[SQL][DB] Client 프로그램 이용 및 SELECT문
Heidi SQL 사용하기
DBMS의 클라이언트 프로그램으로 CLI(Command Line Interface) 방식과 GUI(Graphic User Interface) 방식이 있다. CLI 방식은 이전 글에서 보인 cmd 창처럼 오로지 텍스트로만 컴퓨터와 상호작용하는 방식이고, GUI 방식은 프로그램을 시각적으로 보여줘서 사용자가 좀 더 편리하게 사용할 수 있는 방식이다.
여기서는 cmd 콘솔창을 이용하는 방법 대신 GUI 방식을 사용하는 DBMS 클라이언트 프로그램 중 하나인 Heidi SQL을 사용할 것이다. 이것이 쿼리문을 입력하고 실행, 그 결과를 볼 때 더 편리하기 떄문이다.
Heidi SQL 프로그램은 사실 MariaDB 설치 및 접속 과정 글에서 언급했듯, MariaDB 설치 과정에서 자동으로 설치된 프로그램이다. 바탕화면의 다음의 아이콘이 Heidi SQL 프로그램이다.

사진 1-1
만약 해당 프로그램이 설치되지 않았다면 구글에 “Heidi sql”이라고 치고 나오는 “HeidiSQL” 공식 홈페이지에서 다운로드 받으면 된다.
HeidiSQL - MariaDB/MySQL, MSSQL, PostgreSQL, SQLite and Interbase/Firebird made easy
위 사이트에 접속한 후, 맨 위의 “”Downloads”를 눌러 다운로드 받고 설치하면 된다. 설치 과정도 매우 간단하기에 여기서는 그 과정을 생략하겠다.
해당 프로그램의 간단한 사용법은 다음의 사진들과 세부 설명들로 대체하겠다.
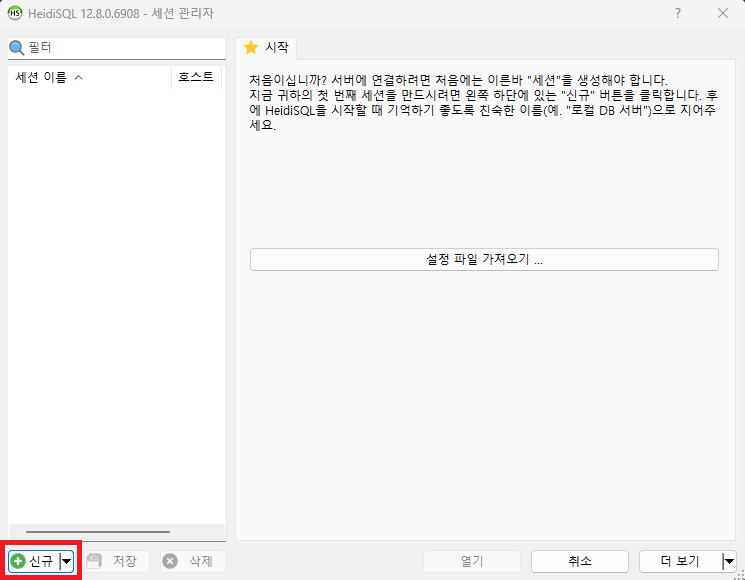
사진 1-2. HeidiSQL 실행 시 첫 화면. 새 세션 생성을 위해 “신규” 버튼을 누른다.
