event.getSession();
// short-circuit for immutable entities....
if ( !entry.getPersister().isMutable() && !entry.getPersister().hasCollections() ) {
// nothing to do
return;
}
final boolean mightBeDirty = entry.requiresDirtyCheck( entity );
final Object[] values = getValues( entity, entry, mightBeDirty, session );
event.setPropertyValues( values );
//TODO: avoid this for non-new instances where mightBeDirty==false
boolean substitute = wrapCollections( event, values );
if ( isUpdateNecessary( event, mightBeDirty ) ) {
substitute = scheduleUpdate( event ) || substitute;
}
if ( entry.getStatus() != Status.DELETED ) {
final var persister = entry.getPersister();
// now update the object
// has to be outside the main if block above (because of collections)
if ( substitute ) {
persister.setValues( entity, values );
}
// Search for collections by reachability, updating their role.
// We don't want to touch collections reachable from a deleted object
if ( persister.hasCollections() ) {
new FlushVisitor( session, entity )
.processEntityPropertyValues( values, persister.getPropertyTypes() );
}
}
}
// ...
/**
* Perform a dirty check, and attach the results to the event
*/
protected void dirtyCheck(final FlushEntityEvent event) throws HibernateException {
int[] dirtyProperties = getDirtyProperties( event );
event.setDatabaseSnapshot( null );
if ( dirtyProperties == null ) {
// do the dirty check the hard way
dirtyProperties = performDirtyCheck( event );
}
else {
// the Interceptor, SelfDirtinessTracker, or CustomEntityDirtinessStrategy
// already handled the dirty check for us
event.setDirtyProperties( dirtyProperties );
event.setDirtyCheckHandledByInterceptor( true );
event.setDirtyCheckPossible( true );
}
logDirtyProperties( event.getEntityEntry(), dirtyProperties );
}
코드 2-3. hibernate-orm 에서의 DefaultFlushEntityEventListener 클래스의 일부 메서드들.
위 코드를 보면 알 수 있는 것은 flush() 가 호출될 때 dirty checking이 수행된다는 것이다.
@Override
public void beforeTransactionCompletion() {
SESSION_LOGGER.beforeTransactionCompletion();
flushBeforeTransactionCompletion();
actionQueue.beforeTransactionCompletion();
beforeTransactionCompletionEvents();
super.beforeTransactionCompletion();
}
코드 2-4. hibernate-orm 에서의 SessionImpl 클래스의 일부 메서드.
또한 위 코드에서 알 수 있는 것은 beforeTransactionCompletion() 내부에서 flushBeforeTransactionCompletion(); 가 호출되는 것을 보아, flush 작업은 트랜잭션의 commit 전 단계에서 일어남을 알 수 있다.
즉, 이를 종합해보자면, dirty checking은 트랜잭션 내부에서 실행되며, flush() 가 실행되고 commit() 이 실행되기 전 그 사이에 dirty checking이 실행되는 구조임을 알 수 있다. 따라서 dirty checking을 사용할 때에는 반드시 @Transactional 을 적용해야하는 것이다.
둘 이상의 repository 호출 시
DBMS에서 둘 이상의 DML 쿼리문들이 사용된다면 이들을 하나의 작업 단위인 트랜잭션으로 묶어 실행하도록 함으로써 모두 성공하거나 모두 실패하거나라는 두 가능성만 남겨 성공할 땐 DB에 영구적으로 반영하고, 그렇지 않을 땐 이전으로 롤백하도록 할 것이다.
JPA에서도 이와 마찬가지 원리로, 하나의 서비스 메서드 내에서 둘 이상의 repository 메서드가 호출되는 상황이라면, 그리고 더군다나 그 메서드들의 작업 결과가 모두 성공해야만 한다면 더더욱 @Transactional 을 부여하여 하나의 트랜잭션으로 묶어주는 것이 좋다.
그러면 예를 들어 서비스 메서드 내부에 하나는 save() , delete() 와 같은 DML 역할의 repository 메서드가 있고, 또 하나는 findById() 와 같이 SELECT에 해당하는 repository 메서드가 호출되고 있다고 해보자. 그러면 이 경우에도 @Transactional 을 사용해야할까? DBMS에서는 SELECT가 DB 상태를 변화시키지 않으므로 굳이 트랜잭션으로 묶일 필요가 없을 것이다. 이와 같은 논리가 이 JPA에서도 똑같이 적용되어야할 것처럼 보인다.
그런데 스프링 공식 문서 “Transactionality”에서의 한 예시 코드와 그에 덧붙여진 설명을 보면 앞선 예상과 조금 다른 점이 보인다.
/*
Another way to alter transactional behaviour is to use a facade or service implementation that (typically) covers more than one repository. Its purpose is to define transactional boundaries for non-CRUD operations. The following example shows how to use such a facade for more than one repository:
*/
@Service
public class UserManagementImpl implements UserManagement {
private final UserRepository userRepository;
private final RoleRepository roleRepository;
public UserManagementImpl(UserRepository userRepository,
RoleRepository roleRepository) {
this.userRepository = userRepository;
this.roleRepository = roleRepository;
}
@Transactional
public void addRoleToAllUsers(String roleName) {
Role role = roleRepository.findByName(roleName);
for (User user : userRepository.findAll()) {
user.addRole(role);
userRepository.save(user);
}
}
}
코드 3-1. 스프링 공식 문서의 “Transactionality” 문서에서 참고함.
