[Forklog] 팀프로젝트 시작 - 되돌아보며
팀 프로젝트의 시작 - 기획과 설계
팀프로젝트가 시작되며 우리 팀은 첫 날 모여서 주제를 논의하였다. 어떤 웹 사이트를 만들지 한동안 고민을 하였다.
사실 그 이전에 팀이 두 번이나 해체됨을 겪은 적이 있다. 맨 처음 팀에서는 나도 프로젝트 초기부터 참여했기에 어떤 사이트를 만들지 다같이 고민하였는데, 사실 이 때에도 쉽지는 않았다. 아이디어가 생각보다 쉽게 나오지 않았기 때문이다. 첫 번째 팀이 중도 해제되면서 두 번째 팀으로 갔을 때는 이미 그 팀은 기획, 설계가 끝났고 개발 단계에 들어섰기에 나는 기획, 설계에 참여할 겨를도 없이 바로 개발에 투입되었다. 그 때 당시엔 지금보다도 배운 게 별로 없기도 하였고, 실력도 부족하였기에 다른 사람의 코드를 읽고 해석하는 게 힘들었다. 지금 와서 생각해보면 그 당시에는 중간 프로젝트 기간으로, 백엔드에서는 JSP까지만, 프론트엔드에서는 React와 같은 프레임워크가 아닌 Vanila Javascript까지만 배웠기에 이 언어들로 사이트를 구현했어야 했다. 스프링 부트와 리액트까지 배운 지금의 입장에서는 이러한 프레임워크들 덕분에 코드를 훨씬 간결하게 작성해도 똑같은 기능을 구현할 수 있음을 깨달았고, 그렇기에 그 당시엔 더더욱 다른 사람의 코드를 이해하는 게 어려웠던 것 같다.
그럼에도, 개발하면서 오류 및 버그와 부딪히고 그 원인을 파악하는 것보다도 아이디어 및 기획, 설계 단계가 더 어렵다는 것을 이 세 번의 팀을 거쳐보니 더더욱 절실하게 느꼈다. 세 번째 팀에서 다른 분들과 같이 인터넷으로 조사해보니 왠만한 기능들은 모두 구현되어 있는 사이트들이 대다수였다. 게다가 요즘은 AI가 대세다보니 별의별 곳에 AI 기능들도 들어가 있었다. 나를 비롯한 팀원들은 챗지피티만 써봤지 공식적으로 AI 관련 교육을 들어본 적이 없기에 AI로 시중에 나와있는 웹 사이트들과 차별화를 두기는 어려웠다.
학원에서 수강생 입장으로서의 팀 프로젝트이다보니 실제 현업과는 다르게 실제 음식점 운영 중인 사장님들을 섭외하여 마치 네이버 플레이스나 배민처럼 사장님들이 직접 자신의 음식점 정보를 등록하게 하는 등의 활동들은 가능할리 만무했고, 그렇다고 우리가 회사 사장님마냥 AI 전문가와 같은 기술 전문가나 특정 분야 전문가를 고용하는 것은 더더욱 불가능했다. 이러한 능력의 한계가 아이디어의 한계로 다가왔다. 솔직히 이미 존재하는 상업용 사이트들, 특히 위와 같은 과정을 거칠 수 있는 기업들과 경쟁하기 위해 차별점을 두고 사이트를 만든다? 솔직히 거의 불가능한 일이 아닌가 싶었다. 그렇기에 더더욱 어떤 컨셉의 사이트를 만들어야할지 더 고민이 되었었다.
기나긴 아이디어 회의와 고심 끝에 우리 팀은 맛집 추천 사이트를 만들기로 하였다. 많은 참고가 되었던 사이트는 “식신”이라는 사이트였다.
맛집 추천 사이트에 우리가 넣고자 했던 기능들은 크게 보면 다음과 같았다.
- AI 또는 회귀 분석 등을 이용하여 사용자 맞춤형 맛집 추천 알고리즘 개발.
- 커뮤니티적 성격을 띄는 기능들 (댓글, 리뷰, 오픈 채팅 등등)
- 점주 페이지
- 음식점 정보들은 Open API로 가져올 계획이었는데, 생각보다 영업 시간, 메뉴 및 가격 등의 세부 정보까지 제공해주는 API가 없었다. 따라서 이를 보충하려는 목적으로 점주 페이지를 따로 만들어 점주가 직접 자신의 음식점 정보를 입력할 수 있도록 하기 위함이었다.
하지만 아쉽게도, 위 아이디어 중 제대로 구현한 것은 두 번째, 커뮤니티 기능 뿐이었다. 첫 번째는 “사용자가 즐겨찾기한 음식점의 카테고리와 일치하는 음식점들을 추천”한다는 것을 알고리즘으로 세워 대체하였고, 이는 쿼리문을 적절히 잘 세워서 DB로부터 특정 데이터들을 뽑을 수 있었던 기능이었다. 회귀 분석은 강의 시간에 Node.js로 잠깐 하는 걸 살펴보았었다. 하지만 솔직히 말하면 이를 완벽히 이해하려면 추가적인 공부가 필요한데, 강의 진도는 너무 빠르고, 팀 프로젝트도 빨리 진행했어야 했기에 이걸 팀프로젝트에 녹일 생각만 했을 뿐, 실천하기가 어려웠다. 참고로 내가 다녔던 과정은 엄연히 자바 백엔드 기반 풀스택 과정이었다. AI나 통계 쪽이 전혀 아니었다. 요즘에는 포트폴리오에 AI나 데이터 분석 등을 넣으면 더 강점이 있다고는 하지만 지금 당장 시간과 팀플 진도가 부족한 상황에서는 너무 무리였었다. 그래서 마지막에는 이조차도 제외시킬 수밖에 없었다.
세 번째 기능은 아예 넣지 않았다. 그 이유는 첫 째, 이 당시 이미 회원 가입, 별점 리뷰, 댓글 달기 등 CRUD 기능이 여럿 존재 하는데 점주 페이지도 결국에는 CRUD로 기술이 겹쳐서였고, 둘 째는 안 그래도 추천 알고리즘에 AI를 사용하거나 추가 기능 개발하기에도 시간이 부족해서 점주 페이지 기능은 결국에는 제외시켰다.
솔직히 말해서, 위에서 언급한 기능들 모두 넣고 싶었고, 그와 더불어 DB에 축적된 데이터를 기반으로 차트도 그려서 사용자에게 맛집 관련 통계를 시각적으로 보여주고 싶기도 했고, 아무튼 여러 가지 하고 싶었다. 하지만 이 모두 1달이라는 짧은 시간 내에는 불가능하였다. 더군다나 기획, 설계 후 개발 과정에서 나의 경우 이상하리만치 1주일이나 지나도 제대로 구현되지 않는 기능이 있었는데, 후에 멘토링 과정에서 애초에 설계 자체를 잘못했었다는 사실을 깨닫게 되었다. 이로 인해 1주일을 사실상 날려버린 것이었다.
팀 해제로 인해 다른 팀들에 비해 출발점이 매우 다른 상태에서 시작할 수밖에 없어서 사실상 시간이 부족했다는 점, 생각보다 기획, 설계에서 오랜 시간이 걸렸다는 점, 설계가 잘못되었다는 걸 뒤늦게 깨달았다는 점 등이 복합적으로 작용하여 결국에는 우리가 처음에 기획했던 것 개발 범위 및 기능들을 더 줄여가며 개발할 수밖에 없었다. 이 점이 개인적으로 너무 아쉬운 점이었다. 이와 관련하여 더더욱 아쉬웠던 점은, 나를 비롯하여 팀원들 모두 실제 개발자 현업 경험이 없는 수강생들인데, 팀플과 관련한 수업이 사실상 없었다는 점이 너무 아쉬웠다. 지식, 기술 자체는 강의에서 제공해주니 빠르게 따라갈 수 있었지만, 팀플 방법론에 대해서는 나중에 몇 번의 멘토링과 피드백을 뒤늦게 들은 것이 전부이다. 중간 프로젝트도 경험했지만 사실 이것만으로는 팀플 실력을 키우기에 부족했다고 생각한다. “팀플”도 “독학”이 가능한 부분인가에 대해선 지금도 여전히 회의적으로 생각한다. 설계가 잘못되었음을 지적할 사람이 없어 뒤늦게서야 깨닫게 될 수밖에 없는 구조가 너무 아쉬웠다. 그래서 아예 “팀플 방법론”에 대해서도 강의가 있었다면 좋지 않았을까, 라는 생각이 든다.
이러한 이유들로 인해 초기에 기획했던 것보다 훨씬 적은 기능들을 구현하는 것에 그쳤지만, 그럼에도 이것만 제외하면 사실 난 개인적으로 팀프로젝트를 통해서 배운 점들도 적지 않다고 생각한다. 그 중 하나가 바로 기술 문서이다.
기술 문서의 중요성
프로젝트의 애피타이저 - 기획서
사실 독학 시절의 난 개인 프로젝트를 진행할 때 기획, 설계 관련 문서를 거의 작성하지 않고 무작정 진행했다. 결과물도 머리속에 그려서 그것대로 따라가는 방식이었다. 그런데 이 학원에서 팀프로젝트를 할 때는 전혀 딴판이었다. 처음부터 화면설계서, 기능정의서 등의 여러 가지 기획서를 작성하고, DB 테이블 구조도 ERD를 그리는 등 굉장히 체계적으로 진행되었다. 이렇게 하니 물론 기획, 설계 단계에서 시간을 많이 소비하기에 “언제 개발 시작하는 거지?”라는 의문도 들었지만, 나중에 되돌아보니 장점도 있음을 알았다.
- 팀프로젝트이기에 다른 팀원들과의 의사소통이 필수인데, 제대로 된 의사소통을 위해선 문서화가 필수적이다. 이런 의미에서 화면설계서, 기능정의서 등이 필수일 수밖에 없다.