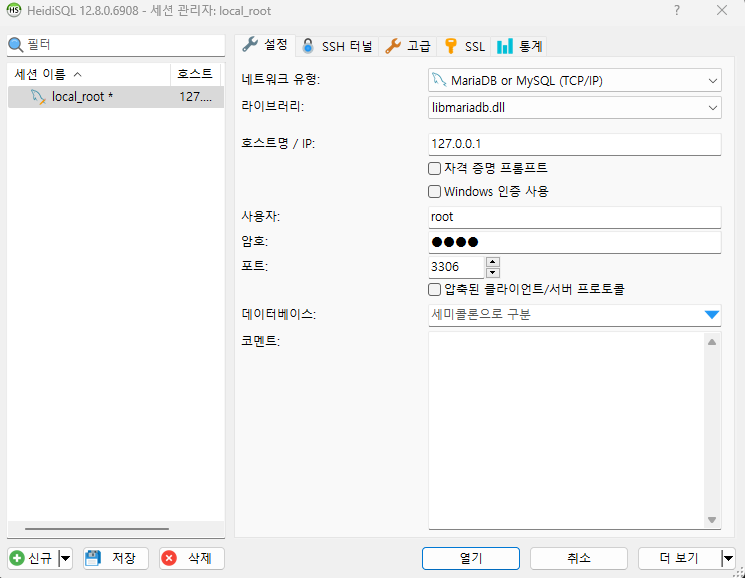
사진 1-3. 세션 이름을 정하고, 호스트명 및 사용자, 암호, 포트를 정한 후 “저장” 버튼을 눌러 저장한다. 하단의 “열기” 버튼을 누르면 해당 세션을 열어 db 서버에 접속할 수 있다. 원래는 “사용자” 명에 root가 아닌 다른 사용자를 생성하는 게 보안상 좋다. 여기선 실습용이므로 그냥 root라 하겠다.
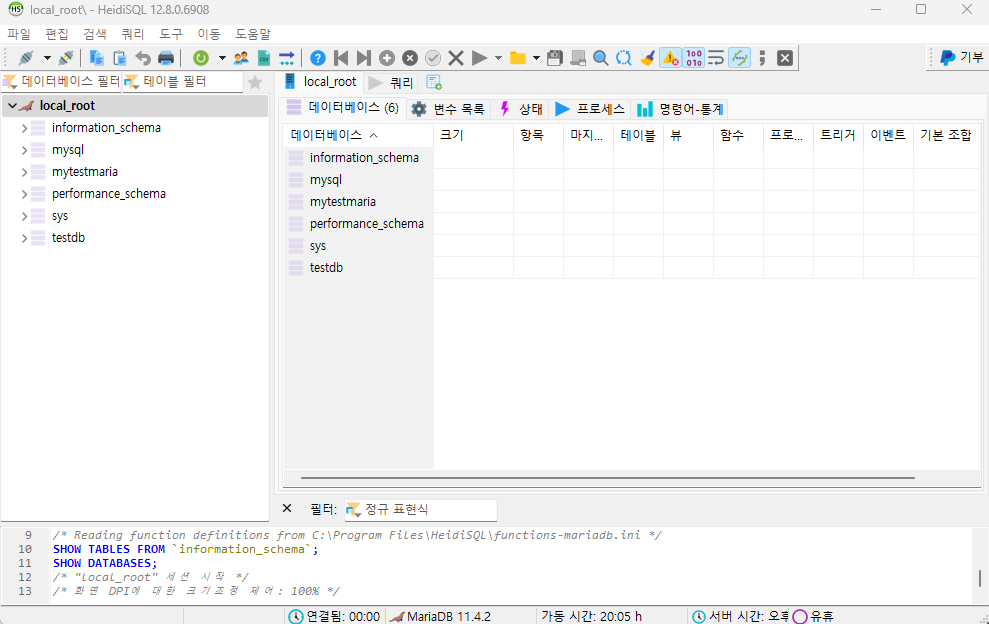
사진 1-4. 앞선 화면에서 “열기” 버튼을 누르면 위와 같은 화면이 뜬다.
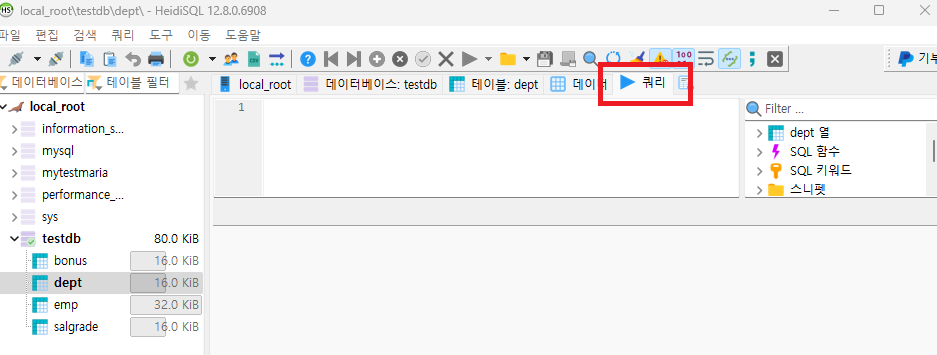
사진 1-5. sql 코드 작성 시 “쿼리” 탭을 눌러 그 안에 작성하면 된다. 코드 작성 후 실행하길 원하는 코드만 드래그한 후 우클릭 ⇒ “선택 실행”을 누르면 그 결과가 뜬다.