“둘 이상의 repository를 호출할 때 @Transactional 을 적용하여 트랜잭션의 경계를 정의할 수 있다”라면서 위와 같은 예시 코드가 보이는데, 위 예시 코드에서는 save() 를 제외하고선 모두 findAll 과 같은 조회 메서드임을 볼 수 있다.
다음 코드는 Spring Data JPA가 아닌 순수 hibernate를 사용할 때 데이터들을 조회하는 예시 코드이다.
public List<Products> getDataAll() {
EntityManagerFactory factory = Persistence.createEntityManagerFactory("myjpa");
EntityManager manager = factory.createEntityManager();
// EntityTransaction transaction = manager.getTransaction();
List<Products> products = null;
try {
// transaction.begin();
// JPQL을 이용하여 테이블 내 모든 상품들 조회.
String jpql = "SELECT p FROM Products p";
TypedQuery<Products> query = manager.createQuery(jpql, Products.class);
products = query.getResultList();
// transaction.commit();
} catch (Exception e) {
System.out.println("=== DB 작업 중 에러 발생! ===");
e.printStackTrace();
// transaction.rollback();
} finally {
manager.close();
factory.close();
}
return products;
}
코드 3-2. 순수 hibernate 이용 시 데이터들을 조회하는 메서드 예시 코드.
EntityManager는 하나의 트랜잭션 내부의 영속성 컨텍스트를 관리하는 객체이다. 그리고 EntityManager의 close() 를 호출하는 순간, 해당 영속성 컨텍스트 자체가 메모리 상에서 사라지기에, 영속성 컨텍스트 자체에 있던 Entity 객체들은 준영속(Detached) 상태에 놓이게 된다. 즉, 위 코드와 함께 보면, 처음에 DB로부터 조회한 데이터들은 Entity 객체와 매핑되어 영속성 컨텍스트 내부로 들어오게 되는데, 이 때의 Entity 객체들은 영속 상태에 놓이게 된다. 그러다가 EntityManager#close() 를 호출하는 순간 영속성 컨텍스트 자체가 사라져 Entity 객체들은 준영속 상태로 바뀌게 되는 것이다.
위 코드에서 보인 transaction.commit() 등의 트랜잭션 코드는 Spring Data JPA로 넘어오면서 @Transactional 로 간편화되었다고 보면 되겠다. 따라서 굳이 commit() 등의 코드를 호출하지 않아도 해당 어노테이션만으로도 서비스 메서드를 하나의 트랜잭션으로 묶을 수 있는 것이다.
또 한 가지 사실은, Spring data JPA에서, repository에서 기본으로 제공하는 save() , findBy... 등의 메서드들에는 기본적으로 @Transactional 이 적용되어 있다는 것이다. 앞서 소개한 스프링 공식 문서에는 이런 말이 있다.
By default, methods inherited from
CrudRepositoryinherit the transactional configuration fromSimpleJpaRepository. For read operations, the transaction configurationreadOnlyflag is set totrue. All others are configured with a plain@Transactionalso that default transaction configuration applies. Repository methods that are backed by transactional repository fragments inherit the transactional attributes from the actual fragment method.
즉 위 원문을 통해 알 수 있는 것은,
- repository에서 제공하는 메서드들에는 기본적으로 각각
@Transactional이 적용되어 있으며, - 심지어는 읽기 연산을 하는
findBy...같은 메서드들에서조차@Transactional이 적용되어 있다.
하나의 동일한 트랜잭션 범위 내에서는 하나의 동일한 영속성 컨텍스트에 접근할 수 있다는 사실과 결합해보면, 비록 findBy... 와 같은 DB 상태를 변경시키지 않는 조회 메서드라 할지라도 같은 영속성 컨텍스트 내에서 DB 작업을 하기 위해선 해당 서비스 메서드에 @Transactional 을 적용해야만 한다는 것이다.
참고로 위 원문에서 이야기하는 SimpleJpaRepository 는 org.springframework.data.jpa.repository.support 이라는 라이브러리에 존재하며, 해당 코드는 다음과 같이 생겼다.
@Repository
@Transactional(
readOnly = true
)
public class SimpleJpaRepository<T, ID> implements JpaRepositoryImplementation<T, ID> {
// 생략...
@Transactional
public void deleteById(ID id) {
//...
}
public Optional<T> findById(ID id) {
// ...
}
@Transactional
public <S extends T> S save(S entity) {
// ...
}
}
코드 3-3. org.springframework.data.jpa.repository.support.SimpleJpaRepository 코드 일부.
참고로 클래스 단위에 적용된 @Transactional 은 그 안의 메서드들에도 적용되기에 위 코드의 findById 메서드에는 @Transactional(readOnly = true) 가 이미 적용된 셈이다. 다만 deleteById() 와 같이 이미 메서드 수준에 @Transactional 이 적용된 경우, 클래스 수준의 @Transactional 은 무시된다.
