[Forklog] 전국 도로명 주소 DB에 넣기
이전 [Forklog] ERD 설계 - 생각보다 어렵고 헷갈렸던 DB 설계 글에서, DB에 전국 도로명 주소 데이터가 미리 있어야 했었기에 관련 데이터를 얻어 이를 DB에 삽입하였다는 것을 언급한 적이 있다. 이번 글에서는 이 과정에 대해 조금 더 자세히 말해보고자 한다. HeidiSQL이라는 GUI 프로그램에서 SQL만으로 대용량의 주소 데이터를 넣고 3개의 테이블로 원하는 데이터만 나눠져 들어가게끔 가공하였다. 이 과정이 필자에게는 쉽지 않았지만 이 작업을 완수하기 위해 여러 개의 쿼리문을 작성해야 했고, 덕분에 쿼리문 작성 연습에 도움이 된 것 같아 이를 기록하기 위함이다.
대용량 CSV 데이터를 DB에 삽입하기
회원 가입 시 사용자의 거주지 주소를 입력하는 부분이 있었는데, 그것을 카카오에서 제공하는 우편번호 서비스라는 것을 이용하기로 하였다.
이 사이트를 자세히 보면 행정안전부에서 제공하는 “도로명 주소” DB를 이용하고 있다고 한다. 그래서 나는 행정안전부 사이트로 가서 “도로명 주소” DB를 다운로드 받았다.
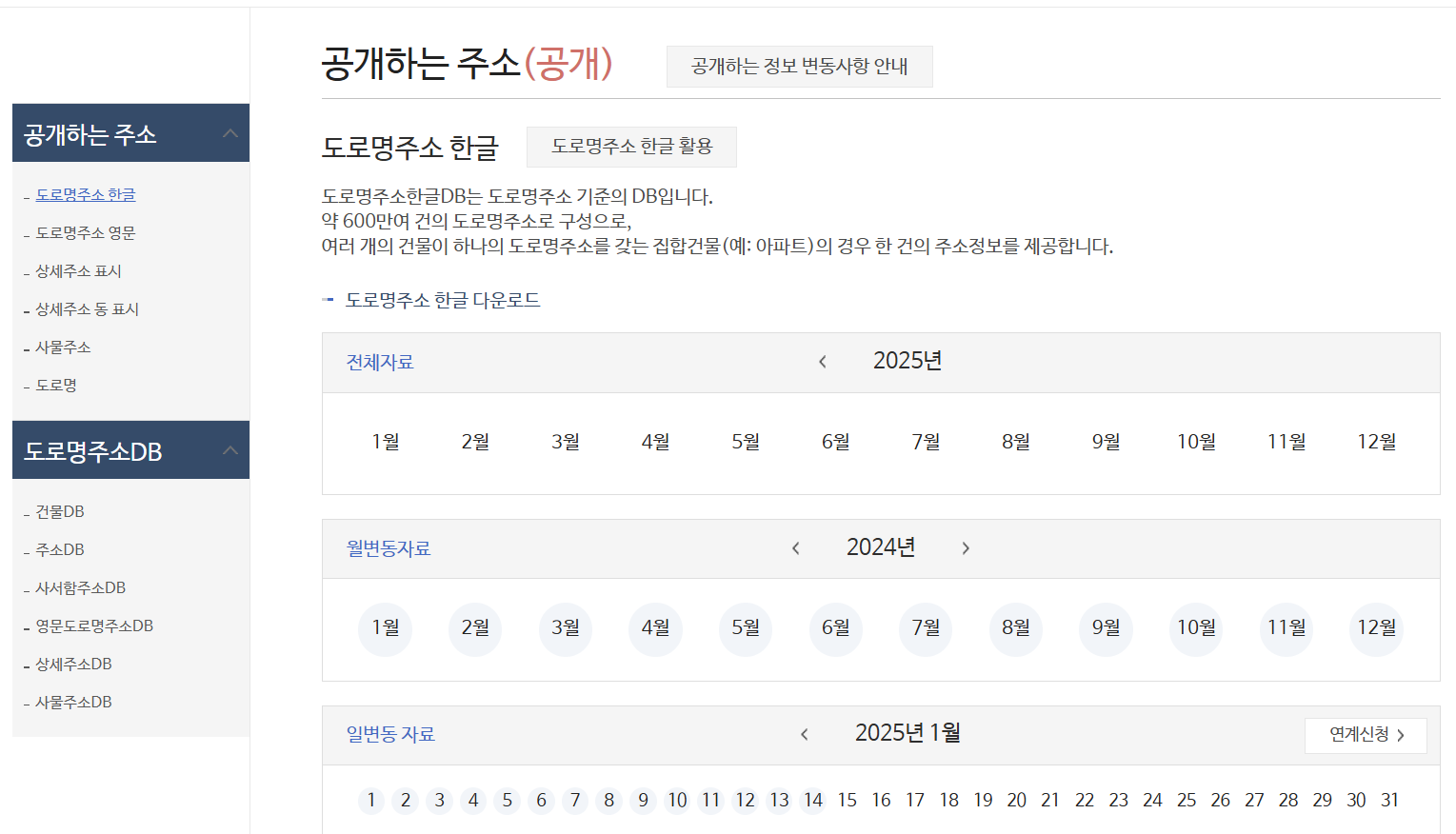
사진 1-1. 행정안전부에서 제공하는 도로명주소 데이터. 필자는 위 화면에서 “월변동자료” → 2024년 11월을 택하여 zip파일로 다운로드 받아서 진행하였다. 그 때 당시의 최신 데이터가 11월까지만 나왔었기에 해당 월을 택했다.
말이 DB지, 사실은 모두 CSV 파일로 작성되어 있었다. 서울, 경기 등 우리나라 행정구역을 크게 보면 총 17개의 지역이 있다. 그래서 CSV 파일도 각 지역별로 나눠져 있어 17개의 파일들이 있었다.