여기서는 위 프로그램 환경에서 SQL을 연습할 것이다.
해당 프로그램에서 이전에 추가한 테이블 내 데이터는 다음과 같이 생겼다.
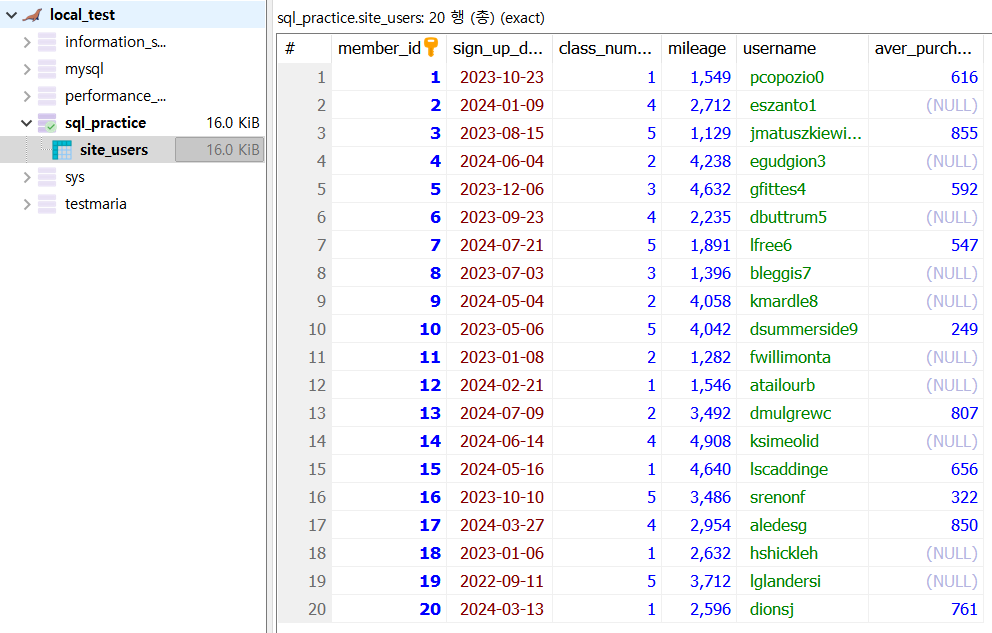
사진 1-6. site_users 테이블 내 데이터들
이제부터 본격적으로 SQL 문법에 대해 살펴보겠다.
SELECT문
SELECT문은 데이터를 조회, 검색을 하는 명령어이다.
기본 구조는 다음과 같다.
SELECT 필드명1, 필드명2, ... FROM 테이블명;
예제 1-1
위 쿼리문은 테이블로부터 특정 필드들에 속하는 데이터들을 선택하여 검색하겠다는 의미이다.
다음은 이를 활용한 예시 쿼리문과 그 결과이다.
SELECT sign_up_date, username, class_number FROM site_users;
예제 1-2
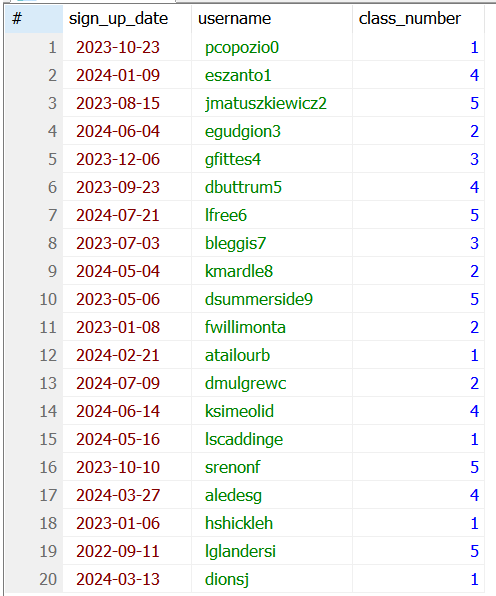
예제 1-2 실행결과
SELECT 키워드 바로 뒤에 지정한 필드명에 속하는 데이터들만 나온 것을 알 수 있다. 이렇게 SELECT 키워드 바로 뒤에 보고자 하는 필드명만 입력하여 한 레코드의 특정 필드에 속하는 데이터들만 볼 수 있다.
