[Forklog] ERD 설계 - 생각보다 어렵고 헷갈렸던 DB 설계
주제를 정한 우리 팀은 화면 설계서, 기능 정의서까지 작성하고 나서 ERD 설계에 나섰다. 페이지 별로 각자 팀원들끼리 분담하여 그 페이지에 필요한 기능들을 토대로 ERD를 구성하기로 하였다. 처음부터 사이트 전체를 고려하고 ERD를 만들 수 있으면 좋긴 하겠지만 그게 생각보다 쉽지 않을 것이고, 전체 회의까지 하면서 전체 사이트에 대한 ERD를 만들고자 하면 비효율적일 것 같아서 그렇게 한 것이다. 페이지 별로 필요한 ERD를 구성하는 게 더 쉽고, 이를 나중에 합치는 게 더 나을 것 같다는 판단에서 그렇게 하였다. Divide and Conquer 작전인 셈이다.
그러나 그 당시엔 아직까지도 우리 사이트를 제작하기 위해 적절한 Open API를 선정하지 못했었다. 어떤 Open API에서는 서울 지역의 정보만 제공해주고, 또 어떤 API에서는 전국이긴 하지만 “시티 투어” 등 특정 컨셉에 얽매여 있어 우리 사이트에 적절하지 않았었다. 또 거의 대부분 API들은 메뉴, 가격 등 세부 정보까지 제공하지 않고, 음식점 이미지에 대한 정보도 제공하지 않아 어떻게 해야할지 골치 아픈 상황이었다. 그래서 각자 페이지별 ERD를 작성하기로 했을 때 나는 그 전부터 API 조사 담당자 중 한 명이었어서 API 조사를 계속 하기로 하였다.
각자 제작한 ERD를 취합하고 났을 때, ERD는 다 끝난 줄 알았는데 팀장님이 무언가 문제를 발견하신 모양이었다. 팀 전체에 ERD 완성본 공표가 나질 않을 정도여서 “이거 생각보다 심각한 상황 아닌가”라는 생각이 들어 결국 나와 팀장님 둘이서 취합된 ERD를 살펴보기로 하였다. 그 당시엔 Kakao API를 사용하기로 가닥이 잡혀서 나도 ERD에 참여할 수 있게 되었다.
내 기억으로는 그 문제는 생각보다 빨리 해결되어서 그 이후로는 이미 취합된 ERD 상에서 어떠한 문제점은 없는지 위주로 진행되었다. 별점 리뷰 정보를 담는 review라는 테이블이 있었고, 원래 거기에는 리뷰어가 리뷰를 위한 사진을 올릴 수 있도록 고안했기에 사용자가 입력한 이미지 경로를 담는 컬럼도 있었다. 참고로 이미지 파일 자체는 서버 내에 저장하도록 하였기에 DB 상에서는 그 이미지의 서버 내 경로만 입력하도록 고안할 수 있었다. 그런데 가만히 생각해보니 하나의 별점 리뷰에 리뷰어가 사진을 한 장도 아닌 여러 장을 입력할 수 있도록 이미 화면설계서에서 고안했는데, 정작 ERD 상에서는 review라는 단 하나의 테이블만 운용하는 게 이상했다. 이렇게 되면 한 명의 리뷰어가 여러 사진을 올릴 경우 review라는 테이블에 그 여러 사진의 경로를 담기 위해서 다른 별점 리뷰 정보(누가 올렸는지 회원의 정보, 댓글 내용, 별점 등등)들까지도 하나의 레코드로 구성해야 했다. 이는 명백한 중복이었다. 여러 사진을 위해 중복되는 다른 데이터까지도 담아야하는 것은 너무나 비효율적인 구조이다. 예를 들면 다음의 구조인 것이다.
| 회원 번호 | 별점 | 리뷰 내용 | 이미지 경로 |
|---|---|---|---|
| 1 | 4.0 | 좋아요 | /uploads/review/1/image1.png |
| 2 | 5.0 | 또 가고 싶어요! | /uploads/review/2/image1.png |
| 2 | 5.0 | 또 가고 싶어요! | /uploads/review/2/image2.png |
| 2 | 5.0 | 또 가고 싶어요! | /uploads/review/2/image3.png |
위와 같이 중복되는 데이터들이 많아지면 쓸데없이 DB의 용량이 불어나고, 이는 검색 성능의 문제로도 이어질 수 있다고 생각하였다. 그래서 나는 이를 두 개의 테이블로 분류하자고 제안하였고, 기존의 review 테이블은 놔두되, 이미지 정보만을 따로 담은 review_images 테이블을 제안하였다. 즉 다음의 구조와 같이 말이다.
| 회원 번호 | 별점 | 리뷰 내용 |
|---|---|---|
| 1 | 4.0 | 좋아요 |
| 2 | 5.0 | 또 가고 싶어요! |
| 회원 번호 | 이미지 경로 |
|---|---|
| 1 | /uploads/review/1/image1.png |
| 2 | /uploads/review/2/image1.png |
| 2 | /uploads/review/2/image2.png |
| 2 | /uploads/review/2/image3.png |
위쪽이 review, 아래쪽이 review_images 테이블 예시이다.