이를 통해 하나의 서비스 메서드에서 특정 데이터를 findBy... 등으로 조회한 후, 해당 데이터를 대상으로 dirty checking을 할 때 해당 메서드에 @Transactional 을 부여해야하는 이유가 설명된다(코드 2-2 참고). 만약 해당 어노테이션을 부여하지 않는다면, findById() 메서드 호출로 DB로부터 조회된 영속 상태의 Entity 객체들이 findById() 호출이 끝남에 따라 영속성 컨텍스트가 사라져 준영속 상태로 놓이게 되며, 이로 인해 영속 상태에 놓인 Entity 객체들만을 대상으로 하는 dirty checking이 일어날 수가 없는 것이다.
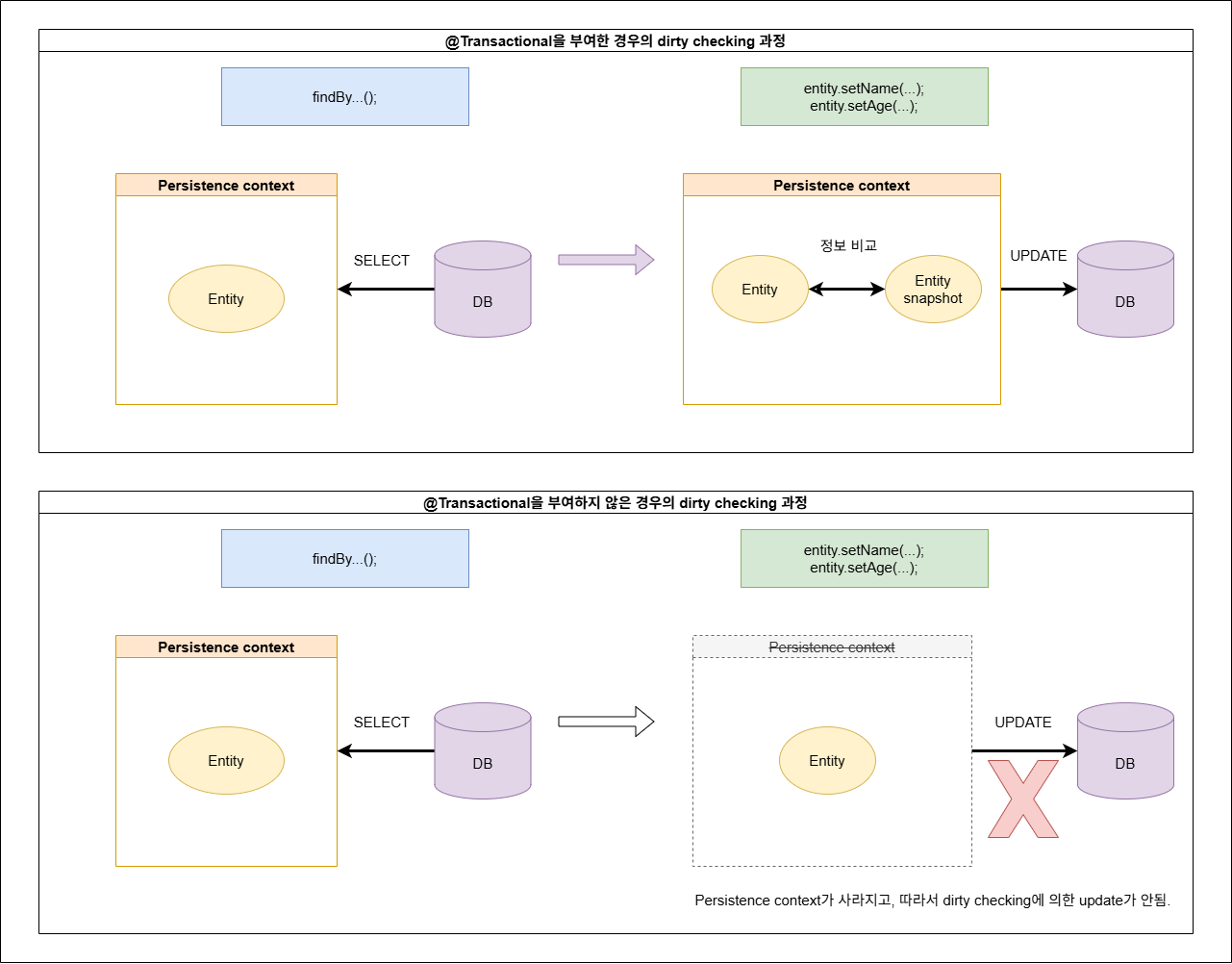
그림 1-1. dirty checking 시 @Transactional 을 부여할 때와 그렇지 않을 때의 영속성 컨텍스트의 상태 변화를 그린 그림.