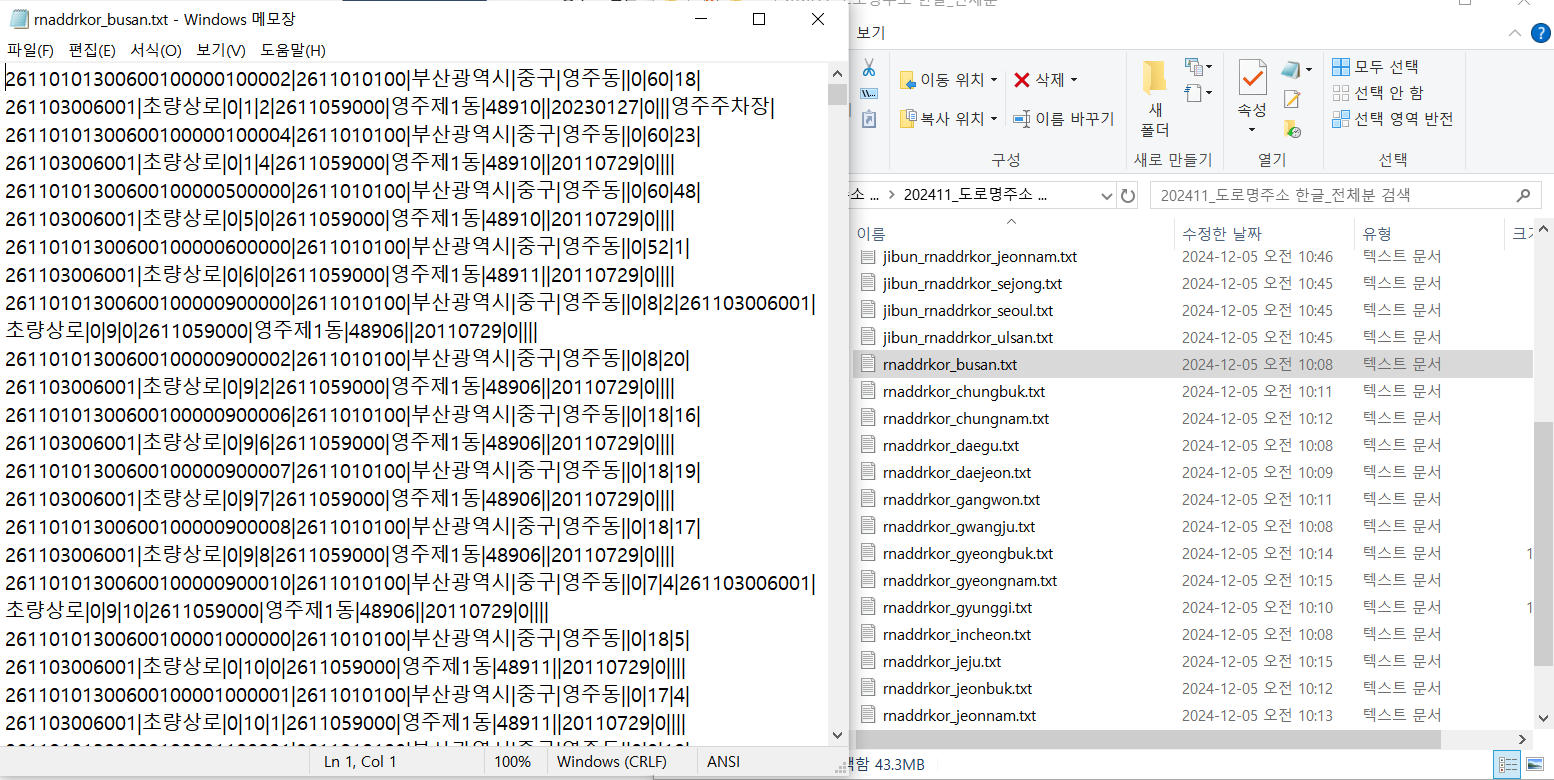
사진 1-2. 행안부 사이트에서 다운로드 받은 도로명 주소 CSV 파일들. 지번 주소까지 포함되어 있어서 총 34개의 txt 파일들이 있다. 필자는 도로명 주소만 필요했기에 “rnaddrkor”로 이름이 시작되는 txt 파일들만 취급했었다.
그런데 이 당시 나는 CSV로 작성된 데이터들을 어떻게 DB에 넣어야 하는지 잘 몰랐었다. 그래서 조사를 해봤는데, 내가 평소 쓰던 HeidiSQL 프로그램에서 이러한 기능이 있다는 것을 알게 되었다.
HeidiSQL에서 CSV 파일을 불러와 DB에 저장하는 방법
-
아래 사진처럼 상단 메뉴에서 [도구] → [CSV 파일 가져오기]를 클릭한다.
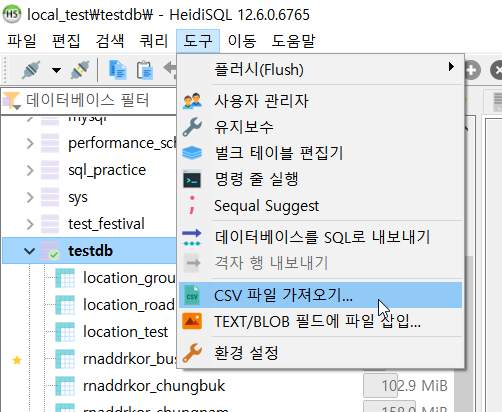
사진 1-3.
-
그러면 아래 사진처럼 “문서 파일 가져오기”라는 새 창이 뜬다. 여기서 “파일명”에서 가져오고자 하는 CSV 파일 경로를 택한다. 필자가 실험해봤을 때, 인코딩은 “euckr: EUC-KR Korean”으로 해야 문제없이 가져올 수 있었다. ”제어 문자” 영역에서 CSV 파일 내 데이터를 구분하는 구분자를 “필드 종결자”에 넣는다. 필자의 경우, 해당 CSV 파일이 “|”로 구분되어 있었다. 그리고 필자의 경우 “필드를 감싸는 구분자”와 “필드를 벗어나는 구분자”에 아무것도 넣지 않아야 HeidiSQL에서 CSV 파일을 제대로 인식할 수 있었다. ”목적지” 영역에서 가져온 데이터를 어느 DB 및 테이블에 저장할 것인지 선택할 수 있다. 처음에는 도로명 주소를 담을 테이블이 없어서 아래 사진처럼 “테이블”에서 “<새 테이블>”을 클릭하여 새 테이블을 만들어 그곳에 데이터를 담기로 하였다.