이렇게 다시 ERD를 검토해보니 위와 같은 몇몇 문제점들을 확인할 수 있어서 미리 해결할 수 있었다. 다른 건 몰라도 ERD는 굉장히 신중히 해야 했는데, 우리 팀은 Spring Data JPA라는 ORM(Object Relational Mapping)의 일종을 사용하기로 했기에 특히나 ERD 구조에 신경을 쓸 수밖에 없었다. 만약 자바로 코드를 작성하다가 ERD 설계에 문제가 있음을 알아차렸다면 그제서야 ERD 구조를 바꿔야 하는데 그러면 자바 코드 내에서 Entity와 Entity 간의 관계들도 바뀌어야하는 대공사를 치뤄야 하기 때문이다.
아무튼 이렇게 또 한 번 검토해보는 시간을 가져서 다행이라는 생각이 들었지만, 오히려 여기서 내가 실수했던 부분도 있었다.
도로명 주소에 대한 ERD 설계
사이트 회원이 처음 회원 가입할 때 거주지 주소를 입력하도록 되어 있었다. 이는 사용자 거주지 주소 기반으로 음식점 추천을 하기 위함이었다. 또한 음식점 정보를 DB에 저장할 때에도 음식점의 주소 정보도 들어가야 했다. 이렇게 서로 별개의 테이블에서 주소라는 똑같은 컬럼이 나타나는 것에 주목한 나는 차라리 주소에 해당하는 locations이라는 테이블을 별도로 생성하고, 회원 테이블과 음식점 테이블에서 이를 참고하는 게 더 낫지 않을까, 란 생각이 들었다. 여기에 더 나아가 나는 다음의 문제점도 발견했었다.
| 음식점명 | 도로명주소 |
|---|---|
| 맛나치킨 | 서울 강남구 XX대로 |
| 김밥마시써 | 서울 강남구 OO대로 |
즉, 주소를 보면 “서울 강남구”까지 겹치는 것을 볼 수 있다. 위와 같이 데이터가 2개여서 그렇지, 데이터가 수백, 수천 건이 된다면 이러한 중복 문제가 끊임없이 발생할 것이라 생각하였다. 나는 이게 제 1정규화와 굉장히 유사하다고 생각하였다. 즉, 원자성을 제대로 만족시키지 못한다고 생각하였다. 그래서 나는 이 부분에 대해서 주소라는 별도의 테이블을 생성할 것과, 주소 내에서도 “서울”이라는 대분류, “강남구”라는 중분류, “XX대로”라는 도로명 주소로 구분하여 총 3개의 주소 관련 테이블을 생성할 것을 제안하였다.
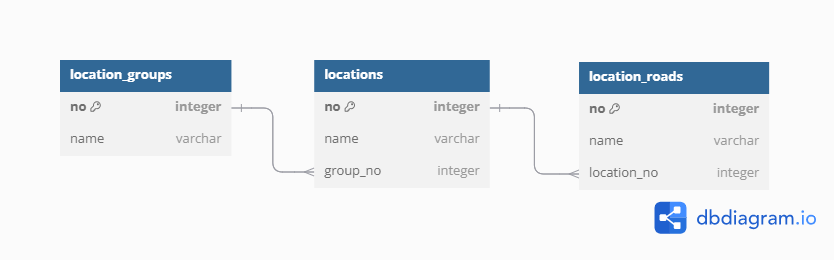
사진 1-1. 지역 주소 테이블 3개를 ERD로 재현해보았다.
location_groups가 주소의 대분류에 해당하고, locations는 중분류, location_roads는 도로명을 담는 테이블이다.