한 편, save() , findById() 와 같이 repository에서 기본으로 제공하는 메서드들의 경우, 이들이 하나의 서비스 메서드에서 여럿 사용되고 있고, 해당 서비스 메서드에 @Transactional 이 부여되어 있는 경우, 기본적으로는 repository 수준에 적용되어있는 @Transactional 은 무시되고 서비스 메서드에 설정된 @Transactional 이 적용된다2. 앞서 살펴본 코드 3-1에서의 addRoleToAllUsers 라는 서비스 메서드를 보면 여기에 @Transactional 이 적용되어 있으며, 이 안에는 findByName() , findAll() 등의 repository 메서드들도 호출되고 있다. repository 메서드들은 각각 이미 @Transactional 이 부여된 상태이지만, 서비스 메서드에 이미 @Trasactional 이 부여되었기에 repository 수준에서의 @Transactional 은 무시된다는 것이다.
이 챕터에서 도출한 사실들을 정리하면 다음과 같다.
save(),findById()등 repository에 기본으로 정의된 메서드들에는 기본적으로 각각@Transactional이 부여되어 있다.findById()처럼 조회 목적의 메서드들에는@Transactional(readOnly = true)가 설정되어 있다.readOnly = true에 대해서는 다음 챕터에서 자세히 기술할 예정.- 하나의 서비스 메서드 내부에서 둘 이상의 repository가 사용된다면, 그리고 이들을 하나의 작업 단위로 묶고자 한다면 해당 메서드에
@Transactional을 부여하는 것이 좋다.- 설령
findById()와 같은 조회 메서드라 할지라도 하나의 트랜잭션 내에서는 동일한 영속성 컨텍스트를 사용하기에 동일한 영속성 컨텍스트에서 작업하도록 하고자 한다면@Transactional을 해당 서비스 메서드에 부여한다.
- 설령
이 챕터에서의 이야기들을 바탕으로 보자면, 하나의 서비스 메서드 내에서 하나의 repository 메서드만 사용되는 경우에는 이미 repository 메서드(@Query 등으로 개발자가 직접 정의하지 않았다면) 단계에서 해당 어노테이션이 부여되어있기 때문에 굳이 해당 서비스 메서드에 @Transactional 을 부여하지 않아도 될 것이다.
@Transactional(readOnly = true)의 의미
한 편, @Transactional 에서는 readOnly 속성을 지원한다. 해당 속성값은 기본적으로 false로 지정되어 있다. 하나의 서비스 메서드 내에서 findById() 처럼 조회 목적의 repository 메서드들만 호출한다면 해당 메서드에 @Transactional(readOnly = true) 을 적용할 수 있겠다.
그런데, 읽기 전용이라면 왜 해당 어노테이션을 적용해야할까? 보통 주로 데이터 상태를 변경하는 작업들이 여러 개일 때 이들을 하나로 묶어 작업하기 위해 사용하는게 transaction이란 개념인데, 조회 목적의 repository 메서드들만 호출할 것이라면 왜 굳이 @Transactional(readOnly = true) 를 사용해야할까?
앞서 잠시 살펴본 스프링 공식 문서에 따르면, @Transactional(readOnly = true) 를 적용할 경우, 읽기 작업 성능이 향상된다고 한다. 한 예로 만약 Hibernate와 함께 사용할 경우, readOnly = true 속성은 flush 모드를 NEVER 로 설정하게 하고, 이에 따라 flush 과정이 실행되지 않으며, Hibernate에서는 dirty check 과정, 즉 실제 엔티티 객체와 영속성 컨텍스트 내에 저장된 엔티티 snapshot과의 비교 및 변경 사항을 저장하는 이 과정 자체를 생략한다고 한다. 이로 인해 성능이 향상된다고 한다. 특히나 대량의 읽기 작업을 수행할 경우에 이 효과를 더 크게 체감할 수 있으리라고 예상된다.
한 편, @Transactional(readOnly = true) 를 사용한다고 해도 DB에서 INSERT, UPDATE 등의 조작 쿼리문을 트리거하지 않는다는 보장은 하지 않는다고 한다.
필자가 이전에 쓴 글인 https://jerocaller.github.io/infra&cloud/infra-db-clustering,-failover,-load-balancing-ft-quartz/#replication 에서도 잠시 언급했지만, 서버를 master 서버와 slave 서버로 나누고, master는 INSERT, UPDATE, DELETE 등의 DML 작업이 이뤄지는 용도로, slave 서버에서는 오로지 SELECT 작업만 이뤄지는 용도로 구분하여 DB 서버를 구성할 수 있다고 하였다. 이를 Spring data JPA와 연결하여, 읽기 작업만 존재하는 경우 slave 서버를 사용하도록 하기 위해 @Transactional(readOnly = true) 를 사용할 수 있다고 한다. 이렇게 하면 서버별 목적을 뚜렷이 구분할 수 있고, master 서버에 불필요한 조회 요청이 들어오지 않아 불필요한 트래픽을 방지할 수 있겠다.
또한 @Transactional(readOnly = true) 를 적용한 메서드에 대해서는 다른 개발자가 보더라도 해당 메서드는 DB 조회 작업만 존재한다는 것을 쉽게 알려줄 수 있다. 따라서 유지보수 시 실수로 해당 메서드 안에 DB 데이터를 조작하는 코드를 삽입하지 않도록 할 수도 있겠다.
