[Forklog] Spring Data JPA에서 몰랐던 부분 되돌아보기
이번 시간에는 Forklog 라는 팀 프로젝트를 하면서 이전에는 몰랐던 Spring Data JPA에 대한 여러 사실들을 정리해보고자 한다. 이 글에서 보일 코드들은 대부분 팀 프로젝트에서 그대로 쓰인 코드가 아니라 이를 따로 재현한 코드임을 미리 알린다.
아래에 기술된 모든 코드들의 전체 소스 코드는 다음의 깃허브 레포지토리에서 확인 가능.
Entity 간 연관 관계 존재 시 데이터 다루기
이전 글인 [Forklog] ERD 설계 - 생각보다 어렵고 헷갈렸던 DB 설계 에서 다룬 도로명 주소 3개의 테이블에 대해 다루겠다.
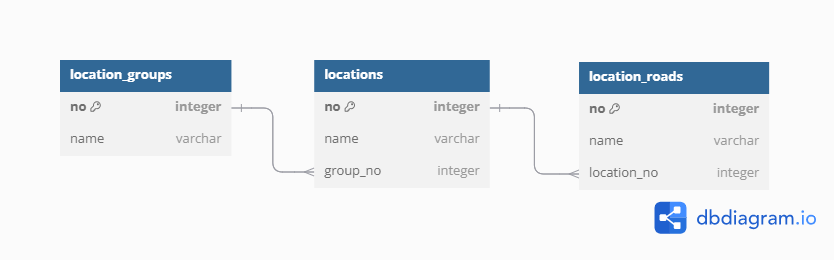
사진 1-1. 도로명 주소를 각각 대분류, 중분류, 도로명으로 나눈 3개의 테이블.
그리고 Spring Data JPA에서 이 각각의 테이블과 매핑될 엔티티 클래스 코드는 각각 다음과 같다.
package com.jerocaller.entity;
import java.util.List;
import jakarta.persistence.CascadeType;
import jakarta.persistence.Column;
import jakarta.persistence.Entity;
import jakarta.persistence.GeneratedValue;
import jakarta.persistence.GenerationType;
import jakarta.persistence.Id;
import jakarta.persistence.OneToMany;
import jakarta.persistence.Table;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Getter;
import lombok.NoArgsConstructor;
/**
* 도로명 주소의 대분류를 표현하는 엔티티.
*
* 예) 서울, 경기 등
*/
@Entity
@Table(name = "location_groups")
@Getter
@NoArgsConstructor
@AllArgsConstructor
@Builder
public class LocationGroups {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(nullable = false, length = 11)
private Integer no;
@Column(nullable = false, length = 50)
private String name;
/*
@OneToMany(mappedBy = "groups", cascade = CascadeType.ALL)
private List<Locations> locations;
*/
}
코드 1-1. LocationGroups.java 도로명 주소의 대분류를 표현하는 엔티티
package com.jerocaller.entity;
import java.util.List;
import jakarta.persistence.CascadeType;
import jakarta.persistence.Column;
import jakarta.persistence.Entity;
import jakarta.persistence.GeneratedValue;
import jakarta.persistence.GenerationType;
import jakarta.persistence.Id;
import jakarta.persistence.JoinColumn;
import jakarta.persistence.ManyToOne;
import jakarta.persistence.OneToMany;
import jakarta.persistence.Table;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Getter;
import lombok.NoArgsConstructor;
/**
* 도로명 주소의 중분류를 표현하는 엔티티
*
* 예) 강남구, 평택시 등등
*/
@Entity
@Table(name = "locations")
@Getter
@NoArgsConstructor
@AllArgsConstructor
@Builder
public class Locations {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(nullable = false, length = 11)
private Integer no;
@Column(nullable = false, length = 50)
private String name;
//@ManyToOne(cascade = CascadeType.PERSIST)
@ManyToOne
@JoinColumn(name = "group_no", nullable = false)
private LocationGroups groups;
/*
@OneToMany(mappedBy = "locations", cascade = CascadeType.ALL)
private List<LocationRoads> roads;
*/
}
코드 1-2. Locations.java 도로명 주소의 중분류를 표현하는 엔티티
package com.jerocaller.entity;
import jakarta.persistence.CascadeType;
import jakarta.persistence.Column;
import jakarta.persistence.Entity;
import jakarta.persistence.GeneratedValue;