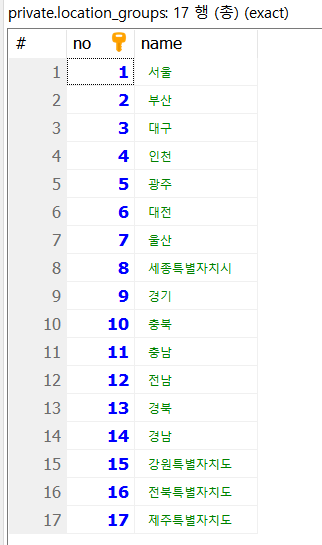
사진 1-2. 주소 대분류에 해당하는 테이블
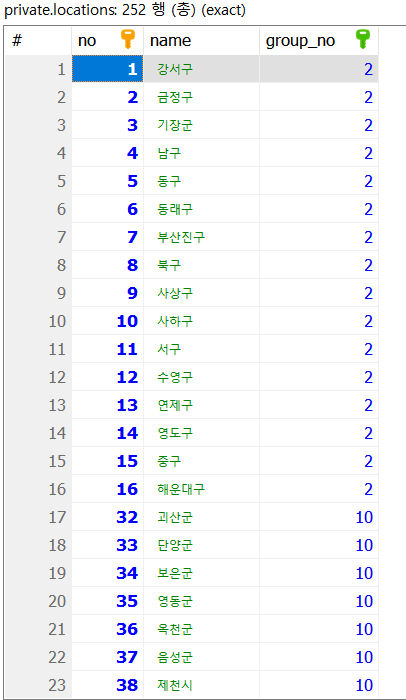
사진 1-3. 주소 중분류에 해당하는테이블
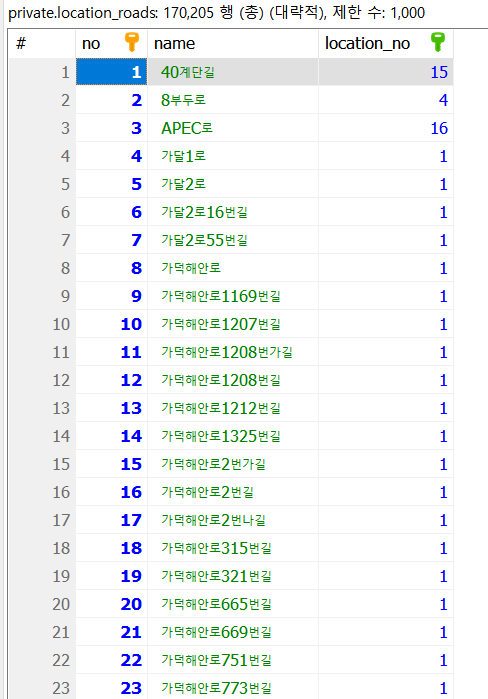
사진 1-4. 주소의 도로명에 해당하는 테이블
논의 끝에 주소 데이터는 미리 DB에 존재하는 게 더 나을 것 같다는 결정이 내려졌고, 나는 행정안전부에서 제공하는 전국 도로명 주소 데이터 CSV 파일을 이용하여 이 데이터들을 위 세 테이블에 넣었다. (References의 [2] 참고) 사실 이 과정에서 대용량(전국 데이터를 제공했는데, 합치면 아마 3, 4백만 개인 것으로 추정된다)의 CSV 파일 내 데이터들을 잘 가공하여 DB 내 테이블에 넣는 것도 시간이 걸리기도 하였다. 행안부에서 제공하는 CSV 파일 내 구조와 내가 제안한 위 세 테이블의 구조가 엄연히 달랐기에 CSV 파일 내 데이터를 기존 세 테이블에 삽입하는 쿼리문을 작성하였는데, 이 과정에서 생각보다 여러 개의 쿼리문들이 쓰였고, 쿼리문 하나하나 세우는 것도 쉽지 않았다. 이에 대한 자세한 과정은 별도의 글에서 다뤄보도록 하겠다.
어쨌거나 위와 같이 구성함으로써 다음의 장점들을 얻을 수 있을거라 생각했다.
- 회원 및 음식점에서 공통적으로 나타나는 주소를 별도의 테이블로 운영함으로써 데이터 중복 문제를 해결할 수 있다.
- 사이트 구현 시 지역별 검색을 위해 “서울” 과 같이 지역 주소의 대분류만, 또는 중분류만 분리해서 따로 다룰 필요가 있었다. 이럴 때 이미 주소 관련 테이블을 세 개로 나눴기에 원하는 데이터만 바로 추출할 수 있게 된다.