만약 모든 필드들을 보고 싶다면 대신 와일드 문자인 * 을 사용하면 된다. 다음은 그 예시이다.
SELECT * from site_users;
예제 1-3
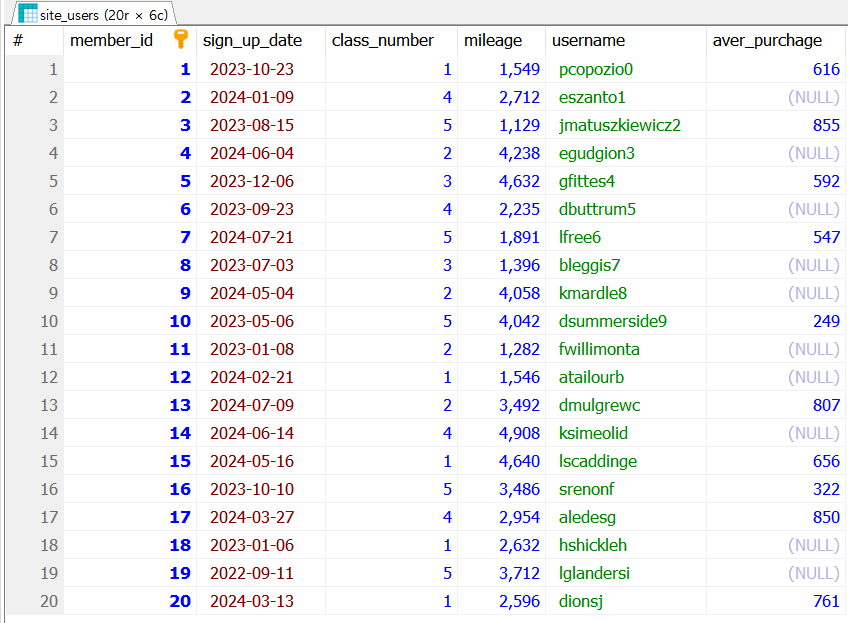
예제 1-3 실행결과
사실상 테이블의 모든 데이터를 가져오는 것과 동일하다.
필드 데이터 가공하여 보이기
특정 필드명에 연산식을 넣어 그 연산 결과를 검색 결과에 보이게 할 수 있다. 다음은 사이트에서 사람들에게 마일리지를 1000포인트나 뿌려주는 쿼리문이다.
SELECT username, mileage, mileage + 1000 FROM site_users;
예제 2-1
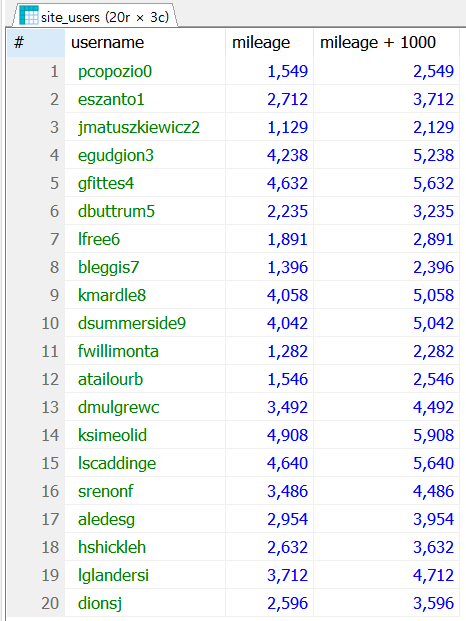
예제 2-1 실행결과
연산식을 추가한 필드명에는 그 연산식이 고스란히 보이는 것을 알 수 있다.