import jakarta.persistence.GenerationType;
import jakarta.persistence.Id;
import jakarta.persistence.JoinColumn;
import jakarta.persistence.ManyToOne;
import jakarta.persistence.Table;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Getter;
import lombok.NoArgsConstructor;
/**
* 도로명 주소 중 도로명을 표현하는 엔티티
*
* 예) XX대로
*/
@Entity
@Table(name = "location_roads")
@Getter
@NoArgsConstructor
@AllArgsConstructor
@Builder
public class LocationRoads {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(nullable = false, length = 11)
private Integer no;
@Column(nullable = false, length = 50)
private String name;
//@ManyToOne(cascade = CascadeType.PERSIST)
@ManyToOne
@JoinColumn(name = "location_no", nullable = false)
private Locations locations;
}
코드 1-3. LocationRoads.java 도로명 주소의 도로명을 표현하는 엔티티
데이터 삽입
이전 글 [Forklog] ERD 설계 - 생각보다 어렵고 헷갈렸던 DB 설계 에서는 위에서 언급한 도로명 주소 관련 3개의 테이블 구조에 대해, 새로운 주소 데이터를 삽입하려고 했으나 실패했었다는 것을 언급한 적이 있다. 여기서는 그 이유와 해결책에 대해 살펴보겠다. 다음은 Service 계층에 포함된 LocationProcess라는 클래스 내부의 한 메서드 코드이다.
/**
* 주어진 도로명 주소 대분류, 중분류, 도로명 정보를 DB에 저장.
*
* @param requestDto
*/
@Transactional
public void insertLocationWrong(LocationRequest requestDto) {
LocationGroups groups = locationGroupsRepository
.findByName(requestDto.getLarge())
.orElse(
LocationGroups.builder()
//.no(getNextId(KindOfLocation.LARGE))
.name(requestDto.getLarge())
.build()
);
// 엔티티에 cascade 영속성 전이를 설정하더라도 종속 엔티티(여기선 groups)가
// DB 내에 존재하지 않을 경우 종속 엔티티 자체를 주인 엔티티 조회 조건으로 사용할 수 없다.
// 그래서 영속성 전이를 설정하더라도 에러는 여전히 뜬다.
// 참고로 굳이 종속 엔티티까지를 주인 엔티티의 조회 조건으로 사용한 이유는
// 하위 분류에 해당하는 주소명이 겹칠 수도 있기에 (예 - 경기도 "광주", 전라도 "광주")
// 이에 대한 혼선을 줄이고 정확한 작업을 하기 위함.
Locations locations = locationsRepository
.findByNameAndGroups(requestDto.getMiddle(), groups)
.orElse(
Locations.builder()
//.no(getNextId(KindOfLocation.MIDDLE))
.name(requestDto.getMiddle())
.groups(groups)
.build()
);
Optional<LocationRoads> roadsOpt = locationRoadsRepository
.findByNameAndLocations(requestDto.getRoad(), locations);
if (roadsOpt.isEmpty()) {
LocationRoads roads = LocationRoads.builder()
//.no(getNextId(KindOfLocation.ROAD))
.name(requestDto.getRoad())
.locations(locations)
.build();
locationRoadsRepository.save(roads);
log.info("새 도로명 주소 데이터 삽입 완료");
} else {
log.info("이미 DB에 해당 데이터가 존재하므로 삽입 작업은 일어나지 않았습니다.");
}
}
코드 2-1. LocationProcess.insertLocationWrong
위 코드는 방금 언급한 이전 글의 “예제 2-1”과 로직은 거의 같으나 조금 더 안정적으로 만든 코드이다. 3개의 테이블에 새 데이터를 삽입할 때 대분류, 중분류, 도로명 모두 DB에 없어서 셋 다 삽입할 경우도 있고, 상위 분류에는 데이터가 존재하나 하위 분류에 데이터가 없어 이를 새로 삽입할 때도 있을 거라 생각하여 이를 상정하고 코드를 작성한 것이다. 그래서 만약 세 분류 모두 데이터가 없는 경우 각각에 해당하는 엔티티 객체를 생성하고 하위 분류 엔티티가 상위 분류 엔티티를 포함시키는 구조를 이루고 있다. 최하위 분류인 도로명 엔티티(LocationRoads)가 결국에는 상위 모든 엔티티를 포함시키고, save() 메서드에 의해 영속화되는 구조를 띠고 있다. 그런데 위 코드는 다음의 에러를 일으킨다.