- 이러한 정의서, 설계서 등의 문서를 만들어두면 내가 팀 내에서 어떤 작업을 해야할지 명확해지고, 나중에 까먹더라도 다른 팀원들을 귀찮게 할 필요없이 문서를 다시 보기만 하면 되기에 의사소통적인 측면에서 효율적이라 생각되었다.
- 나중에 멘토 강의에서 오신 현직 개발 팀장님의 말씀에 따르면, 의사소통도 어떻게 보면 기업의 입장에서 “비용”이라고 한다. 제대로 알아듣지 못해서 또 질문하는 행위, 오해로 인해 원래 방향과는 전혀 다른 개발 등이 그 예이다. 이를 방지하기 위해선 소위 문서화하는 것이 비용을 최소화하는 방법 중 하나라고.
- 기획서를 작성하면서 내가 놓쳤던 부분을 확인할 수 있다. 일례로, 화면 설계서 작성 시 비로그인 사용자가 로그인한 사용자만 사용할 수 있는 기능의 버튼을 클릭하면 어떻게 해야할 지에 대한 것이 전혀 없었음을 깨달았다. 그 덕분에 아래 사진에서도 볼 수 있듯 “로그인 안내창”을 띄우도록 하는 기능을 화면 설계서에 추가할 수 있었다. (최종 결과물에서는 바로 로그인 페이지로 이동하도록 수정되었다)
- 개인 프로젝트할 때에도 이러한 문서화가 도움이 될 것 같다. 계획을 세우지 않고 무작정 머리 속에 그려놓은 것만 생각하고 개발하다보면 분명 예기치 않은 문제에 부딪히게 될 것이고, 자칫 방향성을 잃기 쉬울 것이라 생각하기에 이를 방지하기 위해선 최소한의 문서화라도 필요하지 않을까, 란 생각이 들었다.
다만 지금와서 드는 의문은, 실무에서는 날이 갈수록 사용자들의 요구사항은 많아지면서 다양해질테고, 이는 곧 프로젝트의 요구사항 반영 주기가 날이 갈수록 짧아진다는 것인데, 이럴 때에도 기획서를 작성하는 게 맞나, 라는 의문이다. 확실히 기획서를 만드는 경험을 해보니 생각보다 시간이 꽤 걸리는 작업이었기 때문에 드는 의문이다. 이건 현업에 종사해봐야 알 수 있는 사실인걸까.
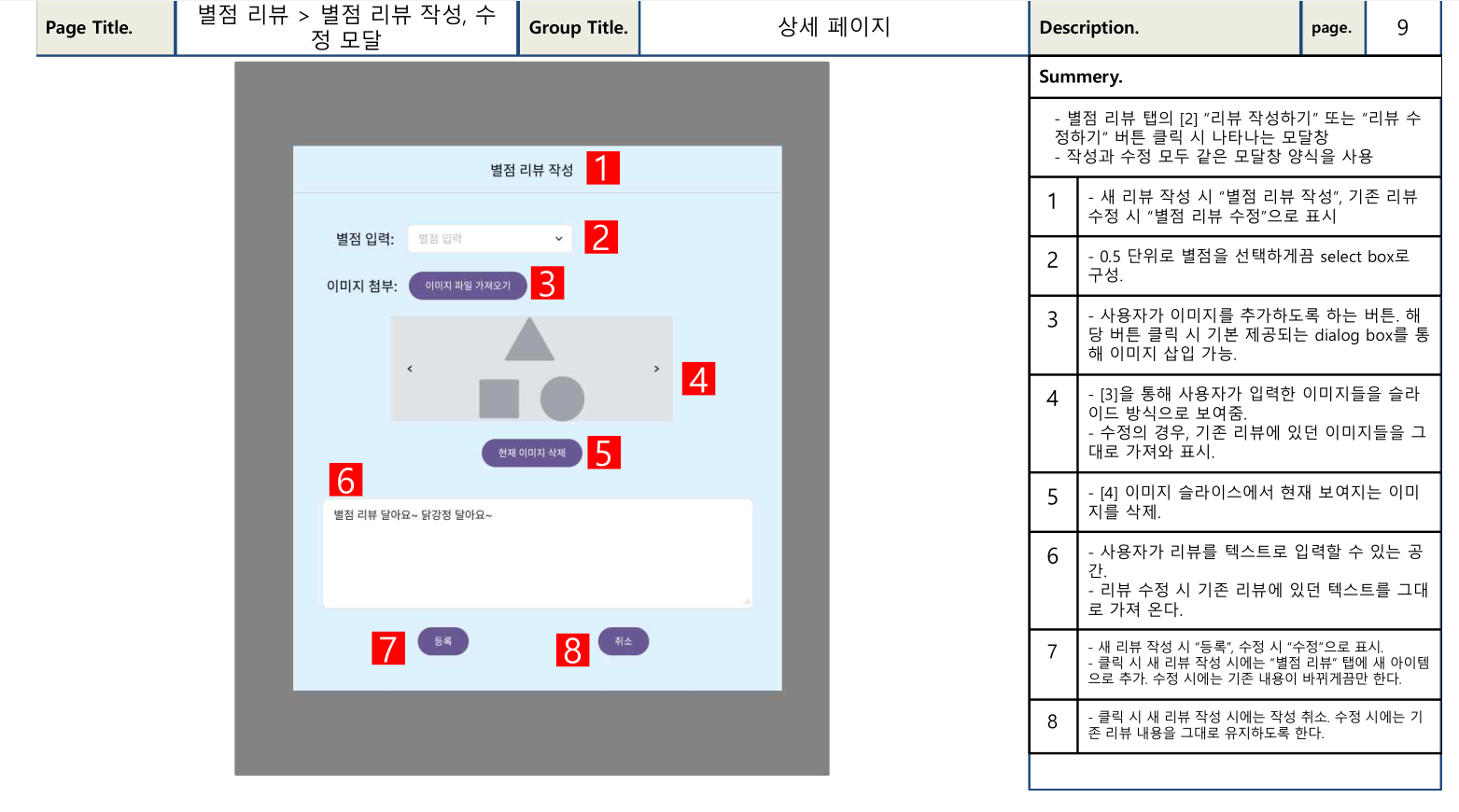
사진 1-1. 내가 작성한 화면 설계서 일부.
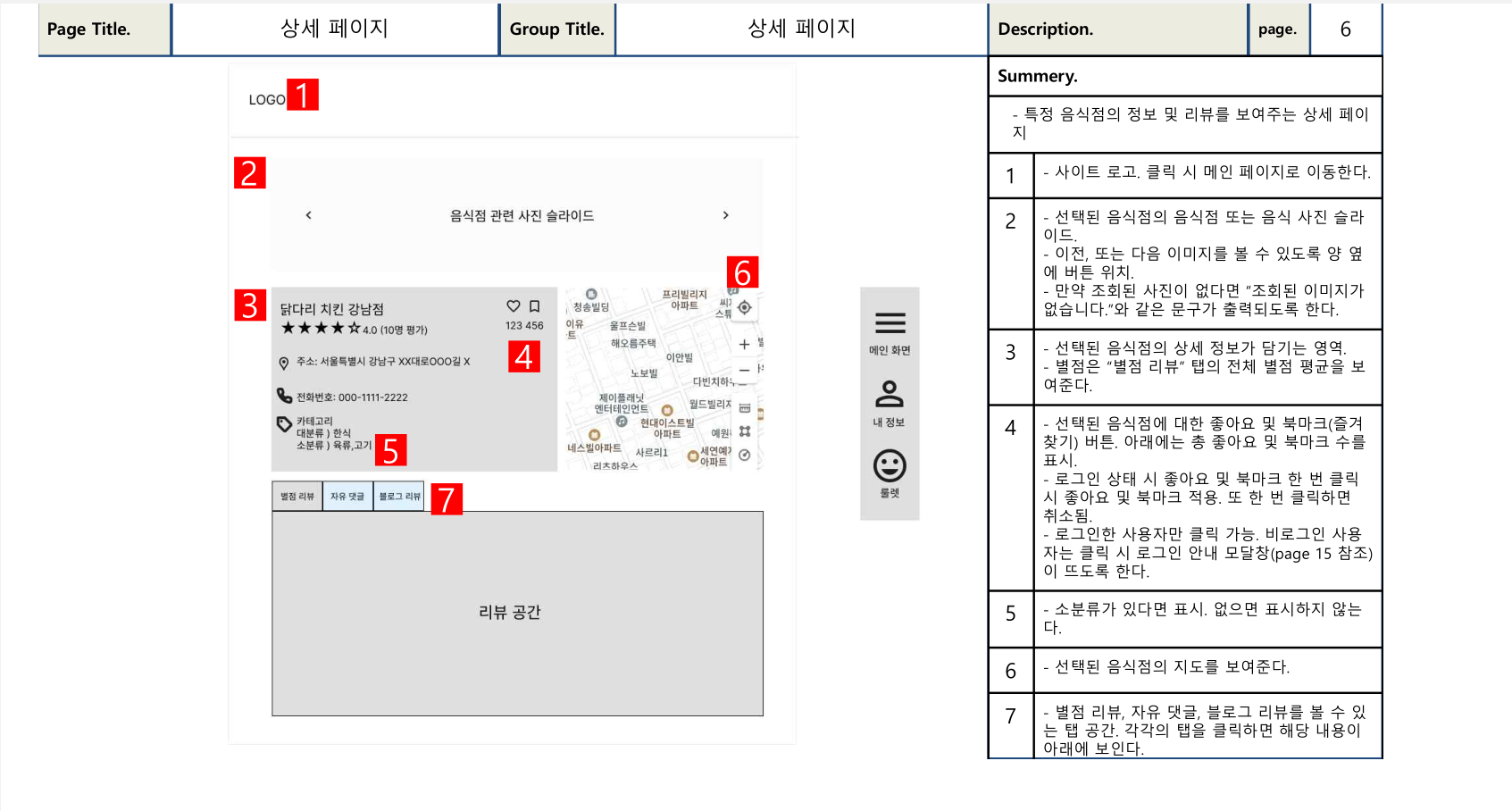
사진 1-2. 내가 작성한 화면 설계서 일부.