사실 필드명에 연산식을 가한다고 해서 실제로 데이터가 변경되는 것은 아니다.
필드 별칭(Alias)
SELECT문을 이용할 때 검색 결과로 보일 필드명을 다르게 바꿀 수 있다. 두 가지 방법이 있다. 하나는 AS 키워드를 사용하는 것이다. 이름을 바꾸고자 하는 필드명 뒤에 AS를 붙이고 그 뒤에 원하는 별칭을 지으면 된다.
SELECT 필드명1, 필드명2 AS 별칭1, ... FROM 테이블명;
예제 3-1
다음은 앞선 연산식의 필드명이 마음에 안들어 다르게 바꾼 예제이다.
SELECT username, mileage, mileage + 1000 AS bonus FROM site_users;
예제 3-2
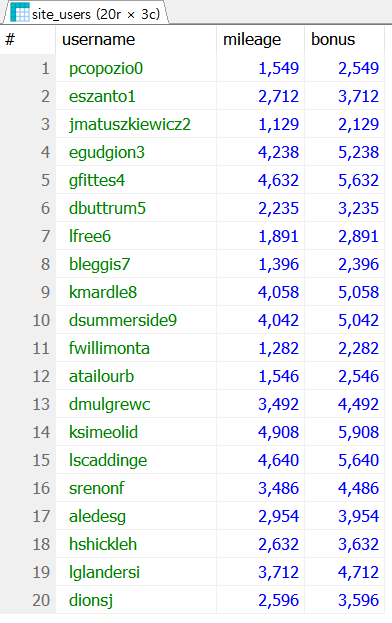
예제 3-2 실행결과
위 결과의 필드명을 보면 “bonus”로 바뀐 것을 볼 수 있다.
또 하나의 방법은 아예 AS 키워드를 생략하고 오로지 공백 한 칸으로 구분하는 것이다. 다음의 쿼리문도 위와 같은 결과를 도출한다.
SELECT username, mileage, mileage + 1000 bonus FROM site_users;
예제 3-3
DISTINCT : 중복 데이터 제거하고 보여주기
특정 필드명 앞에 DISTINCT 키워드를 붙이면 중복되는 데이터들은 제거하고 보여준다.
SELECT class_number FROM site_users;
SELECT DISTINCT class_number FROM site_users;
예제 4-1
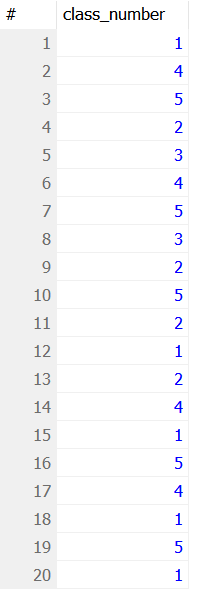
예제 4-1 실행결과1. DISTINCT를 적용하지 않은 경우
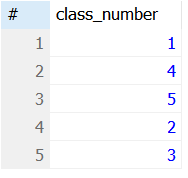
예제 4-1 실행결과2. DISTINCT를 적용한 경우.
그러나 DISTINCT 키워드를 사용할 때 주의할 점이 있다. 만약 다음과 같이
SELECT DISTINCT username, class_number FROM site_users;
예제 4-2
출력할 필드가 2개 이상일 경우, DISTINCT는 특정 필드에만 중복 데이터를 제거하는 것이 아닌, 열거된 모든 필드명들이 조합하는 레코드의 중복만 제거한다. 예를 들어,
| username | class_number |
|---|---|
| 김큐엘 | 1 |
| 자바스 | 1 |
| 김큐엘 | 1 |
| 나이썬 | 1 |
위와 같은 데이터가 있을 때 DISTINCT를 적용하면 모두 class_number가 1이란 이유로 데이터가 단 하나만 출력되지 않고, 총 3개로 줄어든다. 위 표에서 “김큐엘, 1”이란 레코드가 두 개가 중복되기에 해당 중복 데이터에만 DISTINCT가 적용되는 것이다.
SELECT문을 여러 키워드와 같이 사용하기
ORDER BY : 정렬하기
ORDER BY를 사용하면 데이터를 정렬시켜 볼 수 있다.