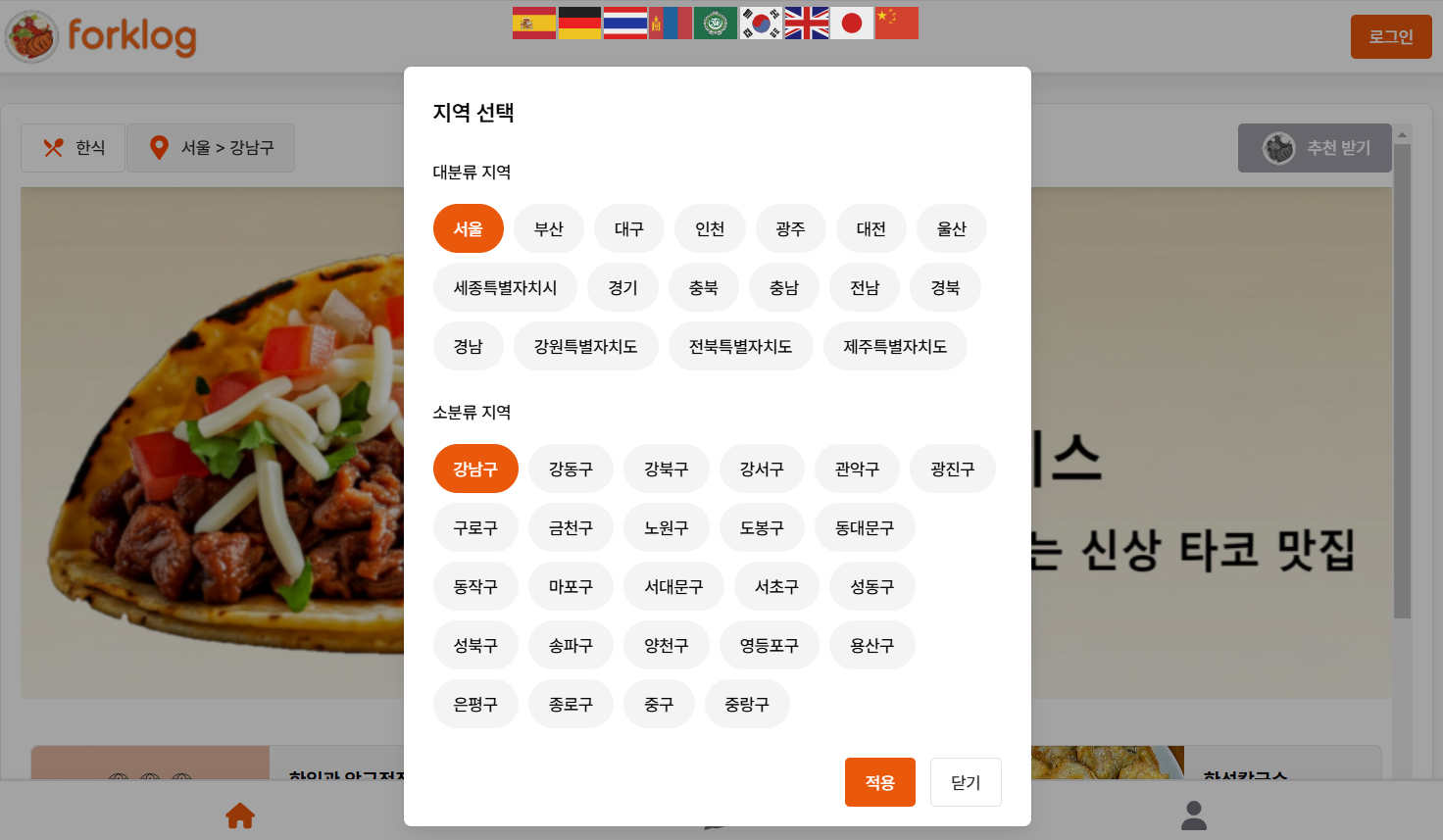
사진 1-5. 지역 기반 검색을 위한 지역 검색 필터. 위 사진과 같이 구성하려면 “서울”, “경기”와 같은 지역 대분류와 “강남구”, “서초구”와 같은 지역 중분류 데이터를 따로 구분하여 다룰 필요가 있었다.
그런데 시간이 지나면서 예상치 못한 단점들이 나타나기 시작했다.
도로명 주소 체계는 생각보다 복잡했다
도로명 주소가 문자열 형태로 들어올 때 이를 각각 대분류, 중분류, 도로명으로 분리하는 기능이 필요했었다. 이 때 행안부에서 제공한 도로명 주소가 어떻게 구성되는지에 관한 정보가 담겨져 있던 PDF를 참고하며 만들었었다.