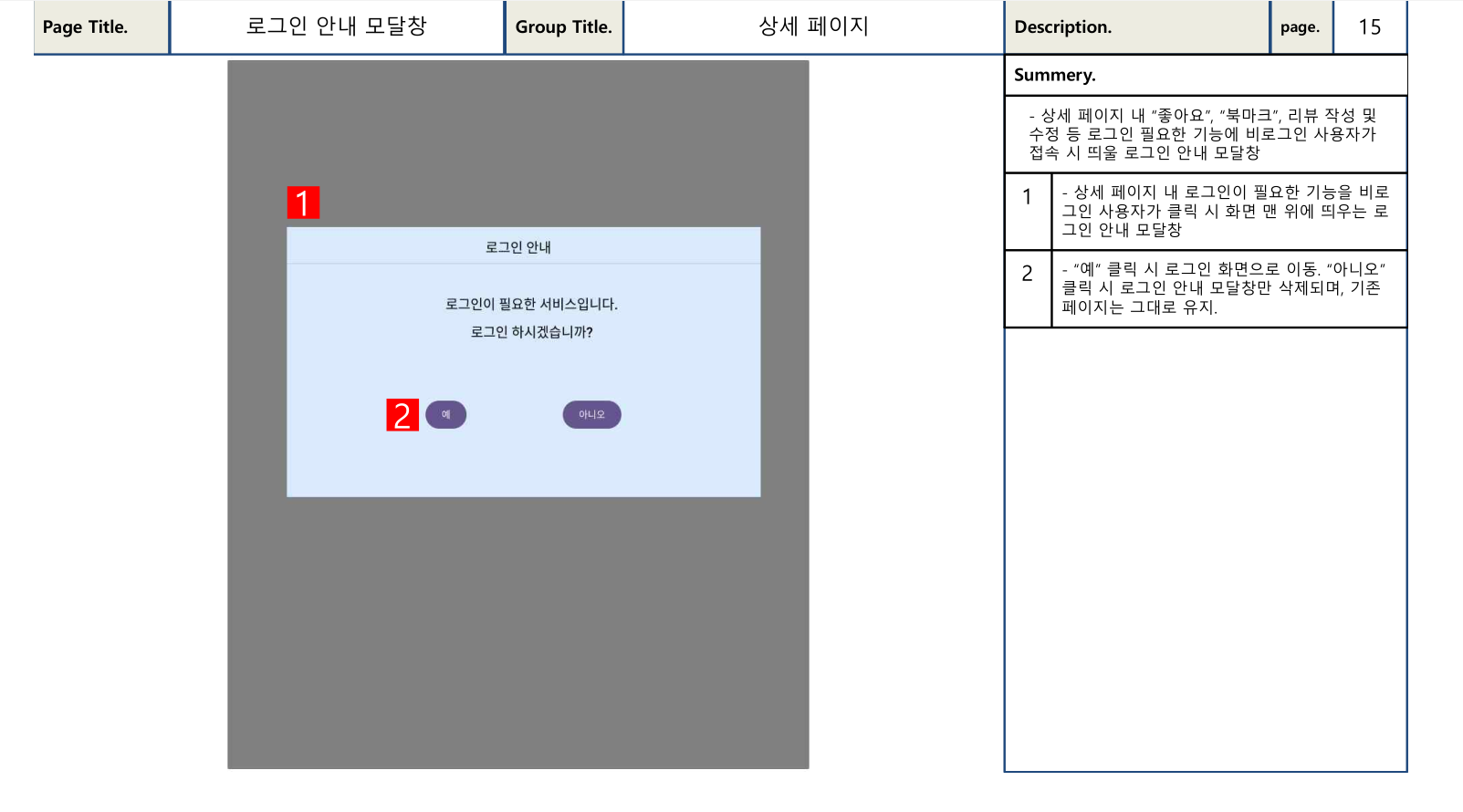
사진 1-3. 내가 작성한 화면 설계서 일부.
위 사진들은 팀원들과 함께 화면설계서를 작성할 때 내가 실제로 작성한 부분이다. 왼쪽에는 실제로 사용자 입장에서 특정 페이지가 어떻게 보일지를 그린 화면이고, 오른쪽에는 그 화면의 세부적인 각각의 요소들이 어떤 기능을 할 것인지를 적은 내용이 담겨져 있다. 이렇게라도 화면설계서가 있으니 우리가 구현하고자 하는 사이트의 모습을 미리 볼 수 있어서 개발 방향도 잡히는 것 같아 좋았다.
참고로 화면 설계서에서는 내가 한 가지 노리고 그린 것이 있다. 바로 컴포넌트의 재활용이다. 음식점 상세 페이지에는 그 음식점을 잘 보여주는 이미지들을 이미지 슬라이드 방식으로 보여주도록 되어 있다. 그리고 별점 리뷰에서도 리뷰어가 여러 이미지들을 등록할 수 있게끔 하였는데, 여기서도 이미지 슬라이드 컴포넌트를 그대로 적용하도록 하였다. 이렇게 하면 같은 컴포넌트를 재활용할 수 있어 개발 시간의 단축을 노린 것이었다. 아무래도 내가 듣는 학원 수강 과정이 백엔드 중심이라서 그런지 나를 비롯한 우리팀 모두 프론트엔드 쪽은 약했다. 게다가 앞서 말했듯 다른 팀들에 비해서도 시간이 부족했던지라 이러한 점들을 염두해두고 최대한 같은 컴포넌트를 재사용할 수 있도록 설계한 것이었다.
나중에 사이트를 완성했을 때에는 화면 설계서와는 다른 부분들이 많았다. 프론트엔드에서 별점 리뷰 구현을 담당했던 팀원 분이 이미지 슬라이드 방식이 제대로 구현되지 않아서 이를 제외시켰다고 한다.
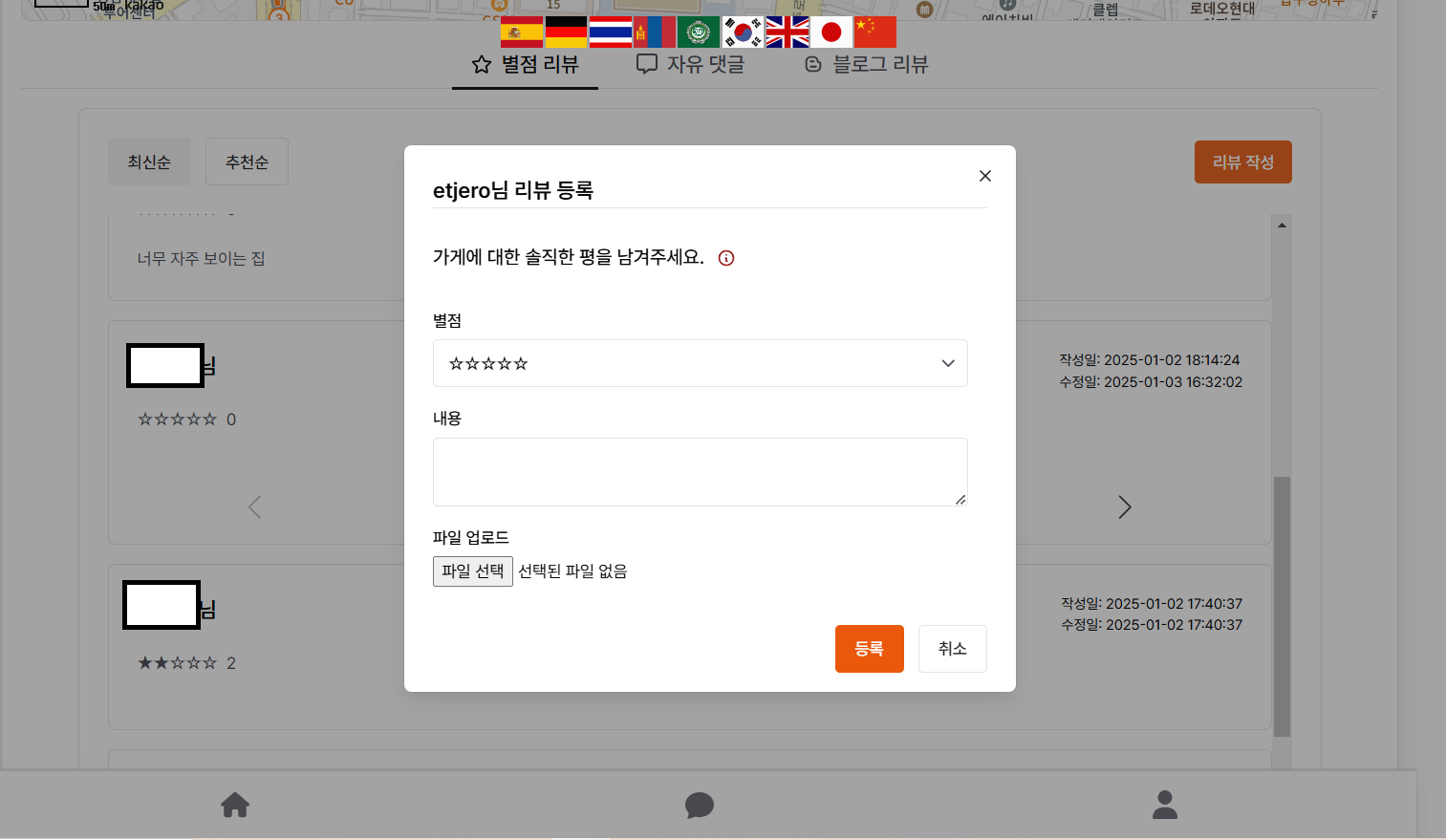
사진 1-4. 실제 구현한 사이트의 별점 리뷰 등록 모달창. 사진 1-1의 화면설계서와 비교했을 때 다소 변경된 부분이 있다.