org.hibernate.TransientObjectException: object references an unsaved transient instance - save the transient instance before flushing
위 코드를 다시 살펴보면, LocationRoads 엔티티는 save() 를 거치지만, 각각 대분류, 중분류에 해당하는 LocationGroups, Locations 엔티티는 새로 생성될 경우 따로 save() 메서드를 통해 영속화되는 과정을 거치지 않고 있기 때문이다. LocationRoads 엔티티에는 FK 필드를 채워야 하는데, 이에 해당하는 Locations 객체가 미리 영속화되어 있지 않기에 발생한 문제이다. 이에 대한 해결책은 두 가지 정도가 있다. 하나는 상위 엔티티인 LocationGroups, Locations에 대해서도 save() 메서드를 통해 영속화시키는 코드를 추가하는 것이고, 또 하나는 cascade, 즉 영속성 전이를 설정하는 방법이다.
먼저, save() 메서드, 즉 비영속 엔티티 객체를 영속화시키는 코드를 추가하는 방법이다.
@Transactional
public void insertLocationTwo(LocationRequest requestDto) {
LocationGroups groups = null;
Optional<LocationGroups> groupsOpt = locationGroupsRepository
.findByName(requestDto.getLarge());
if (groupsOpt.isEmpty()) {
groups = locationGroupsRepository.save(
LocationGroups.builder()
//.no(getNextId(KindOfLocation.LARGE))
.name(requestDto.getLarge())
.build()
);
} else {
groups = groupsOpt.get();
}
Locations locations = null;
Optional<Locations> locationsOpt = locationsRepository
.findByNameAndGroups(requestDto.getMiddle(), groups);
if (locationsOpt.isEmpty()) {
locations = locationsRepository.save(
Locations.builder()
//.no(getNextId(KindOfLocation.MIDDLE))
.name(requestDto.getMiddle())
.groups(groups)
.build()
);
} else {
locations = locationsOpt.get();
}
LocationRoads roads = null;
Optional<LocationRoads> roadsOpt = locationRoadsRepository
.findByNameAndLocations(requestDto.getRoad(), locations);
if (roadsOpt.isEmpty()) {
roads = locationRoadsRepository.save(
LocationRoads.builder()
//.no(getNextId(KindOfLocation.ROAD))
.name(requestDto.getRoad())
.locations(locations)
.build()
);
} else {
roads = roadsOpt.get();
}
}
코드 2-2. LocationProcess.insertLocationTwo
위와 같이 대분류, 중분류 엔티티에 대해서도 save() 메서드를 호출하여 비영속 객체를 영속화시키면 된다. 그러면 에러 없이 데이터를 삽입할 수 있게 된다.
cascade - 영속성 전이
또 다른 방법은 “영속성 전이”를 사용하는 방법이다. 둘 이상의 서로 연관된 엔티티들이 존재할 때, 각각의 엔티티에 대해 일일이 save() 메서드 호출하여 영속화할 필요 없이, 하나의 엔티티만 영속화되어도 연관된 나머지 엔티티들도 자동으로 영속화되는 방법이다. 이는 엔티티 클래스에서 @ManyToOne, @OneToOne 등 연관관계를 지어주는 어노테이션의 속성 중 하나인 cascade 속성에 CascadeType.PERSIST 또는 CascadeType.ALL 을 지정하면 된다. 다음은 이를 적용한 엔티티 클래스 코드이다.