사진 2-1. 행정안전부 제공 PDF 중 도로명 주소 체계에 대한 정보가 담긴 페이지. References [2] 참조함.
그런데 한 가지 예상치 못했던 문제를 발견했다.
“서울 강남구 XX대로” 라는 도로명 주소가 주어졌을 때, 이를 주소 대분류, 중분류, 도로명으로 분리하고자 한다. 그러면 어떻게 하면 좋을까? 그렇다. 공백을 기준으로 문자열을 분리하면 그만이다. 그러면 “서울”, “강남구”, “XX대로”로 분리되는데, 이 모두 각각 대분류, 중분류, 도로명에 딱 맞기 때문이다.
그렇다면 두 번째 문제. 해당 주소는 어떻게 분리해야할까? → “경기 용인시 처인구”
이 역시 공백을 기준으로 split 해버리면 그만일까? 나도 그렇게 생각했다. 그런데 놀랍게도 “처인구”는 도로명으로 분류되지 않는다는 것이었다. “용인시 처인구” 이 자체가 중분류로 분류된다는 것이다. 즉, 중분류와 도로명에서 “용인시 처인구”와 같이 공백을 기준으로 문자열 토큰이 2개나 되는 예외적인 경우도 있었다는 것이다. 이 경우, 무작정 공백을 기준으로 주소 문자열을 분해하면 대분류, 중분류, 도로명으로 분리할 때 원치 않은 방향으로 분류될 것이다.
이걸 뒤늦게 안 나는 이러한 예외까지도 처리할 수 있는 코드로 수정했어야 했다.
package com.acorn.process;
import java.util.Arrays;
import java.util.Optional;
import java.util.Random;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import com.acorn.dto.LocationSplitDto;
import com.acorn.entity.LocationRoads;
import com.acorn.exception.NoDataFoundForRandomLocation;
import com.acorn.repository.LocationRoadsRepository;
import com.acorn.repository.LocationsRepository;
import lombok.extern.slf4j.Slf4j;
/**
*
*/
@Service
@Slf4j
public class LocationProcess {
@Autowired
private LocationRoadsRepository locationRoadsRepository;
@Autowired
private LocationsRepository locationsRepository;
// 생략...
/**
* 전체 주소로부터 주소 대분류, 중분류, 도로명, 건물번호로 분할하여 반환
*
* 예1) 서울 강남구 XX대로 => "서울", "강남구", "XX대로"
* 예2) 서울 강남구 OO대로 24-11 => "서울", "강남구", "OO대로", "24-11"
* 예3) 전북특별자치도 장수군 장수읍 군청길 19 => "전북특별자치도", "장수군", "장수읍 군청길", "19"
* 예4) 전북특별자치도 장수군 장수읍 군청길 => "전북특별자치도", "장수군", "장수읍 군청길"
* 예5) 서울 XX구 OO대로12번길 => "서울", "XX구", "OO대로12번길"
* 예6) 전북특별자치도 군산시 중앙로 177 => "전북특별자치도", "군산시", "중앙로", "177"
*
* 공백 기준 문자열 분해 시 토큰이 최대 6개까지 나오는 걸로 확인됨
* 예) "경기", "용인시 처인구", "백암면 백원로", "15-12"
*
* @param fullLocation
* @return
*/
public LocationSplitDto getSplitLocation(String fullLocation) {
String[] splited = fullLocation.split(" ");
log.info("splited length: " + splited.length);
LocationSplitDto result = new LocationSplitDto();
switch(splited.length) {
case 1:
result.setLargeCity(splited[0]);
return result;
case 2:
result.setLargeCity(splited[0]);
result.setMediumCity(splited[1]);
return result;
}
// 경기 xx시 xx구 xx로 와 같이 주소 데이터가 있을 때
// "경기", "xx시 xx구", "xx로"와 같이 구분될 때도 있고
// "경기", "xx시", "xx구 xx로" 와 같이 구분될 때도 있음.
// 따라서 특정 문자열 토큰이 주소의 중분류에 포함되는지
// 도로명에 포함되는지 확인하는 로직이 필요.