이처럼 최종 개발 완료 후의 사이트가 처음에 기획했던 화면 설계서대로 똑같이 만들어지는 것은 아니라는 것도 확인할 수 있었다. 즉, 아무리 초기에 화면 설계서를 잘 정의한다하더라도 기술적 문제나 다른 이유들로 인해 언제든지 세부 사항들은 달라질 수 있다는 것이다.
프로젝트의 디저트 - TC와 API 명세서
반면, 프로젝트가 마무리 단계에 다가가서도 작성하는 문서들이 있다고 한다. 그 중 대표적으로 테스트 케이스 (Test Case, TC) 문서와 API 명세서이다. TC의 경우 다 제작된 웹 사이트의 이 버튼 저 버튼 눌러가면서 원래 기획했던 기능들이 제대로 동작하는지를 테스트하고 이를 문서로 적는 것을 말한다. API 명세서의 경우, 우리는 백엔드에서 스프링 부트를 이용하여 REST API를 제작하였고, 이를 프론트엔드에서 리액트로 구현하여 이 API를 요청하여 원하는 데이터를 얻어와 화면에 출력하는 구조였다. 이렇게 REST API를 정의하였기에 처음 보는 사람도 이 REST API들이 무엇이고 어떤 기능을 하는지 알 수 있도록 상세한 명세서를 작성하는 것이었다.
이는 마지막 멘토링을 받을 때 멘토님의 권유로 작성하게 된 문서들이었다. 멘토님의 말씀에 따르면 이러한 문서들 모두 현업에서 작성하는 문서들이라고 한다. 그리고 이러한 것들을 미리 경험해보는 것도 좋다고 하셔서 우리 팀도 좀 늦은 감이 있었지만 어찌됐든 참여할 수 있게 되었다. 나는 그 중에서 API 명세서를 담당하게 되었다. 아무래도 내가 그 전부터 Open API를 조사하기도 하고, OpenFeign을 이용하여 Open API의 데이터를 백엔드 단으로 가져오는 작업도 해봤기에 내가 맡게 되었다. 처음에는 어떻게 작성해야할지 막막했는데, 멘토님께서 내가 Open API를 조사하면서 참고한 API 제공 사이트들의 공식 문서를 참고하면 된다고 하셨다. 그래서 나는 이 프로젝트에서 실제로 사용한 Kakao API의 공식 문서와 더불어 이 프로젝트에 실제로 쓰이진 않았지만, 조사 과정에서 알게된 공공 데이터 포탈에서 흔히 보던 API 명세서 양식을 참고하였다. 이와 더불어 우리 팀이 만든 모든 REST API를 한 눈에 볼 수 있는 swagger도 같이 화면에 켜두면서 API 명세서를 작성하였다.
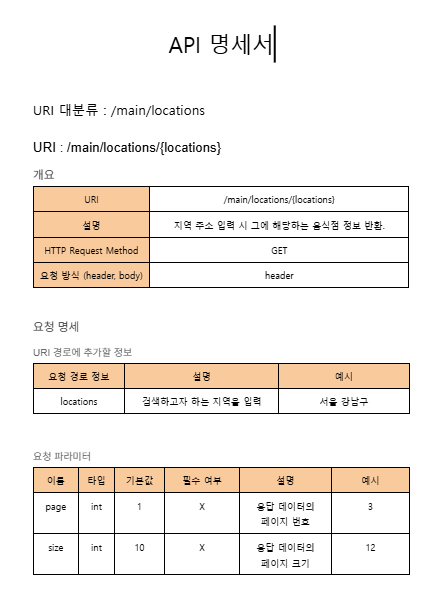
사진 2-1. 내가 작성한 API 명세서 첫 부분. 나를 비롯한 우리 팀이 작성한 REST API의 명세서들을 작성하였다.
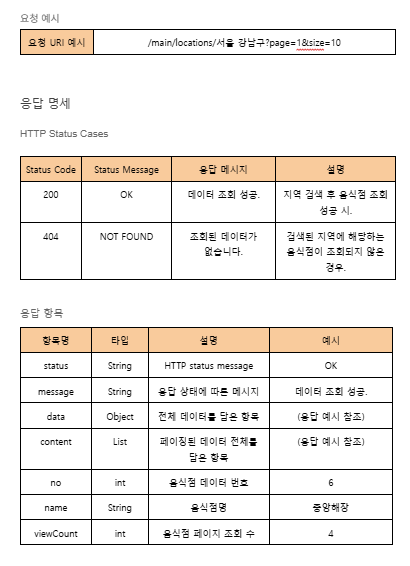
사진 2-2. 요청 예시와 응답 명세

사진 2-3. REST API 호출 시 제공받는 응답 데이터의 구조를 예시로 듦으로써 사용자 입장에서 직관적으로 이해하기 쉽도록 작성하려고 하였다.
나는 우리 프로젝트를 처음 보는 사람도 우리가 제공하는 REST API들이 각각 어떤 데이터를 제공하고 어떻게 사용하는지를 직관적으로 알 수 있도록 최대한 상세한 내용까지 적으려고 노력하였다. 그래서 위 사진처럼 아예 응답 예시까지 제시하였고, 각각의 요청 파라미터의 응답 프로퍼티들의 의미도 표 형태로 작성하였다.
막상 작성해보니 Google Docs 기준으로 42페이지나 작성헀음에도 모든 REST API들을 다 작성할 수가 없었다. 이 때 당시는 수료날까지 며칠 남지 않은 상황이기도 하고, 이력서 및 자소서도 작성해야 했던 시기라서 42페이지까지만 작성하고 중단할 수밖에 없었다. 그래도 API 명세서가 존재한다는 것과, 이를 실제로 직접 작성해보는 경험을 할 수 있었다는 것에 의의를 두고 싶다.
이러한 문서들을 직접 작성해보니 확실히 기획 및 설계에 시간이 좀 걸리긴 하더라도 체계적으로 프로젝트를 설계할 수 있다는 것이 큰 장점임을 알 수 있었다. 이런 것들을 현업에서도 기본적으로 한다고 하니 현업에 대해서도 간접적으로 배울 수 있었던 기회였다고 생각한다. 내 개인 프로젝트에도 이러한 문서들을 작성하여 체계적으로 프로젝트를 설계, 관리해봐야겠다.
그리고 개인적으로는 팀 프로젝트에 도입하지 못해 아쉬운 문서가 하나 있었다. 바로 Javadocs였다. 메서드나 클래스 단위로 식별자 바로 위에 작성하는 주석으로, /** */ 형태의 주석이다. 이러한 주석들을 정의한 클래스나 메서드에 모두 붙여주고, 특정 과정을 거치면 Java 공식 문서와 똑같이 생긴 문서를 생성할 수 있다. 내가 학원에서 자바 기초 문법을 수강할 때 만들었던 간단한 라이브러리가 있었는데, 여기에 Javadocs를 도입하여 문서화하여 Github Pages에 게시까지 한 경험이 있다.
이에 대한 깃허브 레포지토리는 다음의 주소를 참고
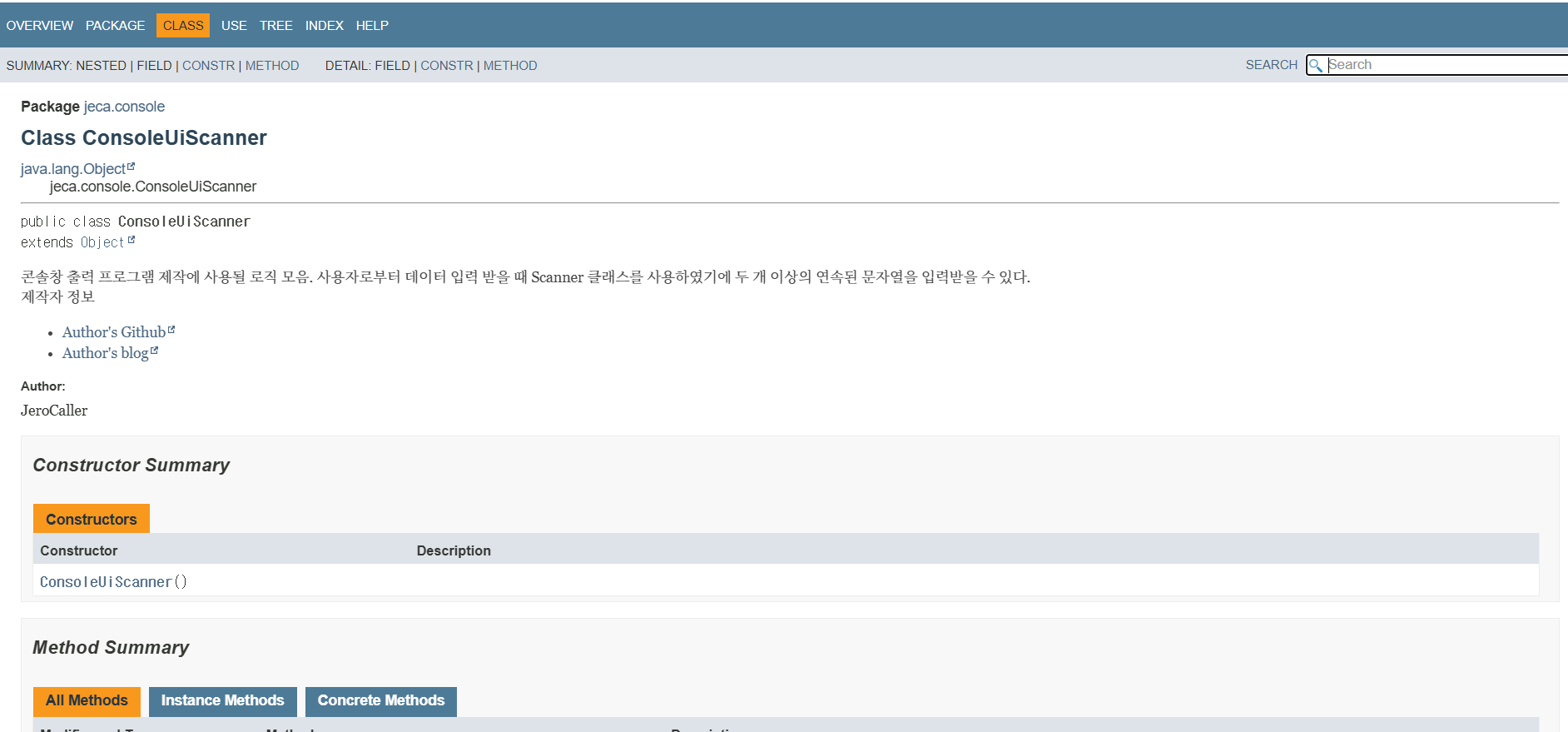
사진 2-4. 내가 만든 자바 기본 라이브러리에 대한 Javadocs 문서 일부. 특정 클래스의 설명문이 보인다.