package com.jerocaller.entity;
import java.util.List;
import jakarta.persistence.CascadeType;
import jakarta.persistence.Column;
import jakarta.persistence.Entity;
import jakarta.persistence.GeneratedValue;
import jakarta.persistence.GenerationType;
import jakarta.persistence.Id;
import jakarta.persistence.JoinColumn;
import jakarta.persistence.ManyToOne;
import jakarta.persistence.OneToMany;
import jakarta.persistence.Table;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Getter;
import lombok.NoArgsConstructor;
/**
* 도로명 주소의 중분류를 표현하는 엔티티
*
* 예) 강남구, 평택시 등등
*/
@Entity
@Table(name = "locations")
@Getter
@NoArgsConstructor
@AllArgsConstructor
@Builder
public class Locations {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(nullable = false, length = 11)
private Integer no;
@Column(nullable = false, length = 50)
private String name;
@ManyToOne(cascade = CascadeType.PERSIST) // 영속성 전이
//@ManyToOne
@JoinColumn(name = "group_no", nullable = false)
private LocationGroups groups;
/*
@OneToMany(mappedBy = "locations", cascade = CascadeType.ALL)
private List<LocationRoads> roads;
*/
}
코드 2-3. Locations.java
package com.jerocaller.entity;
import jakarta.persistence.CascadeType;
import jakarta.persistence.Column;
import jakarta.persistence.Entity;
import jakarta.persistence.GeneratedValue;
import jakarta.persistence.GenerationType;
import jakarta.persistence.Id;
import jakarta.persistence.JoinColumn;
import jakarta.persistence.ManyToOne;
import jakarta.persistence.Table;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Getter;
import lombok.NoArgsConstructor;
/**
* 도로명 주소 중 도로명을 표현하는 엔티티
*
* 예) XX대로
*/
@Entity
@Table(name = "location_roads")
@Getter
@NoArgsConstructor
@AllArgsConstructor
@Builder
public class LocationRoads {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(nullable = false, length = 11)
private Integer no;
@Column(nullable = false, length = 50)
private String name;
@ManyToOne(cascade = CascadeType.PERSIST) // 영속성 전이
//@ManyToOne
@JoinColumn(name = "location_no", nullable = false)
private Locations locations;
}
코드 2-4. LocationRoads.java
cascade 속성값으로는 다음의 값들이 가능하다.
- ALL - 저장, 삭제 등의 모든 작업이 적용된다. 이는 부모, 자식 엔티티의 생명주기를 서로 맞춰야하는 경우에 사용할 수 있다.
- PERSIST : 데이터 저장 시에만 영속성 전이 적용.
- REMOVE: 데이터 삭제 시에만 영속성 전이 적용.
- MERGE, REFRESH, DETACH
여기서는 데이터 저장에 대해서만 살펴볼 것이라 PERSIST를 이용하였다.
영속성 전이 설정에 맞게 LocationProcess 클래스에 다음의 메서드를 추가하여 이 메서드를 사용하였다.
/**
* insertLocationWrong() 메서드에 대한 해결책
*
* 각 엔티티들의 ManyToOne 어노테이션 속성으로 cascade = CascadeType.PERSIST을 설정해야
* 제대로 데이터 삽입이 수행됨.
*
* @param requestDto
*/
@Transactional
public void insertLocationWrongSolution(LocationRequest requestDto) {
LocationGroups groups = locationGroupsRepository
.findByName(requestDto.getLarge())
.orElse(
LocationGroups.builder()
.name(requestDto.getLarge())
.build()
);
// 만일 위 코드에서 조회된 종속 엔티티(groups)가 없을 경우,
// 이 시점에서는 DB에 해당 종속 엔티티의 데이터가 없다는 뜻이므로
// 위에서 생성한 아직 영속성 컨텍스트에 포함되지 않은 종속 엔티티 객체를
// 주인 엔티티 조회 조건으로 사용하면 에러가 발생한다.