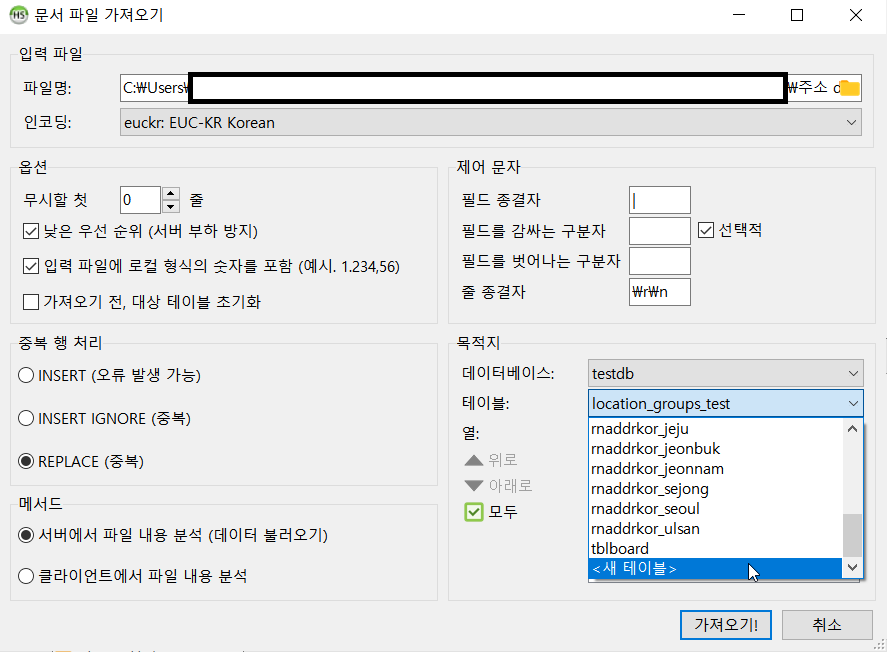
사진 1-4.
-
“<새 테이블>” 클릭 시 다음과 같은 새 창이 뜬다. 여기서 CSV 파일 내 데이터들의 컬럼 수와 자료형에 맞게 컬럼들을 정의하고 새 테이블을 생성하면 된다.
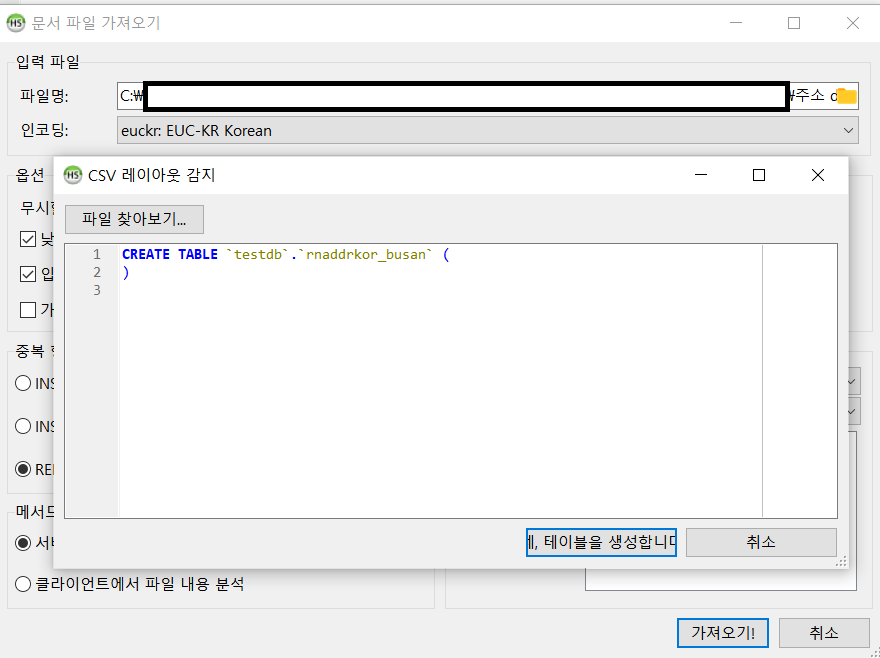
사진 1-5.
위 과정을 거치면 다음과 같이 DB에 데이터들을 담을 수 있게 된다.