String[] middleTokens = null;
// 분해된 주소 파편의 마지막 요소가 건물 번호인지 도로명 주소인지 판별
try {
Integer.parseInt(splited[splited.length - 1].split("-")[0]);
middleTokens = Arrays.copyOfRange(
splited,
1,
splited.length - 1
);
result.setBuildingNo(splited[splited.length - 1]);
} catch (NumberFormatException e) {
// 건물 번호 아님이 판별됨.
middleTokens = Arrays.copyOfRange(
splited,
1,
splited.length
);
}
result.setLargeCity(splited[0]);
switch (middleTokens.length) {
case 2:
// 총 문자열 토큰이 4개인 경우. (그 중 마지막은 건물 번호)
if (locationsRepository.findByName(middleTokens[0]) != null) {
// findByName 결과가 존재한다면 splited의 1번째 토큰은 주소의 "중분류"로 판단한다.
result.setMediumCity(middleTokens[0]);
result.setRoadName(middleTokens[1]);
} else {
// findByName 결과 미존재 시 splited의 2, 3번째 토큰 모두 주소의 "중분류"로 판단한다.
result.setMediumCity(middleTokens[0] + " " + middleTokens[1]);
}
break;
case 3:
// 총 문자열 토큰이 5개인 경우. (그 중 마지막은 건물 번호)
if (locationsRepository.findByName(middleTokens[0]) != null) {
// findByName 결과가 존재한다면 splited의 1번째 토큰은 주소의 "중분류"로 판단한다.
result.setMediumCity(middleTokens[0]);
result.setRoadName(middleTokens[1] + " " + middleTokens[2]);
} else {
// findByName 결과 미존재 시 splited의 2, 3번째 토큰 모두 주소의 "중분류"로 판단한다.
result.setMediumCity(middleTokens[0] + " " + middleTokens[1]);
result.setRoadName(middleTokens[2]);
}
break;
case 4:
// 총 문자열 토큰이 6개인 경우. (그 중 마지막은 건물 번호)
// splited 문자열 토큰의 2, 3번째는 중분류, 4, 5번째는 도로명을 구성함
result.setMediumCity(middleTokens[0] + " " + middleTokens[1]);
result.setRoadName(middleTokens[2] + " " + middleTokens[3]);
break;
}
return result;
}
// 생략...
}
예제 1-1. LocationProcess.java
package com.acorn.dto;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.Setter;
import lombok.ToString;
/**
* 주소의 대분류, 중분류, 도로명, 건물 번호(본번-부번 포함)을 각각 담는 DTO
*
* 현재 사용되는 곳
* com.acorn.utils.LocationConverter.getSplitLocation()
*
* @author JeroCaller (JJH)
*/
@Getter
@Setter
@NoArgsConstructor
@AllArgsConstructor
@Builder
@ToString // For logging
public class LocationSplitDto {
private String largeCity;
private String mediumCity;
private String roadName;
private String buildingNo;
}
예제 1-2. LocationSplitDto.java
위 코드를 보면 알겠지만 도로명 주소 체계 자체가 복잡하다보니 코드도 굉장히 복잡한 것을 알 수 있다. 음식점 주소나 회원 주소가 처음 사이트에서 입력되어 올 때에는 문자열 형태로 들어오는데, 이를 세 테이블에 맞게 분류하려다 보니 그 로직이 굉장히 복잡해진 것이었다.
사라진 도로명 주소들
내가 처음 행안부에서 제공하는 전국 도로명 주소 데이터를 세 개의 테이블에 삽입한 후, 나중에 백엔드 작업을 할 때였다. 작업을 하다보니 몇몇 주소들이 DB 안에 존재하지 않음을 발견했다. 분명 행안부에서 제공하는 데이터들을 삽입할 때에는 문제없이 잘 들어갔었는데, 왜 몇몇 데이터, 특히 도로명에서 몇몇이 들어가지 않은 건지 이유를 알 수 없었다. 하지만 이미 DB 내 대용량 데이터를 삽입한 이후라서 그 이유를 파악할 방법을 찾지 못했다.
그렇다면 남은 방법은 단 하나이다. 만약 입력된 주소 문자열이 DB 내에 존재하지 않을 경우 이를 새로 DB에 넣어 저장하는 것이다. 이를 구현했음에도 정작 DB에 삽입되지 않는 문제가 발생했었다.
/**
* 주소 파편 정보를 담은 locationSplitDto를 통해 새 주소를 DB에 저장.
*
* @param locationSplitDto
* @return
*/
@Transactional
public LocationRoads saveFull(LocationSplitDto locationSplitDto) {
// TODO EXCEPTION PK에 해당하는 키가 자동으로 삽입되지 않아 에러 발생.