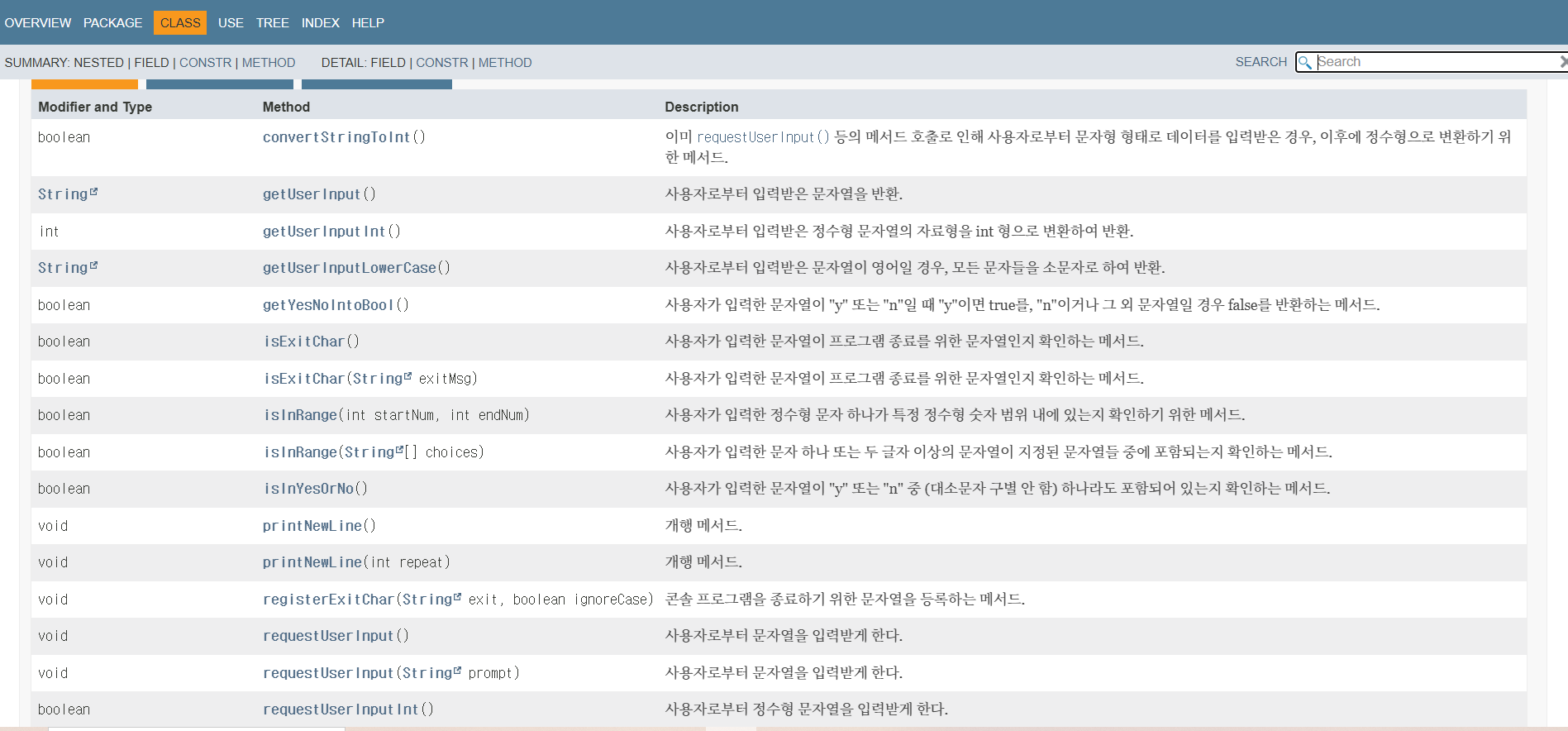
사진 2-5. 특정 클래스 내 모든 메서드들의 설명을 볼 수 있다.
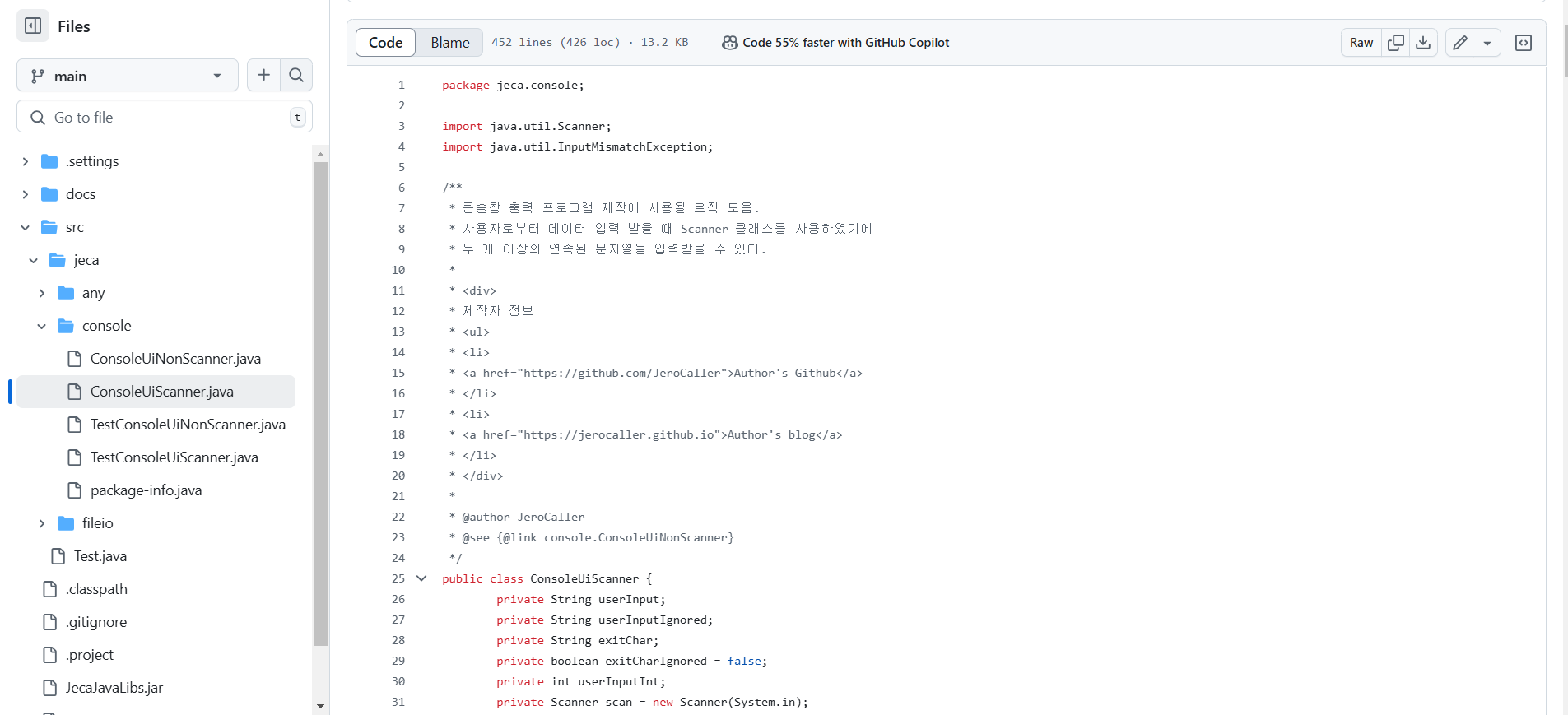
사진 2-6. 코드에서 Javadocs 주석 작성 예시
위 사진 2-6 처럼 개발자가 정의한 메서드나 클래스명 바로 위에 Javadocs 형식의 주석을 작성하면 이후에 위 사진 2-4~2-5처럼 문서화하여 클래스 및 메서드에 대한 정보를 독자들에게 제공할 수 있게 된다.
이러한 문서가 있으면 처음 보는 사용자나 아니면 시간이 지난 후에 다시 프로젝트 코드를 손봐야할 일이 있을 때 더 손쉽게 클래스나 메서드 사용법에 대해 이해할 수 있어 좋다고 생각된다. 주석에 외부에 공개되면 안되는 내용을 쓰는 게 아닌 이상은 Github Pages에 배포까지 하여 프로젝트에 대한 이해를 더 높일 수 있지 않을까, 란 생각이 들기도 한다. 하지만 이는 이전까지 계속 언급해왔던 시간 문제 때문에 이를 제안할 타이밍도 놓쳐서 결국에는 하지 못했다. 이 역시 나중에 개인 프로젝트 할 때에는 넣어야 겠다.