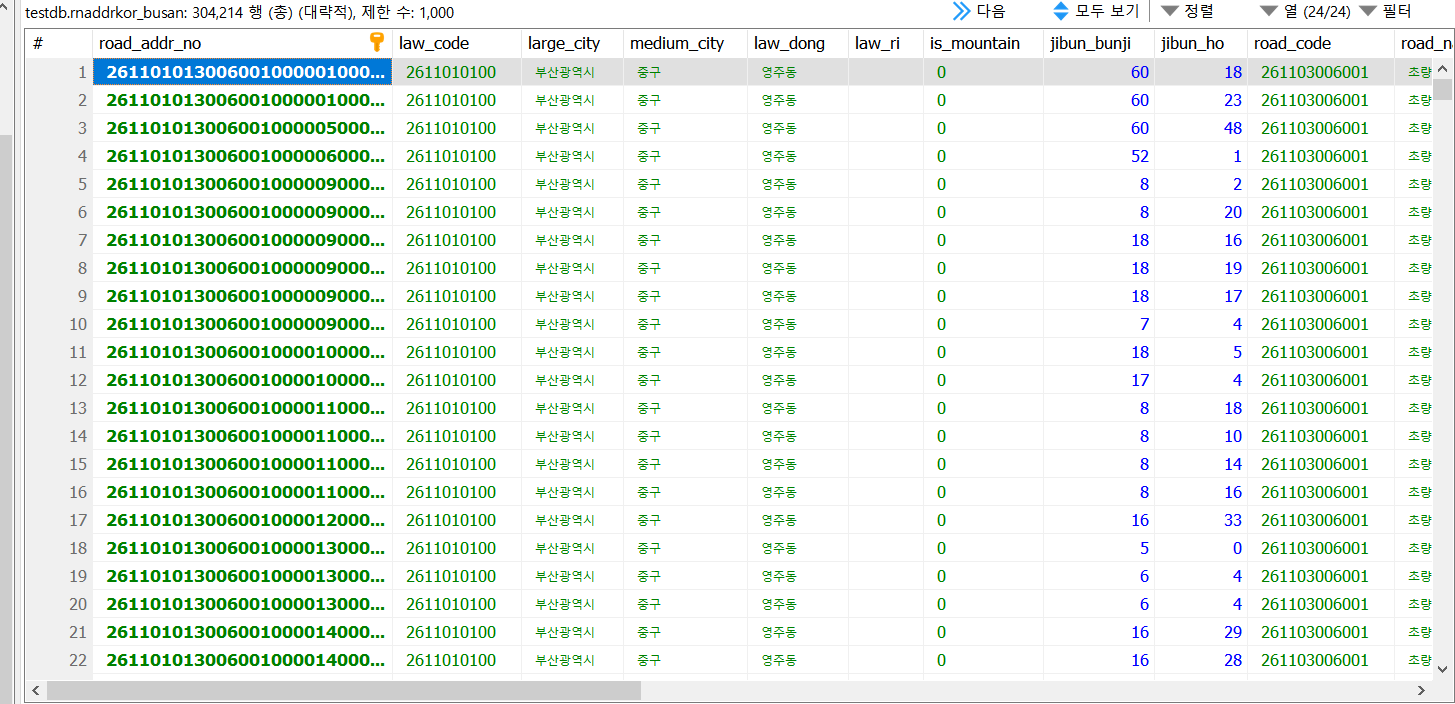
사진 1-6. 부산 지역 도로명 주소 데이터가 담긴 CSV 파일로부터 데이터를 가져와 이를 DB에 저장한 결과.
참고로 컬럼 수 및 이름, 컬럼 자료형은 행정안전부에서 제공하는 자료를 토대로 구성하였다.
CREATE TABLE `rnaddrkor_busan` (
`road_addr_no` VARCHAR(26) NOT NULL COLLATE 'utf8mb4_general_ci',
`law_code` VARCHAR(10) NULL DEFAULT NULL COLLATE 'utf8mb4_general_ci',
`large_city` VARCHAR(40) NULL DEFAULT NULL COLLATE 'utf8mb4_general_ci',
`medium_city` VARCHAR(40) NULL DEFAULT NULL COLLATE 'utf8mb4_general_ci',
`law_dong` VARCHAR(40) NULL DEFAULT NULL COLLATE 'utf8mb4_general_ci',
`law_ri` VARCHAR(40) NULL DEFAULT NULL COLLATE 'utf8mb4_general_ci',
`is_mountain` VARCHAR(4) NULL DEFAULT NULL COLLATE 'utf8mb4_general_ci',
`jibun_bunji` INT(4) NULL DEFAULT NULL,
`jibun_ho` INT(4) NULL DEFAULT NULL,
`road_code` VARCHAR(12) NULL DEFAULT NULL COLLATE 'utf8mb4_general_ci',
`road_name` VARCHAR(80) NULL DEFAULT NULL COLLATE 'utf8mb4_general_ci',
`is_base` VARCHAR(4) NULL DEFAULT NULL COLLATE 'utf8mb4_general_ci',
`building_main_code` INT(5) NULL DEFAULT NULL,
`building_sub_code` INT(5) NULL DEFAULT NULL,
`hangjung_code` VARCHAR(60) NULL DEFAULT NULL COLLATE 'utf8mb4_general_ci',
`hangjung_name` VARCHAR(60) NULL DEFAULT NULL COLLATE 'utf8mb4_general_ci',
`postal_code` VARCHAR(5) NULL DEFAULT NULL COLLATE 'utf8mb4_general_ci',
`before_road_addr` VARCHAR(400) NULL DEFAULT NULL COLLATE 'utf8mb4_general_ci',
`valid_date` VARCHAR(8) NULL DEFAULT NULL COLLATE 'utf8mb4_general_ci',
`is_common_house` VARCHAR(4) NULL DEFAULT NULL COLLATE 'utf8mb4_general_ci',
`why_move` VARCHAR(2) NULL DEFAULT NULL COLLATE 'utf8mb4_general_ci',
`building_name` VARCHAR(400) NULL DEFAULT NULL COLLATE 'utf8mb4_general_ci',
`city_building_name` VARCHAR(400) NULL DEFAULT NULL COLLATE 'utf8mb4_general_ci',
`etc` VARCHAR(200) NULL DEFAULT NULL COLLATE 'utf8mb4_general_ci',
PRIMARY KEY (`road_addr_no`) USING BTREE
)
COLLATE='utf8mb4_general_ci'
ENGINE=InnoDB
;
코드 1-1. 부산 지역 도로명 주소 데이터를 담기 위한 테이블 생성 구문. 위 코드는 HeidiSQL에서 테이블의 “CREATE 코드”를 발췌한 것이다.

사진 1-7. 도로명 주소 데이터를 담을 테이블 생성 시 참고한 행정안전부 제공 CSV 파일 컬럼 구성요소 정보.
사진 1-6을 자세히 보면 알겠지만, 부산 지역에서만 데이터가 약 30만 건이 존재한다. 가장 건수가 많았던 건 경기도 지역으로, 백만 건이나 존재했다. 평균적으로는 한 지역 당 약 30만 건 정도 되었으니 전국 도로명 주소 데이터의 총 개수는 약 5백만개로 추정된다. 이렇게 대용량의 데이터다 보니 메모장으로 해당 파일을 열 때에도 시간이 걸릴 정도였다. 그래서 하나의 테이블에 전국 데이터를 몰아 넣으면 혹시나 프로그램이 멈출까 걱정되기도 하였고, 3개의 주소 테이블로 나눠 담을 때 잘 들어가는지 확인하기 위해 지역별로 테이블을 만들어 위와 같은 과정을 반복하였다. 그래서 총 17개의 테이블을 만들어 데이터를 저장하였다. 참고로 이 테이블들은 기존 CSV 파일명을 그대로 따서 “rnaddrkor”로 시작하도록 테이블명을 지었다.