LocationGroups locationGroupsEntity = LocationGroups.builder()
.name(locationSplitDto.getLargeCity())
.build();
Locations locationsEntity = Locations.builder()
.name(locationSplitDto.getMediumCity())
.locationGroups(locationGroupsEntity)
.build();
LocationRoads locationRoadsEntity = LocationRoads.builder()
.name(locationSplitDto.getRoadName())
.locations(locationsEntity)
.build();
return locationRoadsRepository.save(locationRoadsEntity);
}
예제 2-1. LocationProcess.java
지금와서 보면 각각의 repository에 save하는 코드도 있어야 제대로 DB에 저장되는 것이 아닌가, 하는 생각이 든다.
그럼에도, 여전히 문제점은 존재하였다.
- 위 예제 2-1대로라면, 원래 전체 주소 문자열을 토대로 대분류, 중분류, 도로명으로 분류할 수 있었던 것은 기존 DB에 해당 주소가 존재하기에 이를 비교하여 분리할 수 있었기 때문이었다. 그런데 새 주소를 삽입하는 과정이라면 과연 저 locationSplitDto에 올바른 주소 토큰이 담겨져 있을까? 앞서 말했듯 “경기 용인시 처인구”와 같은 예외가 있다.
- 저게 된다고 하더라도 여전히 주소 테이블을 3개로 나눔으로써 코드가 복잡해진 건 변함이 없다.
- 정말 만에 하나 사용자가 엉뚱한 주소를 넣는다면? 이를 방지할 수 있는 방법이 있는가? 막말로 “소주도 독하군 마시면 뽕가리”라는 문자가 들어와도 이게 유효한 주소인지 판별할 방법이 있을까?
이러한 문제점으로 인해 그때그때마다 새 주소를 DB에 넣는 것은 오히려 DB의 무결성을 해칠 수도 있다는 판단이 들어서 결국 철회할 수밖에 없었다. 이렇게 새 주소를 넣는 로직이 사라지니 결국엔 불완전한 DB 구조가 될 수밖에 없었다.
피드백과 그 이후
이후 현업에서 종사하고 계시는 현직자와 함께 멘토링 시간을 가졌었다. 위 문제점을 말씀 드리니 현업에서는 저렇게 주소를 3개의 테이블로 쪼개서 사용하지도 않고, 애초에 주소를 위한 별도의 테이블을 만들지 않고 주소가 필요한 테이블에 전체 문자열 형식으로 컬럼으로 넣는다고 하셨다. 굉장히 비정상적인 구조였나보다. 그와 동시에 멘토님께서는 나의 설계 방식이 성공적으로 진행된다면 충분히 현업에서도 제안할만 하다고 하셨다. 하지만 위에서 언급한 문제만 봐도 가벼운 문제가 아닌데 그럴 일은 없다고 생각했다. 멘토님께서는 비록 내 방식이 평범한 방식은 아니지만 반드시 전체 문자열로 넣으라는 주문은 하지 않으셨다. 주소를 하나의 컬럼에 전체 문자열 방식으로 넣는 방식과 내 방식 중에서 고민해서 결정하는 게 어떻겠냐는 말씀을 하셨다. 사실 내가 이렇게 과정을 줄여 말해서 그렇지 이에 대해서 멘토님, 다른 팀원들과 긴 이야기를 나눴다.
멘토님의 말씀을 들으면 들을수록 멘토님의 방식이 옳다는 생각이 들었다. 위에서 언급한 문제점들이 장점을 압도한다는 생각이 들어서였다. 그래서 팀 회의까지 거친 끝에 주소를 위한 3개의 테이블을 음식점, 회원 등의 다른 테이블에서 사용하지 않기로 하고, 각각의 테이블 내에 주소 필드를 생성하여 주소를 넣는 방식을 택하기로 하였다. DB 구조가 일부 바뀌는 것이기에 자바 코드에서도 바뀌는 부분이 적지 않았다. 그럼에도 한 번 바꾸니 위에서 언급했던 문제점들이 사라져서 오히려 더 편해졌다.
도로명 주소 체계가 이렇게 복잡한 줄 알았으면 주소 관련 DB 설계를 저렇게 복잡하게 하지 않았을텐데, 라는 생각이 든다.