참고) @Transactional(readOnly = true) 는 오히려 성능을 떨어트릴 수 있다.
link
카카오페이 tech의 한 글에 따르면, @Transactional(readOnly = true) 가 오히려 성능을 더 떨어트릴 수 있다고 한다. @Transactional(readOnly = true) 를 사용하면 설령 SELECT 한 건만 요청해도 set_option , commit , set session transaction등의 트랜잭션에 관한 부가적인 쿼리문들도 자동으로 생성, 요청된다고 한다. 의도치 않은 쿼리 요청까지 생성되는 것이므로, 특히 대규모 서비스의 경우 이 차이가 심해져 성능에도 영향을 끼칠 정도라고 한다. 해당 글에 따르면 이러한 부가적인 쿼리문이 6개나 새로 생성되어 DB 성능이 6배 차이가 났다고 한다. 따라서 트랜잭션의 원자성이 중요할 경우, 또는 dirty checking을 사용할 경우 등에 한해서만 @Transactional 을 사용하는 것이 성능적으로 더 좋다고 한다. 생각해보면 읽기 작업만 존재하는 경우 DB에서의 읽기 작업 자체가 기존에 존재하는 데이터의 상태를 변화시키지는 않기에 굳이 트랜잭션을 쓸 필요가 없을 것이다.
한 편 해당 글에서는 master DB와 slave DB를 구분하여 쓰고 있어 조회 요청 시에는 @Transactional(readOnly = true) 쓸 수밖에 없는데, 그러면서도 DB에 불필요한 쿼리문이 날라가는 것을 방지하기 위해 @Transactional(readOnly = true, propagation = Propagation.SUPPORTS) 속성을 사용하여 자동으로 트랜잭션이 생성되지 않도록 방지하고, 앞서 보았듯 Spring data JPA에서 제공하는 SimpleJpaRepository 에는 findById() 와 같은 조회 메서드들에도 @Transactional(readOnly = true) 자동으로 적용되어 있기에 조회 목적으로 자주 사용되는 findById() 등의 메서드를 따로 QueryDSL 또는 JPQL을 이용하여 오버라이드하여 이 문제를 해결하였다고 한다.
query method에서의 @Transactional
앞서 Spring data JPA에서의 repository에서 기본으로 제공하는 메서드들(save() 등)에는 기본적으로 @Transactional 이 부여되어 있다고 하였다. 그러나 개발자가 쿼리 메서드 네이밍 규칙에 따라 새로운 메서드를 repository 내에 정의하는 경우에는 기본적으로 해당 메서드에 @Transactional 이 부여되지 않는다고 한다. 따라서 직접 정의한 쿼리 메서드가 트랜잭션의 형태로 작동하길 원한다면 별도로 @Transational 을 부여해야한다.
@Transactional(readOnly = true)
interface UserRepository extends JpaRepository<User, Long> {
List<User> findByLastname(String lastname);
@Modifying
@Transactional
@Query("delete from User u where u.active = false")
void deleteInactiveUsers();
}
코드 4-1. repository의 사용자 정의 쿼리 메서드(deleteInactiveUsers())에 @Transactional 이 부여된 예시 코드. 코드 출처: “spring.io - Transactionality - Transactional query methods”
한 편 repository 내의 메서드들은 기본적으로 SELECT 작업으로 인식하기에, 위 코드에서처럼 만약 DELETE, INSERT 등 DB 내 데이터 값을 조작하는 DML에 해당하는 메서드일 경우, 해당 메서드에 @Modifying 을 부여하여 해당 메서드가 SELECT 목적의 메서드가 아님을 선언하면 된다. 그러면 해당 메서드는 @Transactional(readOnly = false) 가 되는 효과를 본다.
@Transactional 의 전파(Propagation)
본래 transaction이란 개념은 DB에 존재하는 개념으로, DB에서 COMMIT, ROLLBACK 등의 TCL 언어를 이용하여 하나의 transaction을 만들고 상황에 따라 COMMIT, ROLLBACK 등을 하여 transaction을 종료시킨다.
이러한 transaction은 백엔드 애플리케이션과 만나면서 DB 연동을 위해 DB connection이 생기고 그 안에서 실행된다. 이러한 구조로 인해 DB connection 객체에 의해 transaction의 시작과 끝3이 결정된다. 즉, 거꾸로 말하자면, 하나의 transaction이 실행 중이라면 이는 곧 해당 transaction이 하나의 DB connection을 차지하여 사용하고 있다는 뜻이다.
한 편, 앞서 보았듯, Spring 내에서도 JPA 등을 이용하여 별도의 transaction을 관리하고 있음을 알 수 있다. @Transactional 을 이용하여 메서드 단위로 하나의 transaction으로 묶을 수 있으며, 서비스 메서드에 적용된 외부 transaction과 그 안에 repository 수준으로 적용된 transaction을 가지는 메서드(save(), findById() 등)가 호출되는 방식을 앞서 살펴보았었다. 이 구조에서는 서비스 메서드 수준에 적용된 transaction은 외부 transaction, 그 서비스 메서드 내부에서 호출되고 있는 repository에 정의된 메서드들에 적용된 transaction은 내부 transaction이라 할 수 있다.