데이터 가공하여 원하는 데이터만 추출, 저장하기
이제 앞서 저장한 테이블로부터 원하는 컬럼의 데이터들만 추출하여 주소 테이블에 저장하는 과정이 남았다. 먼저 필자는 앞서 저장한 테이블로부터 각각 지역 주소의 대분류, 중분류, 도로명 및 건물 번호를 추출할 수 있는지 확인하기 위한 절차를 거쳤다. 그 결과 다음의 쿼리문을 통해 추출할 수 있음을 발견하였다.
SELECT
large_city AS 대분류,
medium_city AS 중분류,
CASE
WHEN law_ri = '' OR law_ri IS NULL
THEN road_name
ELSE
CONCAT(law_dong, ' ', road_name)
END AS 도로명,
CASE
WHEN building_sub_code = 0 -- 건물 부번
THEN building_main_code -- 건물 본번
ELSE
CONCAT(building_main_code, '-', building_sub_code)
END AS '도로명번호(건물본번및부번)'
FROM rnaddrkor_busan;
코드 2-1. 도로명 주소 테이블로부터 지역 주소의 대분류, 중분류, 도로명 및 건물 번호를 추출하는 쿼리문
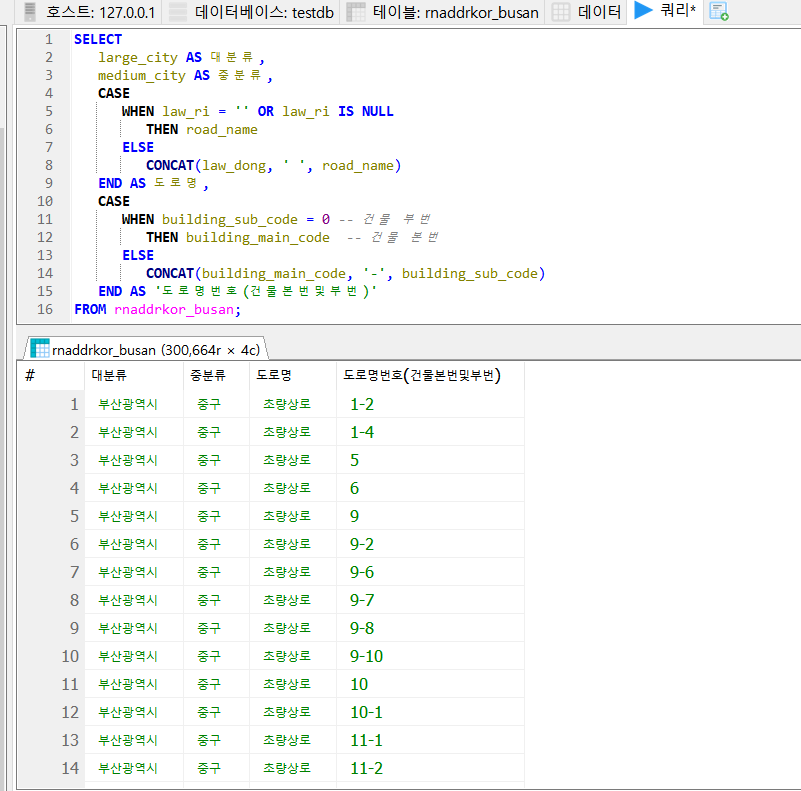
사진 2-1. 앞선 쿼리문을 통해 추출한 결과
참고로 쿼리문은 행안부에서 제공하는 도로명 주소에 대한 정보를 토대로 작성하였다.
![사진 2-2. 행정안전부 제공 도로명 주소 표기 예시. References [2] 참고](/images/2025-01-13/team-project-forklog-ERD%EC%84%A4%EA%B3%84-%EC%83%9D%EA%B0%81%EB%B3%B4%EB%8B%A4%20%EC%96%B4%EB%A0%B5%EA%B3%A0%20%ED%97%B7%EA%B0%88%EB%A0%B8%EB%8D%98%20DB%20%EC%84%A4%EA%B3%84/6.png)
사진 2-2. 행정안전부 제공 도로명 주소 표기 예시. References [2] 참고
위 사진과 같이, 도로명 주소 표기 방식, 특히 도로명과 건물 번호에서 경우의 수가 있었기에 CASE문을 작성할 수밖에 없었다. 초기에는 위 정보를 모른 상태로 쿼리문을 작성했다가 위 정보를 나중에서야 깨달아서 쿼리문을 수정했던 일도 있었다.
일단은 쿼리문을 통해 지역 주소의 대분류, 중분류, 도로명을 분리하여 가져올 수 있다는 가능성을 보았다. 여기서는 건물 번호는 필요없고, 도로명까지만 필요했기에 대분류, 중분류, 도로명 정보만을 가져와 3개의 테이블에 나눠 담는 일이 필요하였다.
참고로 이전 글에서도 보였지만, 3개의 테이블은 서로 부모 - 자식 관계의 테이블이라 부모 테이블에 없는 데이터를 자식 테이블에 넣을 수는 없는 구조라서 이에 주의하면서 데이터를 추출, 삽입해야 했다. 대분류 테이블이 중분류 테이블에 대한 부모 테이블이고, 중분류 테이블이 도로명 테이블에 대한 부모 테이블인 구조이다.
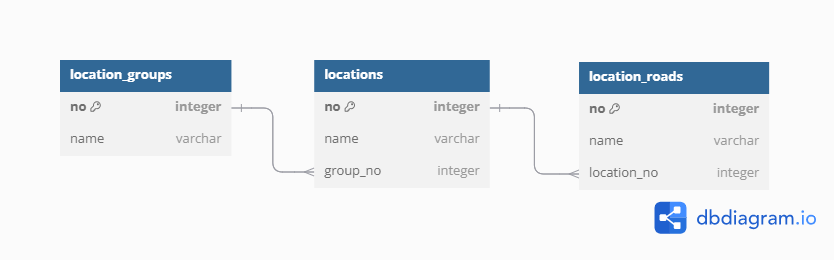
사진 2-3. 주소 테이블을 3개로 나눠 각각 부모 - 자식 관계로 이은 ERD 구조. location_groups가 대분류, locations가 중분류, location_roads가 도로명에 해당한다.