// 따라서 여기서는 이 문제를 우회하기 위해 대신 종속 엔티티가 대표하는
// 도로명 주소 상위 분류의 문자열 값도 같이 입력하여 상위 분류 및 현재 분류의 문자열 값
// 모두 일치하는지 여부로 주인 엔티티를 조회한다.
Locations locations = locationsRepository
.findByNames(requestDto)
.orElse(
Locations.builder()
.name(requestDto.getMiddle())
.groups(groups)
.build()
);
Optional<LocationRoads> roadsOpt = locationRoadsRepository
.findByNames(requestDto);
if (roadsOpt.isEmpty()) {
LocationRoads roads = LocationRoads.builder()
//.no(getNextId(KindOfLocation.ROAD))
.name(requestDto.getRoad())
.locations(locations)
.build();
locationRoadsRepository.save(roads);
log.info("새 도로명 주소 데이터 삽입 완료");
} else {
log.info("이미 DB에 해당 데이터가 존재하므로 삽입 작업은 일어나지 않았습니다.");
}
}
코드 2-5. LocationProcess.insertLocationWrongSolution
위와 같이 코드 작성하면 에러 없이 데이터 저장이 실행된다. 위 코드 2-5의 경우, 코드 2-2에서 그런 것처럼 FK 필드에 해당하는 종속 엔티티들을 findByName과 같이 검색 조건에 사용할 수 없다. 새로 만들어지는 종속 엔티티의 경우 locationRoadsRepository.save(roads); 코드를 만나기 전까지는 아직 영속화되지 않았기 때문이다. 따라서 위 코드 2-5에서는 대신 인자로 넘어오는 도로명 주소의 대분류, 중분류 문자열 데이터를 .findByNames(requestDto); 과 같은 형태로 검색 조건에 사용하였다.
이렇듯, 둘 이상의 연관관계를 가지는 엔티티에 대해 새로운 데이터를 삽입하고자 할 때에는 각각의 엔티티에 대해 영속화 작업을 하든가, 아니면 영속성 전이를 사용해야 한다. 그리고 비영속 객체를 사용하면 에러가 발생하니 이미 영속화된 엔티티를 조회하여 사용하든가 아니면 문자열, 숫자 등 특정 데이터를 검색 조건으로 활용해야 한다.
FK 적용된 필드를 기준으로 데이터 조회하는 방법
필자는 처음에 JPA를 접했을 때, JPQL를 다룰 때 FK 컬럼은 어떻게 다뤄야할지 몰랐었다. 그래서 테이블에 있는 FK 컬럼명을 그대로 쓰면 되는건가, 라고 생각하기도 했고, 아예 엔티티에 FK 컬럼과 매핑될 필드를 선언하면 되는건가, 란 생각도 하였다. 하지만 이 모두 틀렸었고, 그저 FK에 해당하는 종속 엔티티 객체 자체를 이용하면 되는 것을 깨달았다.
/**
* 문자열 타입으로 주어진 도로명 주소 중분류,
* Entity 형태로 주어진 도로명 주소 대분류 정보에 일치하는
* 엔티티 반환.
*
* @param name
* @param groups
* @return
*/
Optional<Locations> findByNameAndGroups(
String name,
LocationGroups groups
);
코드 3-1. LocationsRepository.java
위 코드에서처럼, JPA에서는 FK 컬럼에 해당하는 개념이 종속 엔티티이므로, groups를 직접 검색 조건에 넣으면 조회, 삽입 등의 데이터 작업이 가능하다. 물론 Service 계층에서 종속 엔티티 객체를 조회하여 얻는 작업이 선행되어야 할 것이다.