실제 DB에서의 transaction과는 달리 Spring을 이용한 JPA에서는 말 그대로 JPA 관련 개념들이 엮여있기도 해서, 실제 DB에서의 transaction을 물리적(physical) transaction, JPA 수준에서 존재하는 transaction을 논리적(logical) transaction이라고 별도로 구분해서 부른다.
하나의 물리적 transaction안에는 여러 개의 논리적 transaction들이 포함될 수 있으며, 앞서 말했듯 논리적 transaction에서는 하나의 외부 transaction이 한 개 이상의 여러 내부 transaction들을 포함시킬 수도 있다. 그리고 하나의 물리적 transaction 내부에 존재하는 모든 논리적 transaction들이 모두 commit되어야만 물리적 transaction이 commit될 수 있어 이 경우에만 실제로 변경된 데이터가 DB에 영구적으로 반영된다고 한다.
한 편, 논리적 transaction에서는 이미 외부 transaction이 존재하고 그 안에서 내부 transaction이 실행될 때 설정에 따라 이 둘의 관계를 다르게 설정할 수 있다. 만약 외부 transaction이 이미 존재한다면 내부 transaction은 이 외부 transaction에 포함되어 실행하게끔 할 수도 있고, 반대로 외부의 논리적 transaction이 참여하고 있는 물리적 transaction과는 별개의 물리적 transaction을 만들어서 각 논리적 transaction들이 독립적으로 운영되게끔 할 수도 있다. 이렇게 외부와 내부 논리적 transaction들 간의 관계 설정 방식, 즉 둘 이상의 논리적 transaction 간의 주고받는 영향, 또는 transaction 진행 방법을 어떻게 할 것인지 결정하는 것을 트랜잭션 전파(transaction propagation)라 한다.
org.springframework.transaction.annotation 의 @Transactional 코드를 잠시 보면 propagation 이라는 속성이 존재하며, 이 속성값에서는 Propagation 이라는 enum 클래스가 존재한다.
public enum Propagation {
REQUIRED(TransactionDefinition.PROPAGATION_REQUIRED),
SUPPORTS(TransactionDefinition.PROPAGATION_SUPPORTS),
MANDATORY(TransactionDefinition.PROPAGATION_MANDATORY),
REQUIRES_NEW(TransactionDefinition.PROPAGATION_REQUIRES_NEW),
NOT_SUPPORTED(TransactionDefinition.PROPAGATION_NOT_SUPPORTED),
NEVER(TransactionDefinition.PROPAGATION_NEVER),
NESTED(TransactionDefinition.PROPAGATION_NESTED);
private final int value;
Propagation(int value) {
this.value = value;
}
public int value() {
return this.value;
}
}
코드 5-1. org.springframework.transaction.annotation 의 Propagation.java 코드
해당 스프링 코드에 달려있는 주석에 따르면 각 전파 속성값들에 대한 설명은 다음과 같다.
REQUIRED: 만약 현재 transaction이 존재하면 해당 transaction에 참여하며, 만약 현재 진행되고 있는 transaction이 없다면 새로 하나 만든다. 우리가@Transactional을 사용하면 기본적으로@Transactional(propagation = REQUIRED)로 설정되어 있다.SUPPORTS: 현재 진행되는 transaction이 있다면 해당 transaction에 참여하고, 만약 현재 진행되고 있는 transaction이 없다면 transaction 없이 작업을 진행한다. transaction이 있건 없건 상관없이 작업을 진행한다는 측면에서는 가장 유연한 옵션이라고 볼 수 있겠다.MANDATORY: 현재 진행되고 있는 transaction이 있다면 해당 transaction에 참여하고, 그런 transaction이 없다면 예외를 발생시킨다. transaction이 반드시 존재하도록 강제해야할 때 쓸 수 있는 옵션.REQUIRED_NEW: 무조건 새로운 transaction을 하나 만들고, 기존에 진행 중이던 transaction을 중단시킨다.NOT_SUPPORTED: 작업을 transaction 없이 진행하며, 이미 현재 진행되고 있는 transaction이 있더라도 이를 중단시킨다.NEVER: 현재 작업을 transaction 없이 진행하며, 현재 진행중인 transaction이 있다면 예외를 내보낸다.MANDATORY와는 반대로 작업 진행 시 transaction이 반드시 없어야할 때 쓸 수 있겠다.NESTED: 현재 진행중인 transaction이 있다면 그 안에 중첩 transaction으로 실행시킨다.
위 속성들 중 그 자세한 원리가 잘 알려진 속성값들로는 REQUIRED, REQUIRED_NEW, NESTED 가 있다.
REQUIRED 속성을 사용하면 하나의 물리적 transaction안에 둘 이상의 논리적 transaction들을 포함시킬 수 있다. 이 속성값을 쓰면 외부의 논리적 transaction이 적용된 메서드 내부에서 또 다른 논리적 transaction이 적용된 하위 메서드를 호출할 경우 이 내부 transaction이 외부 transaction과 같은 물리적 transaction 안으로 포함되는 구조이다. 물리적 transaction은 이 내부에 있는 모든 내외부 transaction들이 commit되어야 비로소 commit이 되어 최종적으로 DB에 변경사항이 영구적으로 저장되는 구조이다.