그런데 대분류의 경우 이미 17개로 정해져 있었기에 앞서 저장한 17개의 테이블로부터 추출할 필요도 없었다. 17개의 테이블에 적혀져 있는 대분류 이름만 참조하여 바로 다음과 같이 대분류 테이블에 넣을 데이터를 빠르게 구성할 수 있었다. 이 때 데이터는 앞서 소개한 카카오 제공 주소 검색 API에서 실질적으로 사용되는 이름을 사용했다. 예를 들어 “충청북도”의 경우 ‘충북’으로 사용되고 있어서 “충북’을 택하였다.
INSERT INTO 테이블 VALUES ('서울'),
('부산'),
('대구'),
('인천'),
('광주'),
('대전'),
('울산'),
('세종특별자치시'),
('경기'),
('충북'),
('충남'),
('전남'),
('경북'),
('경남'),
('강원특별자치도'),
('전북특별자치도'),
('제주특별자치도');
코드 2-2. 주소 대분류 테이블에 들어갈 17개의 데이터들.
이제 중분류 데이터를 넣을 수 있게 되었다. 그런데 중분류 데이터를 넣을 때 다음을 고려해야했다.
- 기존에 생성한 “rnaddrkor”로 시작하는 테이블로부터 중분류 데이터를 가져와야 한다.
- 대분류 테이블에 존재하는 데이터와 연관되도록 삽입해야 한다.
PK - FK 참조 관계에 있다는 점, 그리고 기존 테이블로부터 데이터를 가져와야 하는 구조여서 중분류 데이터 삽입 쿼리문을 떠올리기가 쉽지 않았다. 고생 끝에 나는 INSERT문 안에 SELECT문을 사용하여 기존 “rnaddrkor”로 시작하는 테이블로부터 데이터를 가져오도록 구성하고, PK - FK 참조 관계도 고려해야 했기에 Join문도 같이 사용해야 함을 깨달았다. 그래서 결국 다음의 쿼리문을 생성할 수 있었다.
-- 일반화된 코드
INSERT INTO location_test (NAME, group_no)
SELECT
origin.medium_city,
loc_g.`no`
FROM rnaddrkor_busan origin
INNER JOIN location_groups_test loc_g
-- 주소명의 처음 2단어만 일치해도 삽입 가능하도록 함.
ON SUBSTRING(origin.large_city, 1, 2) LIKE loc_g.group_name
GROUP BY origin.medium_city
;
코드 2-3. 기존 “rnaddrkor”로 시작하는 테이블로부터 특정 컬럼의 데이터들만을 가져와 중분류 테이블에 삽입하는 쿼리문.
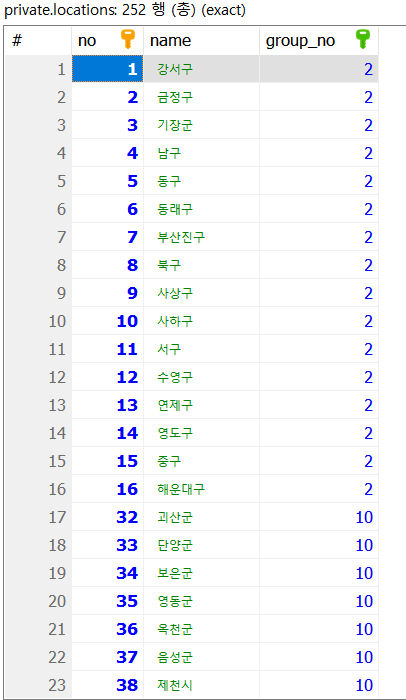
사진 2-4. 코드 2-3의 쿼리문 실행으로 주소 중분류 테이블에 삽입된 데이터들 일부.
생성된 중분류 데이터를 보면, “group_no” 컬럼은 이 중분류 레코드가 참조하고 있는 대분류 데이터의 no 컬럼을 가리키고 있는 것이다. 위 사진 2-4에서 맨 첫 번째 데이터인 “강서구”를 보면 “group_no”가 2인데, 지역 대분류 테이블에서 no 컬럼의 값이 2인 데이터가 “부산”이다. 따라서 이를 종합하면 “부산 강서구”가 되는 것이다.
지역 대분류 데이터(코드 2-2)를 보면 알겠지만, “rnaddrkor” 테이블에 저장되어 있는 지역 대분류명과 카카오 주소 검색 API에서 실제로 사용되는 대분류명이 다른 경우가 있어서 특정 대분류에 대해서는 조건문을 살짝 다르게 했어야 했다. 앞서 말했듯 한 쪽에서는 “충청북도”를 사용하고 있고, 또 다른 쪽에서는 “충북”이라고 사용하고 있다는 차이점 때문이다.
-- 충북
INSERT INTO location_test (NAME, group_no)
SELECT
origin.medium_city,
loc_g.`no`
FROM rnaddrkor_chungbuk origin
INNER JOIN location_groups_test loc_g
ON loc_g.group_name = '충북' -- 조건문
GROUP BY origin.medium_city
;
-- 강원
INSERT INTO location_test (NAME, group_no)
SELECT
origin.medium_city,
loc_g.`no`
FROM rnaddrkor_gangwon origin
INNER JOIN location_groups_test loc_g
ON origin.large_city = loc_g.group_name -- 조건문
GROUP BY origin.medium_city
;
코드 2-4. 지역 대분류마다 조건문을 달리한 데이터 삽입 쿼리문.
이번에는 도로명 주소 데이터를 삽입할 차례이다. 이 역시도 기존 “rnaddrkor”로 시작하는 테이블로부터 도로명 데이터를 가져오고, 중분류 테이블과 PK - FK 관계를 이루고 있다는 점들을 고려하며 INSERT문을 작성하였다.
INSERT INTO location_roads_test (NAME, location_no)
SELECT
CASE
WHEN law_ri = '' OR law_ri IS NULL
THEN road_name
ELSE
CONCAT(law_dong, ' ', road_name)
END AS final_road,
loc.`no`
FROM rnaddrkor_busan origin
INNER JOIN location_test loc
ON loc.name = origin.medium_city
GROUP BY final_road
;
코드 2-5. 도로명 테이블에 주소 데이터를 삽입하기 위한 쿼리문.