ID 자동 증가 관련 에러
예전에 Entity의 Id 필드에 @GeneratedValue(strategy = GenerationType.IDENTITY) 을 걸면 auto increment가 반영되어 새 데이터 삽입 시 id 필드에 값을 수동으로 채워넣지 않아도 되는 걸로 알고 그렇게 했는데도 “Field ‘id’ doesn’t have a default value” 이라는 에러가 뜨면서 id 필드에 값이 자동으로 삽입되지 않은 적이 있다. 그래서 그 후로 JpaRepository에서 테이블 내 최대 PK값을 가져오는 JPQL을 작성한 후, 이를 토대로 id 필드 값을 수동으로 넣곤 했다. 그런데 이번에는 “Row was updated or deleted by another transaction (or unsaved-value mapping was incorrect)” 이라는 또 다른 에러가 뜨면서 실행이 되지 않았다. 그런데 알고 보니 이 에러의 원인은 다름 아니라 id 필드에 값을 수동으로 넣으려는 시도 때문이었다. 그리고 “Field ‘id’ doesn’t have a default value” 이 에러는 알고보니 DB에 한 테이블의 PK 컬럼에 auto increment가 적용되지 않았기 때문이었다. 그래서 id 필드 값을 수동으로 넣으려는 코드는 삭제한 후, DB에서 auto increment 조건을 추가하고 나니 그제서야 데이터 삽입이 정상적으로 동작하였다.
Dirty Checking을 이용한 Update
팀 프로젝트에서, 특정 음식점 페이지 클릭 시 해당 음식점의 조회수를 1 증가시키는 기능을 개발했던 적이 있다. 이를 위해 Update 기능이 필요했다. 그리고 필자는 save() 를 이용하는 대신 Dirty Checking 방식을 이용하여 이를 구현하였다.
/**
* 특정 음식점의 조회수 1 증가 시키는 메서드.
*
* 참고)
* Dirty Checking을 이용하여 update하는 방법 사용 시에는
* 업데이트 내용을 반영하기 위해 반드시 @Transactional 어노테이션을 부여해야 함.
* 그렇지 않으면 내용이 DB에 반영되지 않음을 확인함.
*
* @param eateryNo - 음식점 엔티티 No
* @return - true 시 특정 음식점 조회수 1 증가 DB 반영 성공. false 시 입력된 no 값에
* 해당하는 음식점 데이터를 DB에서 조회하지 못함을 의미.
*/
@Transactional
public boolean addOneViewCount(int eateryNo) {
Optional<Eateries> eateryOpt = eateriesRepository
.findById(eateryNo);
if (eateryOpt.isEmpty()) return false;
Eateries eatery = eateryOpt.get();
// Dirty Checking을 이용하여 조회수 1 증가하도록 update.
// 즉, 새로운 엔티티 객체를 생성하여 repository에 save하는 방식이 아닌,
// 이미 기존 영속성 컨텍스트에 존재하는 엔티티 객체 참조를 가져와
// 해당 객체의 특정 필드값을 setter 메서드로 변경하는 방식임.
// Dirty Checking 이용 시 repository.save()를 이용하지 않아도
// 자동으로 업데이트 됨. 단 @Transactional 어노테이션을 반드시 부여해야
// 실제 DB에 업데이트된 값이 반영됨.
eatery.setViewCount(eatery.getViewCount() + 1);
return true;
}
코드 4-1. EateriesProcess.addOneViewCount
이미 영속화된 엔티티 객체를 JpaRepository를 통해 조회하여 얻은 후, 수정하고자 하는 특정 필드값을 setter 메서드를 이용하여 변경시키는 구조이다. 이미 영속화된 객체를 가져와 그 객체의 특정 필드값을 수정하는 방식이기에 그 변화를 영속성 컨텍스트에서 자동으로 감지하는 Dirty Checking이 일어나 변경사항이 자동으로 업데이트되는 방식이다. 따라서 이 방식은 굳이 엔티티 객체를 save() 메서드의 인자에 대입하여 호출할 필요가 없다.
단, 위 코드가 동작하려면 반드시 @Transactional 어노테이션을 메서드에 적용해야 한다. 그렇지 않으면 값이 변경되지 않으니 이에 주의해야 한다.