SELECT 필드명 FROM 테이블명 ORDER BY 필드명1, 필드명2, ... [DESC]
예제 5-1
ORDER BY 키워드 뒤에 정렬할 기준이 될 필드명을 적으면 된다. 필드를 여러 개 작성할 수도 있는데, 이 경우, 맨 왼쪽부터 1차 기준, 2차 기준 순으로 정렬되는 것이다.
ORDER BY 뒤에 적은 필드명 바로 뒤에 공백 한 칸 띄고 ASC 또는 DESC 키워드를 적용할 수 있다. ASC는 오름차순으로 정렬하겠단 뜻으로, 기본값이므로 보통 생략하여 사용한다. DESC는 내림차순으로 정렬하겠단 뜻이다. 이는 기본값이 아니므로 내림차순을 원하면 반드시 해당 키워드를 작성해야 한다.
다음은 클래스 숫자를 1차 기준으로 내림차순 정렬한 뒤, 중복되는 클래스 숫자를 가질 경우, 2차 기준으로 보유 마일리지를 기준으로 오름차순 정렬하는 쿼리문이다.
SELECT username, class_number, mileage FROM site_users
ORDER BY class_number DESC, mileage;
-- 참고로 위와 같이 줄이 길어지면 다음 줄에 이어 작성해도
-- 컴파일러는 이를 인식한다. 어차피 세미콜론이 문장의 끝을
-- 알려주는 기준이기 때문이다.
예제 5-2
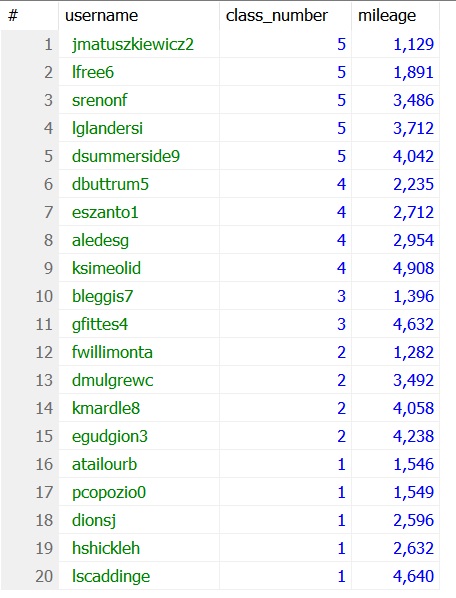
예제 5-2 실행결과
WHERE : 조건에 맞는 데이터만 추출하기
사실 SELECT * FROM table; 구조만 사용하면 지금은 레코드 개수가 20개 밖에 안되어 문제가 없겠지만, 데이터가 대규모일 경우 그 많은 데이터들이 출력될 것이다. 이럴려면 차라리 테이블 내부를 직접 보는 게 낫다. 그리고 실제로 사용할 때에도 모든 데이터를 다 뽑을 일은 거의 없을 것이다. 보통은 특정 조건의 데이터만 추출하기를 원할 것이다. 이를 수행시켜주는 것이 WHERE 조건문이다. 해당 키워드 뒤에 조건식을 작성하면 그 조건식에 부합하는 데이터들만 출력된다.
다음은 여러 조건식을 사용해본 쿼리문 예제이다.
-- #1
-- SQL에서 "같다"를 표현할 땐 그냥 '=' 기호 하나만 사용한다.
SELECT username, class_number FROM site_users
WHERE class_number = 1;
-- #2
SELECT username, class_number, mileage FROM site_users
WHERE mileage >= 3000;
예제 6-1
예제 6-1의 #1 쿼리문 실행결과
예제 6-1의 #2 쿼리문 실행결과
WHERE 조건문에는 다음의 키워드들을 사용할 수 있다.
- AND, OR : 두 조건식을 AND 또는 OR로 이어준다.
-- class_number가 3 이하이면서 mileage가 3000을 넘는 회원들에
-- 대해서만 정보 조회.
SELECT username, class_number, mileage FROM site_users
WHERE class_number <= 3 AND mileage >= 3000;
예제 6-2
-- class_number가 3 이하이고,
-- 마일리지가 3000 이상이거나 평균 구매액이 NULL이 아닌 회원 정보 조회.