여기서 SELECT문의 CASE 구문은 앞선 코드 2-1의 “도로명” 컬럼을 그대로 가져와 작성하였다.
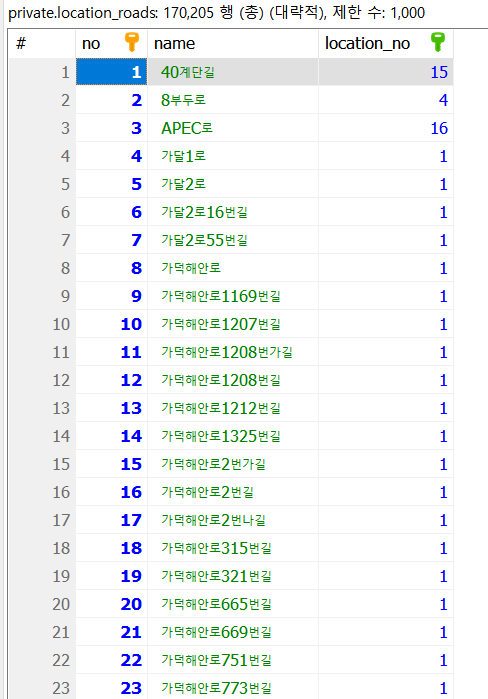
사진 2-5. 지역 도로명 테이블에 데이터를 삽입한 결과
위 사진 2-5에서 맨 첫 번째 데이터인 “40계단길”을 에로 들면, “location_no”가 15인데, 이는 지역 중분류 테이블에서 PK 키가 걸린 “no” 컬럼의 값이 15인 레코드를 참조하고 있다는 뜻이다. “no = 15”인 키는 “중구”라는 중분류명을 가지고 있으며, 이는 “부산”에 해당하는 지역이다. 그래서 종합하면 “부산 중구 40계단길”이라는 전체 도로명 주소를 가져올 수 있게 되는 것이다.
3개로 나눠진 데이터를 하나로 합쳐 조회하기
외부에서 가져온 데이터로부터 원하는 조건의 데이터만을 가져와 기존에 설계했던 주소 관련 3개의 테이블에 삽입하는데 성공하였다. 나중을 위해서는 3개의 테이블로 나뉘어진 주소 데이터들을 하나로 합쳐 전체 도로명 주소를 구성하는 법도 알아두는 게 좋다고 판단하였다. 그래서 연구 끝에 다음의 쿼리문을 통해 3개의 테이블로부터 전체 도로명 주소를 구성하는 방법을 체득하였다.
-- 1번째 쿼리문. 대분류, 중분류, 도로명 컬럼으로 나눠서 조회하고자 하는 경우
SELECT
loc_g.group_name,
loc_test.name,
loc_road.name
FROM location_roads_test loc_road
INNER JOIN location_test loc_test
ON loc_road.location_no = loc_test.no
INNER JOIN location_groups_test loc_g
ON loc_test.group_no = loc_g.`no`
;
-- 2번째 쿼리문. 하나의 컬럼으로 합쳐 조회하고자 하는 경우.
SELECT
CONCAT(loc_g.group_name, ' ', loc_test.name, ' ', loc_road.name) AS full_address
FROM location_roads_test loc_road
INNER JOIN location_test loc_test
ON loc_road.location_no = loc_test.no
INNER JOIN location_groups_test loc_g
ON loc_test.group_no = loc_g.`no`
;
코드 3-1. 주소 관련 3개의 테이블로부터 전체 도로명 주소를 구성하여 조회하는 쿼리문
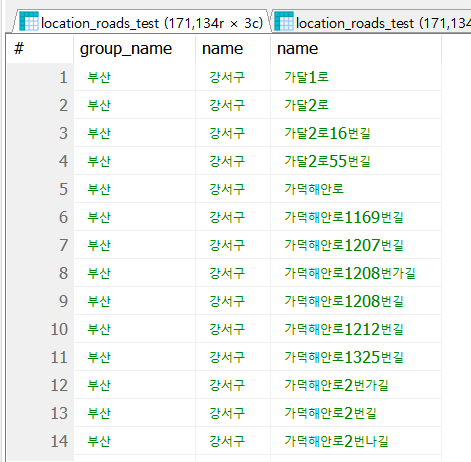
사진 3-1. 코드 3-1의 1번째 쿼리문 실행 결과
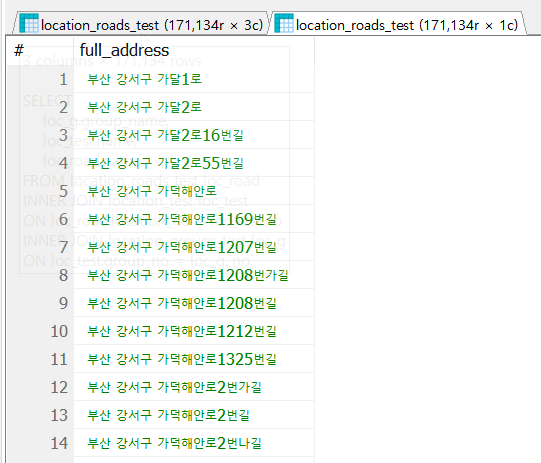
사진 3-2. 코드 3-1의 2번째 쿼리문 실행 결과
주소 데이터 구축 결과
위 과정을 거쳐 주소 데이터를 구축한 결과는 다음과 같다.
- 건물 번호까지는 필요 없어서 도로명까지만 추출하여 DB에 저장했다. 건물 번호는 나중에 회원 및 음식점 테이블에 별도의 컬럼으로 넣는게 더 낫다는 판단에서였다. 그 결과 행안부에서 제공하는 전국 도로명 주소는 전체 약 5백만 건이었는데, 건물 번호를 빼니 전체 17만 건으로 대폭 축소하여 DB에 구축할 수 있었다. 행안부 제공 데이터를 모두 DB에 넣었을 때에는 1.7GB 용량이었는데 이를 13MB로 줄일 수 있었다.