백엔드를 경험하며
이 프로젝트에서 나는 기획서(다른 분들도 작성하였다) 및 회의록 작성 말고도 개발 쪽에서 백엔드를 담당했다. 우리 팀은 스프링 부트를 사용하였으며 DB 연동은 Spring Data JPA를 사용하였다. 다른 팀원들은 주로 프론트엔드를 하거나 백엔드와 같이 했던 반면 나는 백엔드에서만 작업을 했다. 의도했던 건 아니고, 원래 외부 API의 데이터를 백엔드로 가져와 DB에 저장하는 일련의 시스템을 구축하는 일을 담당했기에 이를 위해 백엔드를 담당하게 되었는데, 그동안 다른 팀원분들은 사이트의 뼈대를 잡는 퍼블리싱을 담당하셨다. 그러다보니 자연스레 시간이 지나면서 내 일이 끝나고 다음 일을 할 때에도 백엔드에서 계속 상주하는 것이 개발 속도에서도 더 빠를 것 같아서 나는 줄곧 백엔드를 담당했다. 프론트 쪽에서는 Chakra라는 UI 라이브러리를 사용하였는데, 만약 내가 프론트도 같이 구현한다면 이 라이브러리에 대해 공식 문서를 읽으면서 사용 방법을 터득해야 하는데 이 과정에서도 시간이 소모된다. 게다가 이미 프론트 쪽에는 이미 모든 페이지들을 각자 담당하는 팀원분들이 계셨기에 내가 들어가기에도 애매했다. 이런저런 이유로 나는 개발에서는 백엔드만을 담당하게 되었다.
초기에 기획을 다하고 나니 사이트의 페이지가 별로되지 않음에도 불구하고 막상 자세히 살펴보면 백엔드를 어떻게 구성할지가 복잡하게 느껴졌다. 그래서 나는 별도로 아래 사진처럼 백엔드 로직 상상도를 그리기도 하였다. 최종 완성 단계와 비교해보면 다소 다른 부분도 있다.
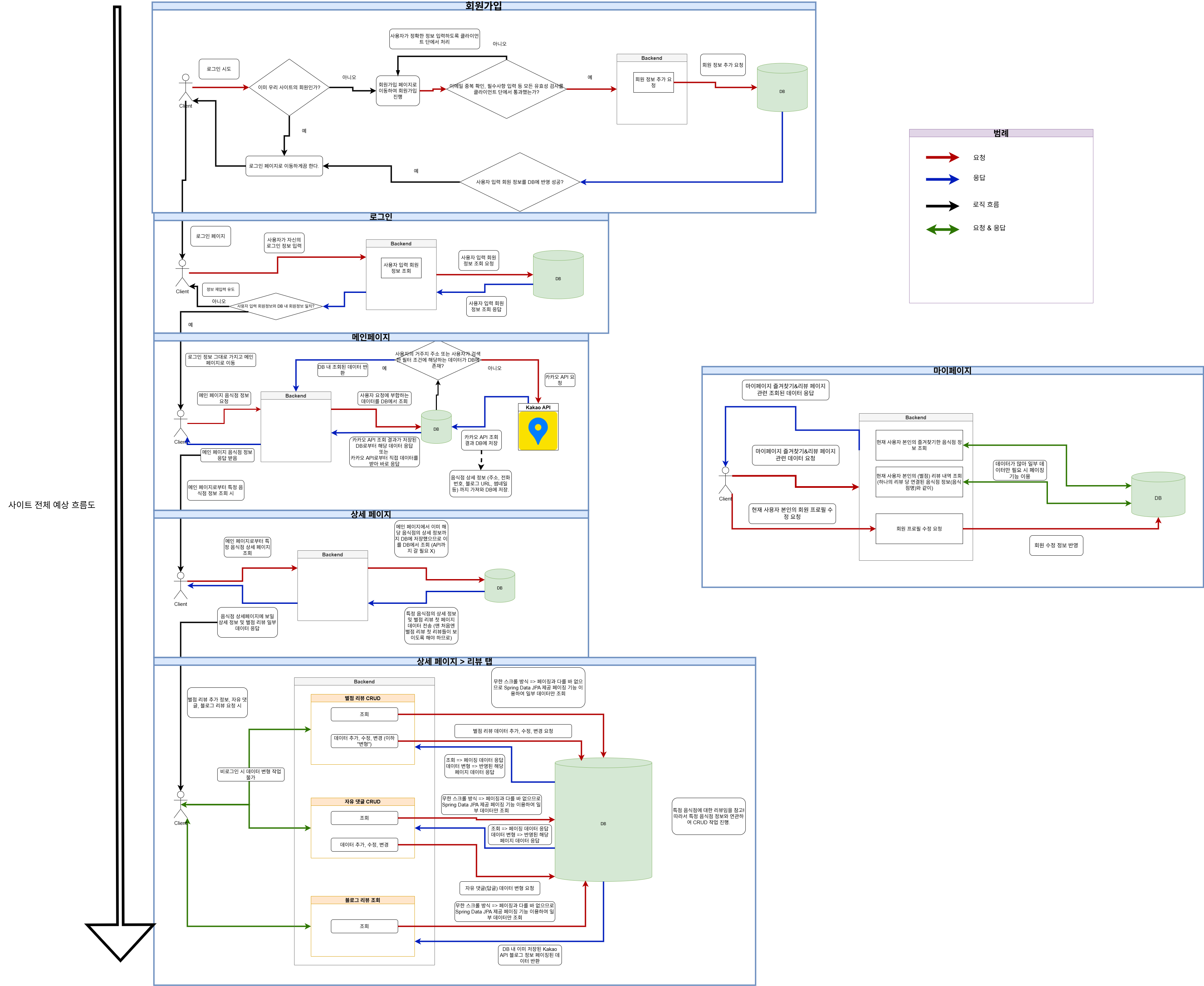
사진 3-1. 초기 백엔드 로직 구상도
백엔드를 담당하면서 주로 했던 작업은 크게 다음과 같이 있다.
- 외부 API로부터 데이터를 가져와 이를 DB에 저장.
- 이 과정 자체를 잘 설계해야 했음.
- 이 과정에서 Spring Cloud OpenFeign이라는 신기술을 접함.
- 음식점 정보, 지역 및 카테고리 정보 등 여러 정보들을 클라이언트에 제공할 수 있도록 REST API 형태로 구현
- 이 과정에서 DB로부터 원하는 데이터만 가져와야 하는 작업이 있어 Spring Data JPA 및 JPQL을 자주 다룸.
특히 첫 번째는 사실 나에게 아주 어려운 일이었다. 원래 나는 프론트 단에서 자바스크립트의 Fetch, Axios 등의 기술을 이용하여 API을 호출하여 데이터를 가져오고 이를 화면에 출력하는 기능만 알았다. 외부 API을 호출하여 얻은 데이터를 DB에 저장하는 방법은 전혀 알지 못했다. 그런데 이 팀 프로젝트에서는 그 기능이 필요했다. 사용자에게 맞춤으로 음식점들을 추천하기 위해선 우선 DB에 음식점 데이터 및 사용자가 어떤 음식점을 즐겨찾기 했는지 정보들이 저장되어 있어야 했다. 이를 위해선 외부 API로부터 가져온 데이터를 DB에 저장하는 것이 필수였다. 이 부분은 내가 맡아 진행하였다. 사실 자바에서 외부 API를 호출하여 데이터를 가져오는 방법에는 여러 가지가 있었으나 OpenFeign을 제외한 다른 방법들은 그 예시를 보니 전부 코드가 장황하다는 단점이 있었다. 반면 OpenFeign은 Spring Data JPA와 유사하게 인터페이스를 활용하며, 사용 방법도 Sprint Data JPA와 아주 유사하였고, 코드도 간결했기에 OpenFeign을 채택하였다. 이 기술은 처음 접하는 것이여서 잠깐 공부를 해야 했는데, 사실 이해하는 것 자체는 거의 하루 이틀만에 이해했다. 생각보다 사용법이 어렵지 않은 덕분이었다. 그래서 이를 최대한 이해하기 쉽게 내가 이해한대로 문서로 작성하였고, 다른 팀원들도 모두 볼 수 있는 노션 페이지에 내 개인 작업일지에 이를 올려 다른 팀원들도 언제든 볼 수 있도록 하였다.
이렇게 이해하는 건 어렵진 않았다. 물론 공식 문서를 보면 더 깊숙한 내용들이 있었던 걸로 아는데, 우리의 목표는 단순히 외부 API로부터 데이터를 가져와 이를 DB에 저장하는 것만이 목적이었기에 심화 내용들까지 살펴보진 않았다.
그런데 문제는 전혀 다른 데에 있었다. 그것은 외부 API로부터 데이터를 가져와 DB에 저장하고, 이를 클라이언트에 전송하는 시스템 구축의 설계 문제였다. 나는 맨 처음에 DB를 일종의 캐시(Cache) 서버처럼 활용하고자 하였다. 매번 음식점 정보가 필요할 때마다 프론트단에서 직접 외부 API에 요청을 하는 방식은 외부 API에 자칫 너무 많은 요청을 하게 되어 해당 사이트에서 지정한 API 요청 할당량을 초과할지도 모른다는 판단에서였다. 그래서 만약 DB에 저장되지 않은 음식점이라면 이를 API에 요청하여 가져오는데, 이 때 가져온 데이터를 DB에도 저장하도록 구상하였다. 그리고 만약 DB에 이미 해당 음식점이 있다면 외부 API를 요청하지 않고 바로 DB로부터 음식점 정보를 가져와 클라이언트(프론트)에 전송하도록 구상하였다. 외부 API로부터 가져올 수 있는 음식점 정보는 주소, 전화번호 등의 기본적인 정보라서 오히려 이런 정보들은 시간이 지나도 잘 안 바뀔 것이라 가정하였다. 그래서 최신 정보 업데이트 문제는 그리 큰 문제는 아니라고 생각하였다. 만약 SNS처럼 1분 1초가 지나도 바로 상태가 변하는 종류의 데이터였다면 이러한 구조는 큰 문제였겠지만 음식점의 기본 정보는 체감상 잘 안 바뀐다고 판단해서 내린 결정이었다.