이러한 구조로 인해 한 가지 주의할 점이 있는데, 내부 transaction들 중 단 하나라도 rollback된다면 이는 외부 transaction의 입장에서는 commit을 기대했으나 예기치 않은 상황이 발생한 것이기에 이 경우 UnexpectedRollbackException 예외가 발생한다는 것이다. 그리고 이 경우 결국 모든 transaction들이 연달아 rollback된다.
REQUIRED_NEW 속성값을 사용하면 외부 논리적 transaction과 내부 논리적 transaction이 서로 별개의 물리적 transaction을 사용하게 된다. 따라서 이 경우 내부 논리적 transaction에서 rollback이 일어난다고 해서 외부 논리적 transaction에서도 rollback이 일어나진 않는다. 두 논리적 transaction 간의 독립성이 중요할 때 사용하면 좋을 것 같다.
하지만 하나의 새로운 물리적 transaction을 별도로 만든다는 것은 그만큼 DB connection 객체가 하나 더 필요하다는 것이다. 따라서 DBCP(DB connection pool), 즉 달리 말해 DB 연결 자원을 그만큼 더 빨리 소모시킬 수 있기에 충분한 connection pool size를 확보하든가, 아니면 컴퓨팅 자원이 한정되어 있을 경우 이 속성값을 쓰는 것을 신중하게 고려해볼 필요가 있다.
또한, 여러 개의 스레드들이 외부 논리적 transaction에 대한 접근 권한을 가지고 있는 상태에서 내부 논리적 transaction에 대한 새로운 접근을 대기하는 경우 deadlock이 생길 수도 있음에 주의해야한다.
NESTED 속성값을 사용할 경우, 앞서 두 논리적 transaction들이 서로 하나의 transaction으로 중첩되어 진행된다고 하는데, 실제로는 하나의 물리적 transaction 안에 중첩되는 논리적 transaction만큼 여러 개의 savepoint들을 지정하여 사용하는 방식이다. 이로 인해 내부 논리적 transaction이 설령 rollback되더라도 외부 논리적 transaction은 중단되지 않고 계속 진행할 수 있다. 다만 이 속성값은 JDBC를 연결하여 사용할 때에만 사용할 수 있다고 한다.
앞서 살펴본 transaction 전파 속성값 중 REQUIRED 와 REQUIRED_NEW 속성값의 원리를 아래 코드와 그림을 통해 다시 살펴보자.
@Transactional // logical transaction 1 (outer)
public void serviceMethod(...) {
ARepository.findById(...); // logical transaction 2 (inner)
BRepository.save(...); // logical transaction 3 (inner)
}
코드 5-2. 서비스 메서드에서 repository에 정의된 메서드들을 호출하는 예시 코드. 위 코드에서 사용된 findById(...) , save(...) 등의 메서드에는 @Transactional 이 부여되어 있다고 가정. 이 코드에서의 모든 transaction 전파 속성값이 같다고 가정.
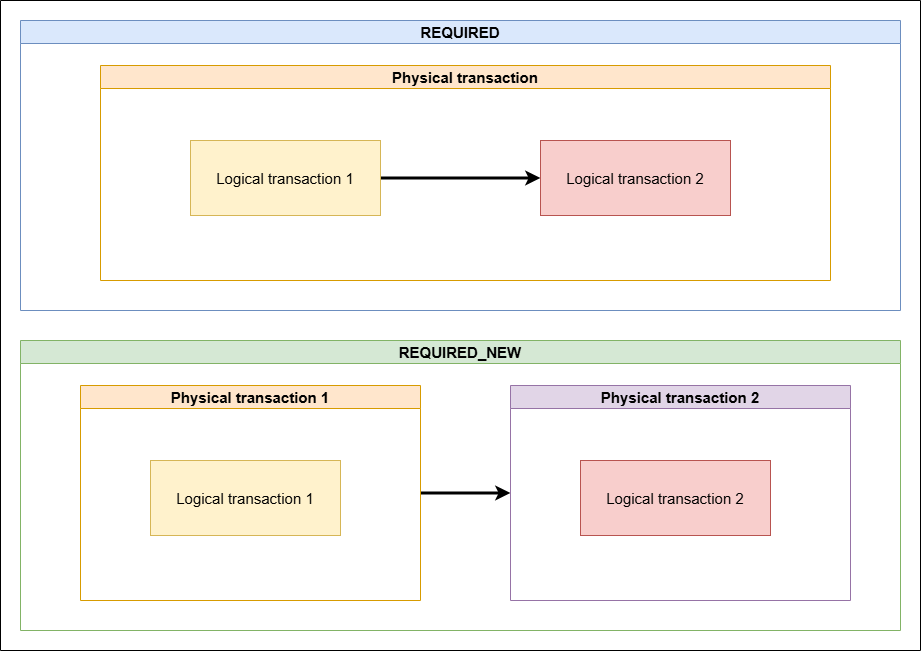
그림 1-2. 트랜잭션 전파 속성값의 REQUIRED 및 REQUIRED_NEW 속성값에 대한 각각의 트랜잭션 구조.