의외의 사용처
그런데 내가 설계했던 주소 3개의 테이블이 전혀 다른 곳에서 필요로 하게 되었다. 그것은 지역 검색 필터에서였다. 앞선 사진 1-5와 같이 지역 검색을 위해 필터 모달이 필요했는데, 이를 위해선 지역 대분류와 중분류의 데이터가 필요했던 것이었다. 원래는 이 3개의 테이블도 삭제하려고 했으나 다시 필요성이 생겨서 삭제하지 않았고 이를 활용하여 지역 검색 필터에 보이기 위한 지역 대분류, 중분류 데이터를 백엔드에서 제공하도록 제작하였다.
package com.acorn.process;
import java.util.List;
import java.util.stream.Collectors;
import org.springframework.stereotype.Service;
import com.acorn.dto.location.LocationGroupsFilterDto;
import com.acorn.entity.LocationGroups;
import com.acorn.repository.LocationGroupsRepository;
import lombok.RequiredArgsConstructor;
@Service
@RequiredArgsConstructor
public class LocationProcess {
private final LocationGroupsRepository locationGroupsRepository;
/**
* 주소 대분류 및 소분류 DTO 조회 및 반환.
*
* 주소 대분류 DTO 내부에 소분류 DTO가 포함되어 있는 구조.
*
* @author JeroCaller (JJH)
* @return
*/
public List<LocationGroupsFilterDto> getLocationGroupsFilterAll() {
List<LocationGroups> locationGroupsFilterDtos
= locationGroupsRepository.findAll();
return locationGroupsFilterDtos.stream()
.map(LocationGroupsFilterDto :: toDto)
.collect(Collectors.toList());
}
}
예제 3-1. LocationProcess.java
package com.acorn.dto.location;
import java.util.List;
import java.util.stream.Collectors;
import com.acorn.entity.LocationGroups;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Getter;
import lombok.NoArgsConstructor;
/**
* 지역 필터 정보 반환용 DTO 클래스
* 지역 대분류 DTO 내부에 지역 중분류 DTO가 포함되는 구조
*/
@Getter
@NoArgsConstructor
@AllArgsConstructor
@Builder
public class LocationGroupsFilterDto {
private int no;
private String name;
private List<LocationsFilterDto> locationsFilterDtos;
public static LocationGroupsFilterDto toDto(LocationGroups entity) {
List<LocationsFilterDto> locationsFilterDtos = entity.getLocations()
.stream()
.map(LocationsFilterDto :: toDto)
.collect(Collectors.toList());
return LocationGroupsFilterDto.builder()
.no(entity.getNo())
.name(entity.getName())
.locationsFilterDtos(locationsFilterDtos)
.build();
}
}
예제 3-2. LocationGroupsFilterDto.java
package com.acorn.dto.location;
import com.acorn.entity.Locations;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Getter;
import lombok.NoArgsConstructor;
/**
* 지역 필터 정보 반환용 DTO 클래스
* 지역 대분류 DTO 내부에 지역 중분류 DTO가 포함되는 구조
*/
@Getter
@NoArgsConstructor
@AllArgsConstructor
@Builder
public class LocationsFilterDto {
private int no;
private String name;
public static LocationsFilterDto toDto(Locations entity) {
return LocationsFilterDto.builder()
.no(entity.getNo())
.name(entity.getName())
.build();
}
}
예제 3-3. LocationsFilterDto.java
이 덕분에 지역 검색 필터를 구성할 수 있었다.
글을 마치며
ERD 설계에서 내가 너무 어렵게 생각한건가, 싶기도 하지만 또 한 편으로는 “ERD 설계 시 어디까지 고려해야하는가”에 대한 질문도 남게 되었다. 위에서 언급한 예시에서는 도로명 주소가 생각보다 복잡하다는 문제점 때문에 결국에는 별도의 주소 테이블을 만든 게 좋은 결정이 아니게 되었다. 하지만 내가 앞서 언급했던 제 1정규화 문제(하나의 컬럼에 둘 이상의 원자값이 들어있다는 느낌이 들기도 하지만 좀 애매하기도 한 것 같다), 서로 관련 없는 테이블들에서 주소라는 공통의 필드가 등장한다는 점 등은 여전히 생각해볼만한 거리가 아닌가, 라는 생각이 들기도 한다. 그리고 주소 말고도 이러한 비슷한 상황이 나중에 다른 프로젝트에서 나타난다면 이를 어떻게 해결해야할지에 대해서도 과제로 남게 되었다. 내가 위에서 한 것처럼 별도의 테이블로 운용할 것인가, 아니면 그냥 각각의 테이블의 컬럼으로써 사용할 것인가. 지금 생각해봐도 나에게는 여전히 헷갈리는 문제이다. 이렇게 보니 또 한 편으로는 ERD 설계할 때에는 단순하게 생각해야하나, 싶기도 하다.
References
[1] 카카오 다음 제공 우편번호 서비스 - 주소 검색 서비스
[2] 행정안전부 - 도로명 주소
This content is licensed under
CC BY-NC 4.0
![]()
![]()
![]()

댓글남기기