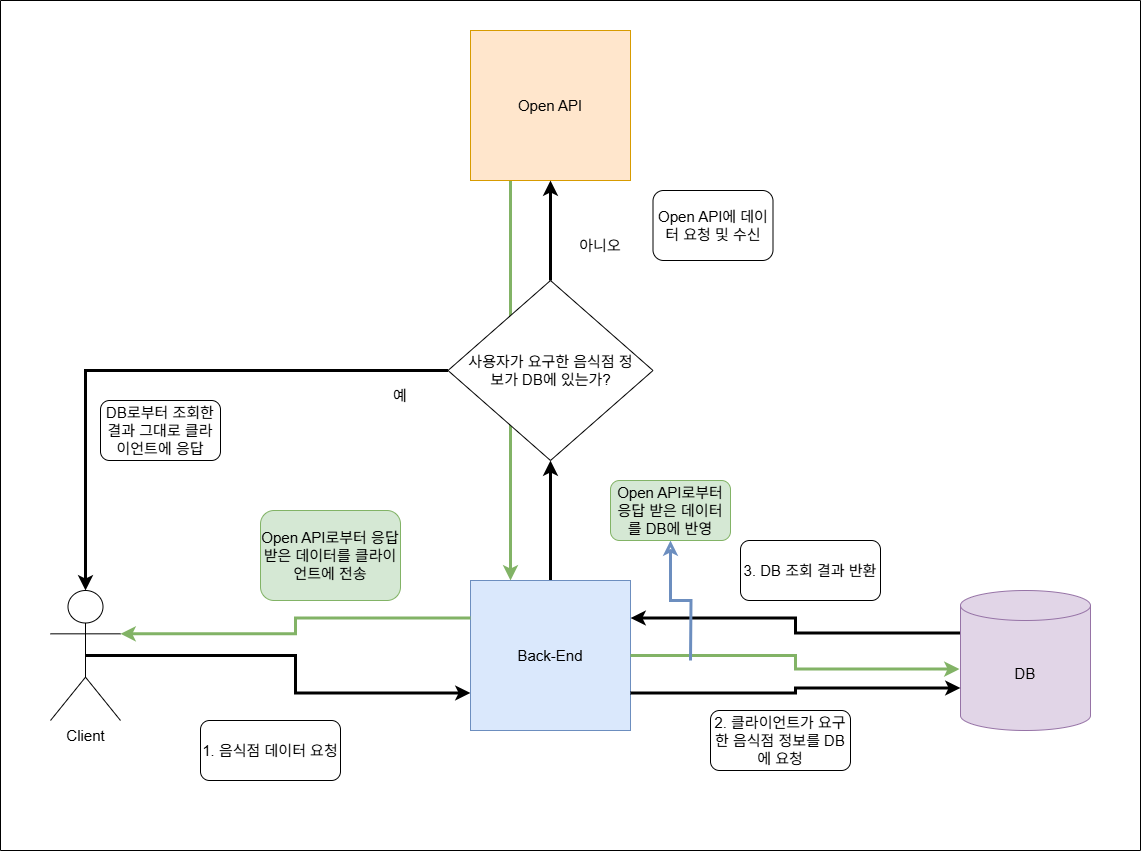
사진 3-2. Open API - DB 연동 시스템 초기 구상도. 지금와서 보면 DB로부터 데이터를 조회하여 클라이언트에 전송하는 “파이프라인”과, Open API로부터 데이터를 가져와 이를 DB에 반영하면서 동시에 클라이언트에 전송하는 “파이프라인”이 뒤엉켜 구조가 매우 복잡하다…
그런데 이를 막상 코드로 구현하다보니 생각보다 어려웠고, 여러 가지 문제점이 있었다.
- 만약 클라이언트에서 “서울 강남구” 지역의 음식점 15개의 정보를 요구한다고 해보자. 그런데 DB를 보니 해당 지역의 음식점 데이터들이 10건이 있다고 하자. 그러면 나머지 5개의 데이터는? 이는 어쩔 수 없이 외부 API를 요청하여 가져올 수밖에 없다. 즉, 한 번의 요청에 대해 DB로부터 데이터를 가져오는 작업과 API를 요청하여 데이터를 가져오고 이를 DB에 반영하는 작업까지 겹치다보니 설계가 굉장히 복잡해지고, 따라서 코드도 스파게티 코드마냥 엄청나게 복잡해졌다.
- 초기 데이터가 없다. 화면에 보여줄 초기 데이터가 없어서 휑하다. 사용자가 일일히 지역 주소를 입력하여 검색해야 그제서야 외부 API로부터 데이터를 가져오는 방식이기 때문이다. 이러한 방식은 지역 및 음식점 카테고리 검색을 위한 필터에서 검색 용어를 미리 마련할 수 없다는 문제점도 있다.
이 과정에서 생각보다 설계 및 코드가 너무 복잡해져 며칠이면 끝날 것을 1주일이나 걸렸었다. 그나마 이전에 더미 데이터를 미리 DB에 넣었기에 다른 분들은 그 더미 데이터를 토대로 작업을 할 수 있었으니 망정이지, 더미 데이터조차 없었다면 다른 팀원들의 작업도 늦어질 수도 있었던 상황이었다.
이 문제는 나중에 멘토링 과정에서 해결할 수 있었다. 멘토님도 이러한 문제점을 지적하셨고, 그렇기에 차라리 처음부터 과감하게 대용량의 데이터를 API로부터 가져와 DB에 저장하도록 하고, 클라이언트에서 요청이 오면 무조건 DB에 있는 데이터만 가져와 응답하도록 하는 구조로 하는 게 좋지 않겠냐는 제안을 하셨다. 멘토님 말씀을 따르니 확실히 코드 구조가 이전보다는 훨씬 단순해졌고, 덕분에 문제가 빨리 해결되었다. 좀 더 자세히 말하자면, REST API에서 요청 파라미터로 “서울 강남구”와 같이 특정 지역 주소를 입력하면 그 지역에 해당하는 음식점 데이터를 Open API에 요청하여 가져온 다음 이를 DB에 저장시키는 구조로 설계하였다. 이렇게 상대적으로 간단해진 구조와 더불어 이제는 한꺼번에 대용량의 데이터를 Open API로부터 가져올 수 있었기에 결과적으로 1,000여건이 넘는 음식점 데이터들을 DB에 저장할 수 있었다. 서울 전 지역과 경기 일부 지역의 음식점 데이터를 저장할 수 있었다. 그리고 우리 팀이 사용했던 Open API는 Kakao API였는데, 생각보다 허용된 API 호출량이 꽤 넉넉해서 대용량의 데이터를 가져와도 내가 우려했던 문제가 발생하지 않았다. 앞으로도 외부 API로부터 데이터를 가져와 백엔드에서 처리할 일이 있으면 이렇게 차라리 대용량의 데이터를 한꺼번에 호출하여 가져오는 방법을 적극적으로 고려해봐야겠다.
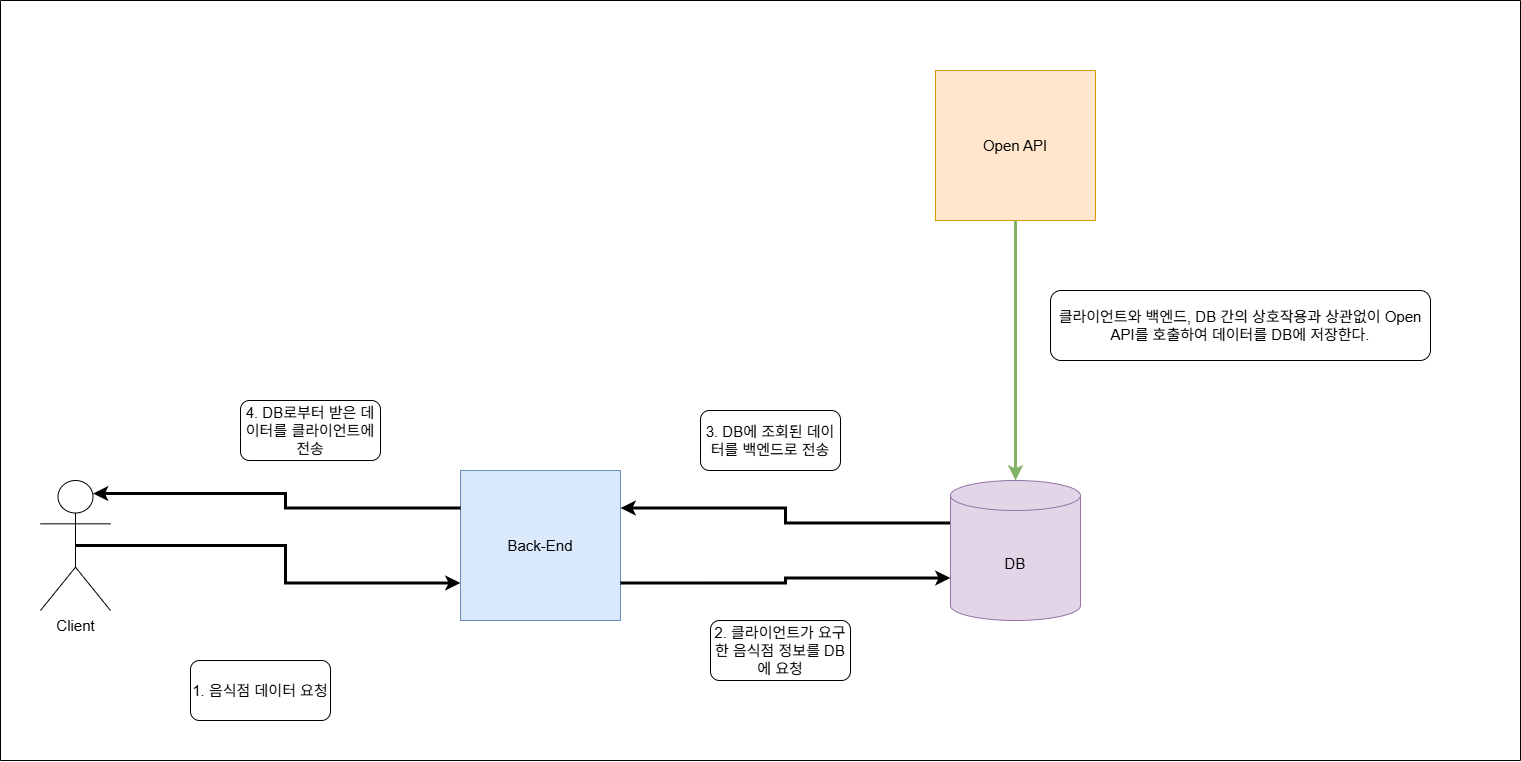
사진 3-3. Open API - DB 연동 시스템 최종 결정된 구조. 클라이언트가 데이터를 요청하여 이를 DB로부터 가져오는 과정과, Open API로부터 데이터를 가져와 DB에 반영하는 과정을 분리하였다. 이렇게 하니 확실히 코드 구조가 더 간결해졌다.