SELECT *
FROM site_users
WHERE class_number <= 3
AND (mileage >= 3000 OR aver_purchase IS NOT NULL);
-- 위와 같이 조건식들 중 먼저 연산하고자 하는 조건식들을
-- 괄호로 묶으면 괄호로 묶인 연산식이 먼저 수행된다.
예제 6-3
- X BETWEEN A AND B : A와 B 사이의 값을 가지는지 확인하는 조건문. A와 B가 범위에 포함된다. A ≤ X ≤ B?
-- 보유 마일리지가 1000이상 3000포인트 이하인 회원들의 정보 조회.
SELECT *
FROM site_users
WHERE mileage >= 1000 AND mileage <= 3000;
-- BETWEEN을 사용하면 쿼리문이 조금 더 간단해진다.
SELECT *
FROM site_users
WHERE mileage BETWEEN 1000 AND 3000;
예제 6-4
- IN() : 괄호 안에 들어간 값들 중 하나라도 포함되어 있으면 검색 결과에 포함된다.
/*
username이 a 또는 f로 시작하는 회원들의 정보 조회.
LEFT(str, len) : str으로 전달된 문자열의 맨 왼쪽부터
len 숫자만큼의 부분 문자열을 추출.
*/
SELECT *
FROM site_users
WHERE LEFT(username, 1) = 'a' OR LEFT(username, 1) = 'f';
-- IN() 사용
SELECT *
FROM site_users
WHERE LEFT(username, 1) IN('a', 'f');
예제 6-5
- LIKE : 비슷한 데이터들을 검색한다. LIKE 우측에 올 문자열 내부에 다음의 문자들을 사용할 수 있다.
- %: 0개 이상의 문자를 대체할 때 사용. 해당 위치에 글자가 없어도 되고, 1개 이상 있어도 검색 범위에 포함된다. 정규 표현식의
*,{0,}과도 같다. 예) wo%w : wow, woww, woaw, wodfw, … - _ (언더바) : 1개의 문자를 대체. 예) wo_w : woow, wo1w, …
- %: 0개 이상의 문자를 대체할 때 사용. 해당 위치에 글자가 없어도 되고, 1개 이상 있어도 검색 범위에 포함된다. 정규 표현식의
-- username에 적어도 't'가 두 개 이상 들어가는 회원 정보 조회.
SELECT *
FROM site_users
WHERE username LIKE ('%t%t%');
예제 6-6

예제 6-6 실행결과
- NULL: 만약 필드값이 NULL이거나 또는 NULL아닌지를 확인하고자 한다면 각각
IS NULL과IS NOT NULL을 사용하면 된다. NULL은 그 어떤 계산이 되지 않는 값이므로=,!=등의 연산자는 적용되지 않는다.
-- 평균 구매액 데이터가 없는 사람들의 평균 마일리지
SELECT AVG(mileage) 'NULL 마일리지 평균'
FROM site_users
WHERE aver_purchase IS NULL;
-- 평균 구매액 데이터가 있는 사람들의 평균 마일리지
SELECT AVG(mileage) 'NOT NULL 마일리지 평균'
FROM site_users
WHERE aver_purchase IS NOT NULL;
예제 6-7
SELECT문과의 순서
SELECT문과 같이 쓸 수 있는 키워드들의 순서는 다음과 같다고 한다.
SELECT 열_이름
FROM 테이블명
WHERE 조건식
GROUP BY 열_이름
HAVING 조건식
ORDER BY 열_이름
LIMIT 숫자
예제 7-1
위 쿼리문 구조에서 GROUP BY 등의 처음 보는 키워드들은 나중에 다룰 것이다.
여기서 알아본 키워드는 SELECT, FROM, WHERE, ORDER BY가 될 것인데, WHERE는 FROM 뒤에 오며, ORDER BY는 WHERE 뒤에 오는 구조이다. 즉,
SELECT → FROM → WHERE → ORDER BY 순으로, 이 순서에 맞지 않게 작성하면 에러가 발생한다.