- 3개의 테이블로 나누는 정규화를 거치니 중복 데이터를 방지할 수 있었다. 만약 데이터가 중복되게끔 그냥 하나의 테이블에 몰아 넣었다면 반복되는 문자열 데이터에 의해 전체 차지하는 용량이 더 컸을 거라 예상된다. 특히나 대용량의 데이터를 다뤘으니 그 차이가 더 선명히 보였을거라 예측한다.
구축한 데이터베이스 .sql 파일로 가져오기
사실 위 과정은 모두 혹시 모를 실수를 방지하기 위해 내 로컬 환경에서 구축한 것이었고, 우리 팀에서는 별도로 Cloudtype이라는 클라우드 서버에 DB을 운영하고 있기에 내 로컬 환경에 구축한 DB를 클라우드 서버로 옮겨야 했다. 이 과정은 생각보다 쉬운데, 이미 구축한 DB 데이터들을 .sql 파일로 내보내기만 하면 되기 때문이다.
HeidiSQL 프로그램을 이용하여 기존 DB 데이터들을 .sql 파일로 내보내는 방법
-
상단 메뉴에서 [도구] → [데이터베이스를 SQL로 내보내기]를 클릭한다.
사진 4-1.
-
그러면 다음과 같은 창이 뜬다. 왼쪽 목록에서는 내보내고자 하는 테이블들을 선택할 수 있다. 오른쪽 메뉴에서는 어떻게 SQL 파일을 내보낼 것인지 옵션을 정할 수 있다. 설정을 다했으면 아래 “내보내기” 버튼을 누르면 된다. 그러면 “파일명”에 명시한 위치에 .sql 파일을 다운로드 받을 수 있다.
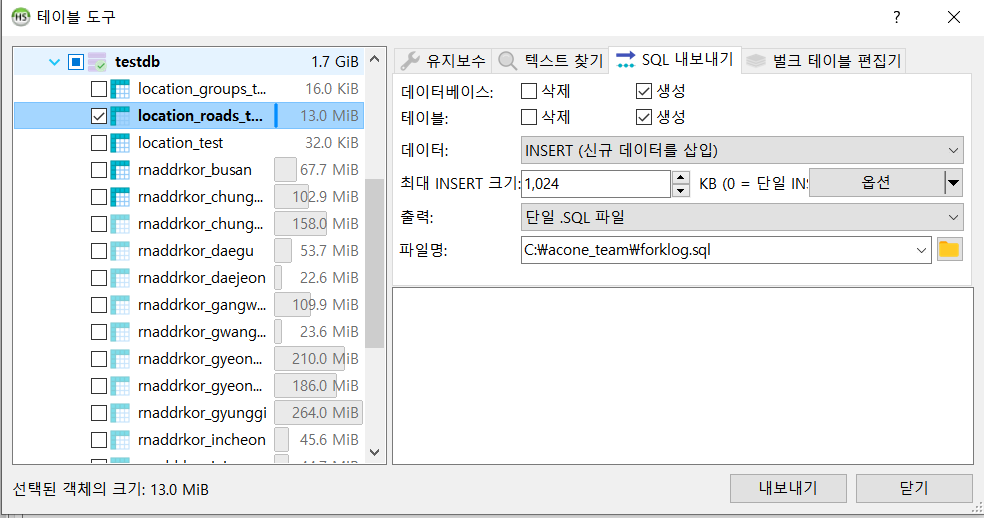
사진 4-2
위 사진대로 했을 때 다운로드 받은 SQL 파일을 보면 대부분 CREATE 및 INSERT 구문으로 구성되어 있다. 이렇게 내보낸 SQL 파일을 토대로 다른 DB로 옮기든가 할 수 있는 것이다.
글을 마치며
사실 이전 글에서도 언급했듯, 결과적으로는 위에서 구축했던 3개의 주소 테이블은 지역별 음식점 검색을 위한 지역 검색 필터 구성을 제외하면 그 외 원래 의도했던 용도로는 사용할 수 없게 되었다. 이에 대한 자세한 이야기는 이전에 작성한 글인 [Forklog] ERD 설계 - 생각보다 어렵고 헷갈렸던 DB 설계 글을 참고하면 되겠다.
그리고 사실 지금와서 보면 조금 아쉬운 게, 저 17개의 테이블들을 일일이 생성하고 쿼리문으로 데이터를 넣는 수작업으로 진행했는데, 이 과정 자체도 자동화할 수 있지 않았을까, 라는 생각도 든다. 그 때 당시에는 시간이 별로 없어 급한 마음에 쿼리문으로 데이터 삽입이 가능하다는 걸 알자마자 바로 그 방식을 이용하였는데, 사실 기억해보니 파이썬이나 Node.js에서 CSV를 다루는 라이브러리가 있어 이를 이용하면 DB와 연동하여 자동화를 할 수 있었지 않았을까, 라는 생각이 든다. 그래서 이 부분은 살짝 아쉬운 부분이다.
그럼에도, 사실 강의 시간 때 말고는 SQL을 직접적으로 다룰 일이 없었는데 이 과정에서 SQL을 다룰 수 있게 되어서 좋은 연습이 되었다. 사실 팀 프로젝트에서는 Spring Data JPA를 사용하였고, 결과적으로는 Native SQL을 단 한 번도 사용하지 않아서 Native SQL을 다룰 기회가 없었다. 거기에 더해, 약 5백만 여건이나 되는 대용량의 데이터를 SQL로 다뤄보는 경험은 더더욱 흔치 않은 기회일 것이다. 그렇기에 오히려 Native SQL을 집중적으로 연습해볼 소중한 기회가 아니었나 싶다. 이것과 더해 JPA에서 JPQL도 몇 번 다뤄봤기에 팀플 직후 SQL에 대한 관심이 생기게 되었다. 나중에 기회가 되면 SQLD라는 자격 시험이 있던데, 이것도 따볼 수 있으면 좋겠다.
References
[1] 카카오 다음 제공 우편번호 서비스 - 주소 검색 서비스
[2] 행정안전부 - 도로명 주소
This content is licensed under
CC BY-NC 4.0
![]()
![]()
![]()

댓글남기기