이후에는 클라이언트에서 원하는 데이터를 REST API 형태로 응답할 수 있게끔 하기 위해 Spring Data JPA를 이용하여 DB에 접근하는 작업을 많이 하였다. 이 과정에서 Jpa Repository에서 쿼리 메서드를 작성하거나 JPQL을 작성하고, 테스트를 위해 Native SQL를 작성하여 Heidi SQL 프로그램 상에서 쿼리문을 실행할 기회가 많았다. 그러다보니 Spring Data JPA와 SQL에 대해 더 깊숙히 이해할 기회가 되었다. 특히, JPA에서는 기존 DB 내 테이블과 매핑하기 위해 이와 똑같은 형태로 Entity를 작성하게 되는데, 두 테이블이 참조 관계라서 한 쪽 테이블에 외래 키(FK)가 걸린 필드가 존재할 때, 자식 테이블에 데이터를 넣기 위해서는 반드시 부모 테이블에 이미 존재하는 데이터 중 하나를 참조하는 데이터도 같이 넣어야만 삽입할 수 있다. 예를 들어 이것이 부모 테이블에 PK가 걸린 int형 필드일 경우 자식 테이블에서는 parent_no = 3 처럼 부모 테이블의 PK 필드에 해당하는 그 값만 집어넣으면 자식 테이블에 새 데이터를 넣을 수 있었다. 하지만 JPA에서는 이 과정을 어떻게 처리하는 지 잘 이해하지 못했었다. 그래서 FK가 걸린 필드명을 그대로 JPQL에 작성하여 자식 테이블에 넣을 새 데이터를 삽입하도록 했지만 그런 필드명은 존재하지 않는다며 삽입이 되지 않았었다. 그런데 사실 값만 넣는 것이 아니라 부모 엔티티 객체 자체를 넣어야만 삽입이 가능하다는 것을 깨닫게 되었다. 이에 대해선 나중에 별도의 글에서 다뤄보도록 하겠다.
그리고 자꾸 SQL, JPQL을 다루다보니 오히려 이 쪽에 관심이 생기기 시작했다. 간단한 쿼리문만으로도 복잡해보이는 조건의 데이터들을 쉽게 추출할 수 있다는게 큰 매력이었다. 나중에 SQLD를 딸까, 생각이 들 정도였고, 한 번 도전해봐야겠다.
그리고 REST API로 응답할 때 컨트롤러와 서비스 단에서 코드를 어떻게 구성할지에 대해서도 고민할 수 있었던 기회가 되었다. 고민 끝에 나는 일관적인 응답을 위해 별도의 DTO를 만들어 status, message, data라는 세 가지 필드를 만들어 에러가 나건 성공적으로 데이터를 전송하건 간에 이 세 필드는 그대로 고정시키도록 하였다. 성공적으로 데이터가 조회되면 status는 “OK”, message에서도 성공했다는 메시지를 담도록 하였고, 에러가 났으면 status는 “NOT FOUND”, message에서도 에러가 난 이유를 설명해주는 방식을 취하였다. 이렇게 하면 어떤 경우가 되더라도 클라이언트 측에서는 경우에 따라 응답 메시지 내 특정 필드가 있다가 없을 때를 대비하는 별도의 코드를 작성하지 않아도 되기에 프론트엔드 측에서 혼란이 생기지 않도록 하는 응답 데이터 구조를 고안할 수 있었다.
또한 서비스 측에서는 하나의 서비스 메서드 내에서 여러 엔티티들의 JpaRepository로부터 순차적으로 데이터를 조회하거나 삽입할 때가 있는데, 각각의 repository에서 데이터가 조회되지 않는 경우도 있을 것이다. 예를 들어 특정 음식점 카테고리에 해당하는 음식점을 조회하는 서비스 메서드를 작성한다고 하고, 음식점 카테고리에 해당하는 Categories 엔티티와 음식점에 해당하는 Eateries 엔티티가 있다고 해보자. 먼저 메서드 인자로 넘어오는 PK 번호에 해당하는 Categories 엔티티가 있는지 조회한 후, 있으면 그 카테고리에 해당하는 음식점 데이터를 가지는 Eateries를 조회하여 이를 반환하도록 구성할 수 있다. 이 과정에서 Categories 엔티티가 조회되지 않을 수 있고, Eateries가 조회되지 않을 수 있다. 이러한 경우에 대해서도 클라이언트 측에서 쉽게 파악할 수 있도록 각각 NoCategoryException, NoEateryException 등의 커스텀 예외 클래스를 만들어 예외를 throw하도록 하였다. 그리고 이를 controller 단에서 try ~ catch로 처리하게끔 하고, NoCategoryException일 경우 응답 데이터의 message로 “입력한 카테고리는 존재하지 않습니다”가 출력되도록 하고, NoEateryException일 경우 “조회된 음식점이 없습니다.”라고 출력하도록 고안하였다. 이렇게 하면 백엔드 로직을 전혀 모르는 클라이언트 측에서도 데이터가 조회되지 않았을 때 무엇 때문에 조회되지 않았는지 메시지만으로 단 번에 파악할 수 있도록 하였다.
이와 관련된 내용들은 나중에 별도의 글에서 자세히 다루도록 하겠다.
이처럼 REST API를 구축하는 방법에 대해서도 깊이 고민하고 이를 구현해볼 수 있었던 좋은 기회였다.
아무튼 정리하자면, 이번 팀 프로젝트를 통해 백엔드에서 어떤 구조로 코드를 작성할 것인지 고민해볼 좋은 기회가 되었다. 또한 SQL, JPQL을 자주 다뤄서 이에 대한 사용법도 어느 정도 능숙해질 수 있었다. 그래서 백엔드 연습의 좋은 기회가 되었다.
이후의 이야기 - 난 아직 목이 마르다
팀 프로젝트를 하면서 다른 이들과 소통, 협업하는 방법을 배울 수 있었다. 이는 분명 장점이다. 그럼에도 “난 아직 목이 마르다”
팀 프로젝트를 한 번 했으니 오히려 이번에는 개인 프로젝트의 시간을 가지는 게 좋을 것이란 생각이 들었다. 팀 프로젝트에서는 주로 다른 이들과의 협업에 중점을 맞췄다면 개인 프로젝트에서는 좀 더 개인 역량을 키울 수 있지 않을까, 라는 생각이 들었다. 무릇 개발자라면 간단한 사이트라도 혼자서 다 만들어볼 수 있어야하지 않나, 라는 생각이기 때문이기도 하다.
그리고 팀 프로젝트를 하면서 개인적으로 아쉬웠던 점들도 많았다.
- 팀 프로젝트가 매우 바쁘게 진행되어서 새로운 기술들을 접해볼 수가 없었다.
- 코드 작성 시 어떻게 해야 더 깔끔하고 체계적으로 작성할 수 있을지 계속 고민되었다.
- 특히 스프링 부트에서 컨트롤러와 서비스 단에서의 코드를 어떻게 작성할 지, 응답 데이터를 구성하는 쪽은 서비스 단에서 하는 게 나을지 컨트롤러에서 하는 게 나을지에 대한 의문도 계속 날 괴롭혔던 고민이었다.
그리고 개인적으로 한 번 접해보고 싶은 신기술들, 또는 제대로 다뤄보고 싶은 부문들은 다음과 같다.
- QueryDSL
- IntelliJ
- CRUD
- 사실 나는 팀 프로젝트 동안 단 한번도 CRUD 모두를 경험해본 적이 없다. 가장 많이 겪은 게 R(Read)였다. 그래서 CRUD 과정에서 부딪힐 수 있는 오류, 버그들을 경험하여 DB 연동 작업 기술을 더 향샹시키고 싶다.
- Spring Framework에서 제공하는 더 다양한 어노테이션들
- JUnit을 이용한 단위 테스트
- 서버 부하 테스트 및 Spring Actuator를 이용한 모니터링
- Spring Framework에서 코드를 더 간결하고 체계적으로 작성하는 방법.
- 제대로 된 문서화. Javadocs 적용.
- 서버 배포 과정
- 스스로 라이브러리를 만들고 이를 배포하는 방법
등과 같이 있다. 이러한 점들을 모두 개인 프로젝트에 녹일 것이다. 그리고 개인 프로젝트에서는 내가 정말 1인 사업자라는 마인드를 가지고 최대한 상업적인 또는 정말로 쓸만한 웹 사이트를 만드는 것이 내 목표이다.
This content is licensed under
CC BY-NC 4.0
![]()
![]()
![]()

댓글남기기