SpEL을 이용하여 JPQL의 파라미터로 자바 객체 삽입하기
/**
* 도로명 주소 대분류 및 중분류 주소명에 해당하는 Locations Entity 존재 여부 조회.
*
* @param request
* @return
*/
@Query(value = """
SELECT l
FROM Locations l
JOIN l.groups g
WHERE l.name LIKE %:#{#addr.middle}% AND
g.name LIKE %:#{#addr.large}%
""")
Optional<Locations> findByNames(@Param("addr") LocationRequest request);
코드 5-1. LocationsRepository.findByNames
위 코드에서 메서드 파라미터로 LocationRequest라는 DTO 객체를 받고 있다. 이를 JPQL에서 사용하려면 위 코드에서 보다시피 #{#...} 구문을 이용해야 한다. 즉, POJO 자체를 JPQL의 파라미터로 사용하고자 한다면 쿼리문 내에서 #{#...} 구문을 사용해야 제대로 동작한다. 처음에는 이게 무슨 구문이지? 싶었는데 알고 보니 SpEL(Spring Expression Language)의 일종이었다.
SpEL은 런타임 환경에서 객체 그래프를 조작하고 이에 대한 쿼리문 작성에 도움을 주는 표현 언어(Expression Language)라고 한다. 여기서 객체 그래프는 여러 개의 객체들이 네트워크처럼 서로 연결 관계를 가지는 객체 집합을 말한다. 이러한 객체들 간의 복잡한 참조 관계가 마치 그래프와 같이 표현할 수 있다고 해서 객체 그래프라는 이름이 붙은 것 같다. 즉, SpEL은 객체 간의 참조 관계를 다룰 때 쓰이는 언어이다. SpEL은 스프링 진영에서 사용할 수 있도록 제작된 표현 언어이지만 스프링에 독립적으로도 사용할 수 있다고 한다. SpEL에는 수많은 문법들을 제공하지만 여기서는 위에서 언급된 #{...} 와 #... 구문에 대해서만 살펴보겠다.
#{...} 구문은 Expression Template이라고 하며, 이 안에 표현 언어(EL)를 작성하면 이를 계산(evaluation)하여 그 결과값을 내놓는 구문이다. 예를 들어 #{1 + 2} 라고 하면 3 이란 결과값이 나오는 셈이다. Hello, #{ #saying.world } 처럼 리터럴 문자열과 섞어 쓸 때 이 구문을 사용할 수 있다.
#... 구문은 표현 구문 안에서 참조 변수를 참조하기 위한 구문이다. 위 코드 5-1에서, request라는 LocationRequest 타입의 객체 참조 변수를 표현 구문 안에서 참조하기 위해 #addr 와 같이 사용되었다.
즉, 종합하자면 request라는 객체 참조 변수를 표현 구문 안에서 참조하기 위해 #addr 와 같이 사용되었으며, 해당 객체의 특정 getter 메서드 호출의 결과값을 도출하기 위해 #{...} 구문 안에 작성되었다고 볼 수 있는 것이다.
References
[1] SpEL (Spring Expression Language)
Spring Expression Language (SpEL) :: Spring Framework
[2] SpEL in JPQL
SpEL support in Spring Data JPA @Query definitions
[3] JPQL의 파라미터로 DTO 클래스 받기
[4] SpEL - Variables #variable
[5] SpEL - Expression Templating #{...}
Expression Templating :: Spring Framework
[6] cascade 옵션을 이용한 영속성 전이 설정
[7] [6]과 관련됨
[8] Hibernate: “Field ‘id’ doesn’t have a default value”
Hibernate: “Field ‘id’ doesn’t have a default value”
[9] cascade 옵션을 이용한 영속성 전이 설정
TransientObjectException : save the transient instance before flushing 에러
[10] 영속성 전이에 대해
[11] 영속성 전이에 대해
[12] Object Graph
This content is licensed under
CC BY-NC 4.0
![]()
![]()
![]()

댓글남기기