만약 위 코드에서 전파 속성이 REQUIRED 인 경우, 각각의 repository 메서드에 해당하는 내부 논리적 transaction들은 바깥의 서비스 메서드에 해당하는 외부 논리적 transaction에 포함되어 순차적으로 처리된다. 이 모든 논리적 transaction들은 모두 하나의 물리적 transaction 안에 존재하며, 외부 또는 내부 논리적 transaction들 중 하나라도 rollback 처리가 된다면 물리적 transaction까지 모두 rollback된다.
만약 위 코드의 전파 속성이 REQUIRED_NEW 인 경우, 외부 논리적 transaction과, 내부 각각의 repository 메서드들에 대한 각 논리적 transaction들이 각자 하나씩 물리적 transaction들을 가지게 된다. 서비스 메서드의 내부 repository 메서드가 호출될 때, 서비스 메서드에 해당하는 외부 transaction은 일시 중단되고, 내부의 repository 메서드 수준의 transaction이 새로 생성되어 해당 작업이 진행되는 구조이다. 각 transaction 모두 각자의 물리적 transaction 내에 있으므로, 내부 transaction에서 rollback이 일어난다고 해서 외부 transaction에 영향을 끼치진 않는다.
참고: jakarta와 spring 진영의 @Transactional
link
참고로 @Transactional 어노테이션은 jakarta.transaction 라이브러리와 org.springframework.transaction.annotation 라이브러리에도 동일한 이름으로 존재한다.
jakarta에서의 @Transactional 어노테이션은 주로 Jakarta EE(구 Java EE) 표준의 일부 스펙으로, JTA(Java Transactional API) 기반 transaction을 지원한다. 특정 프레임워크에 종속되지 않는다는 점도 특징이다. 다만 spring 진영의 @Transactional 에 비해 추가적인 고급 옵션들(readOnly, timeout 등)이 부재해 있다.
반면 Spring 진영의 @Transactional 에는 transation 관련 고급 옵션들을 설정해줄 수 있으며, JTA만 지원하는 Jakarta에 비해 JPA, JDBC 등 더 다양한 transaction 관리자들에 대해서도 사용할 수 있다. 스프링 AOP 기반으로 구현되어 있으며, Spring 또는 Spring Boot로 개발한다면 일관성을 위해서라도 이 라이브러리를 사용하는 것이 좋다고 한다.
References
[1] [Spring/JPA] @Transactional을 사용하는 이유에 대하여 (부제. JPA Dirty Checking)
[2] @Transactional spring JPA .save() not necessary?
[3] JPA Update 과정과 Dirty Checking (feat. @Transaction)
[4] [JPA] @Transactional과 JPA의 플러시와 변경 감지(Dirty Checking)
[5] spring 공식 문서 - transactional
Transactionality :: Spring Data JPA
[6] dirty check의 transaction 내 수행 위치.
@Transient 어노테이션과 영속성 컨텍스트 (2) - 분석편
[7] hibernate - DefaultFlushEntityEventListener#onFlushEntity() 메서드에서 dirty checking이 일어남을 볼 수 있음(Line 124).
[8] hibernate - SessionImpl#beforeTransactionCompletion() 메서드에서 transaction 커밋 전에 flush됨을 확인할 수 있음(Line 2000).
[9] [Spring / TIL] @Transactional(readOnly=true) 가 꼭 필요한가?
[10] kakaopay - JPA transactional에 관한 내용.
JPA Transactional 잘 알고 쓰고 계신가요? | 카카오페이 기술 블로그
[11] jakarta vs spring transactional
[TIL] jakarta vs springframework Transactional
[12] jakarta vs spring transactional
jakarta.transaction.Transactional vs org.springframework.transaction.annotation.Transactional
[13] 스프링 공식 문서 - transaction에 대한 문서들
Transaction Management :: Spring Framework
[14] 스프링 공식 문서 - transaction propagation
Transaction Propagation :: Spring Framework
[15] transaction propagation
[Spring] 스프링의 트랜잭션 전파 속성(Transaction propagation) 완벽하게 이해하기
-
물론 만약 영속 상태에 놓이지 않은 엔티티 객체라면 dirty checking을 사용할 수 없기에 이 경우엔
save()를 사용해야 한다. ↩ -
“기본적으로” 란 말을 붙인 이유는,
@Transactional(propagation = ...)의propagation속성에 여러 다른 속성값을 지정해줄 수 있는데, 이 속성값에 따라 트랜잭션 행위가 달라지기 때문이다. 이에 대한 자세한 사항은 아래에 기술할 “@Transactional의 전파” 챕터 내용 참고. ↩ -
달리 말하면 하나의 DB connection 객체가 시작되고 끝나기까지 그 안에서 transaction의 생명주기가 진행된다는 것이다. ↩
This content is licensed under
CC BY-NC 4.0
![]()
![]()
![]()

댓글남기기