한 편, 컴파일 순서는 다음과 같다. 먼저 FROM 테이블 쿼리를 해석하여 일단 테이블 내 모든 데이터들을 가져온다. 그 다음 WHERE 절을 통해 데이터를 필터링하여 나온 데이터만을 가져온다. 그 후, SELECT 문을 통해 명시된 필드명에 해당하는 데이터들만 가져온다. 그 다음 ORDER BY 을 통해 지금까지 가져온 데이터들을 특정 기준에 따라 정렬하는 식이다. 즉, 컴파일 순서는 FROM → WHERE → SELECT → ORDER BY인 셈이다.
Sub Query
서브 쿼리는 하나의 쿼리문 안에 또 다른 쿼리문을 쓸 때 나오는 개념이다. 즉, 쿼리문도 중첩할 수 있다. 이 때 중첩된 쿼리문에서 바깥쪽에 위치한 쿼리문을 main query, 안쪽에 있는 쿼리를 sub query라고 한다. 이 때 sub query문은 괄호(())로 감싸야 한다.
특정 필드의 데이터를 정해진 값과 비교하는 것이 아닌, 특정 필드의 데이터 하나를 골라 다른 데이터와 비교해야할 때 sub query를 적용할 수 있다.
예를 들어, 1등급 회원들 중 최소 마일리지를 보유한 사람의 것보다 더 많은 마일리지를 보유한 2등급의 회원들이 있는지 조사하고자 한다. 일반적으로는 다음의 과정을 거쳤을 것이다.
-- 우선 1등급에 해당하는 사람들 중 최소 마일리지 보유자를 검색한다.
-- MIN(필드명) : 필드명에 해당하는 데이터들 중 최소값 반환.
SELECT MIN(mileage) FROM site_users
WHERE class_number = 1;
-- 위 쿼리문의 결과, 1546이란 결과값이 나왔다.
-- 위에서 얻은 최소 마일리지 값을
-- 2등급의 사람들과 비교
SELECT class_number, username, mileage
FROM site_users
WHERE class_number = 2
AND mileage > 1546;
예제 8-1
위 쿼리문의 문제점은 일단 최소 마일리지의 값을 찾아야 한다는 것이다. 그렇게 찾은 후에 그 값을 조건문에서 비교하여 원하는 결과값을 뽑아야 한다. 그러다보니 쿼리문이 두 개로 나뉘어졌다. 게다가 위 쿼리문의 맨 마지막에 적힌 1546은 한 눈에 보기에는 무슨 뜻인지 이해하기 어렵다. 또 하나의 문제점은, 데이터가 매번 바뀔 수도 있어 1차 쿼리문을 통해 일일이 비교를 위한 값을 찾아 이를 2차 쿼리문에 하드코딩하는 방법은 효율적이지 못하다.
위 문제들을 서브 쿼리를 이용하면 단번에 해결할 수 있다.
SELECT class_number, username, mileage
FROM site_users
WHERE class_number = 2
AND mileage > (SELECT MIN(mileage)
FROM site_users
WHERE class_number = 1);
예제 8-2
위와 같이 서브 쿼리를 이용하면 쿼리문을 두 개로 나눠 일일이 값을 확인하는 작업을 하지 않아도 되며, 비교 대상이 될 데이터가 매번 바뀌어도 개발자가 이를 일일이 확인하지 않아도 원래 목적을 그대로 유지하면서 자동으로 값을 비교할 수 있게 해준다.
SQL 관련 팁들
- SQL에서는 특별한 경우가 아니면 홑따옴표(’’)만 사용해야 한다.
- 데이터 자체를 제외하고는 영어 대소문자를 가리지 않는다. select든 SELECT든 상관없다. 데이터 자체는 프로그램에 따라 대소문자를 가릴 수도 있다고 하는데, MariaDB는 가리지 않는다고 한다.
- 날짜형 데이터는 연월일 구분 기호를 다양하게 사용할 수 있다.
2024-08-25,2024.08.26,2024/08/26모두 사용 가능하다.
References
[1] 에이콘아카데미(강남) 강의
[2] 우재남, “혼자 공부하는 SQL”, (한빛미디어, 2021)
[3] DISTINCT 주의사항
This content is licensed under
CC BY-NC 4.0
![]()
![]()
![]()

댓글남기기