[Spring Boot] 스케줄링과 Quartz
스프링부트로 제작한 웹 앱에서 특정 시간 간격마다 또는 지정된 시각마다 반복적인 작업을 자동으로 수행하는 “스케줄링(Scheduling)” 기능을 사용할 수 있는지 문득 궁금해졌다. 예전에 웹 앱을 만들었을 때 공개된 외부 API로부터 많은 데이터들을 수집하여 DB에 저장해야 하는 일이 있었는데, 그 때 당시에는 애초에 “스케줄링”이라는 개념조차 몰라서 어떻게 해야할지 몰라 임시로 관련된 REST API endpoint를 만든 다음, 이를 호출하여 데이터를 수집하는 방식을 취했었다. 이런 방법은 수동으로 직접 해야하는 것이라 하루의 특정 시각이 될 때마다 자동으로 데이터를 수집하는 자동화의 이점을 얻을 수 없다는 게 문제이다. 그래서 이에 대해 궁금히 여기다가 “스케줄링”에 대해 알게 되었고, 자바 및 스프링 진영에서는 어떻게 스케줄링 기능을 사용할 수 있는지 궁금해졌다.
자바 및 스프링 진영에서는 스케줄링 관련 라이브러리들이 여럿 있었다. 필자는 이에 대해 조사하다가 Quartz라는 라이브러리가 자주 언급되어서 이에 대해 알아보았다. 이 글에서는 자바 및 스프링 진영에서 스케줄링 기능을 이용하기 위한 라이브러리 중 하나인 Quartz에 대해 살펴보겠다.
Quartz 개요
Quartz는 Java 기반의 스케줄링을 위한 오픈 소스 라이브러리이다. 그래서 Spring Boot 뿐만 아니라 순수 자바 애플리케이션에서도 적용하여 사용할 수 있다.
사실 자바 진영에서 스케줄러를 사용하는 방법은 여러 개가 있다. Spring Boot 자체에서도 @Scheduled 어노테이션을 통해 지원하기도 하며, 자바 자체에서도 java.util.Timer, java.util.concurrent.ScheduledExecutorService 등을 이용하여 스케줄링을 구현할 수 있다고 한다. 그럼에도 필자가 조사해봤을 땐 Quartz에 대한 언급이 가장 많았다. 이러한 Quartz만의 특징, 장점 및 기능들은 다음과 같이 알려져 있다.
- 앞서 소개한 다른 스케줄링 라이브러리들은 보통 간단한 스케줄링 작업에 사용되는 반면, Quartz는 보다 복잡한 스케줄링 작업에도 사용될 수 있다.
- 스케줄링 작업들에 관한 정보들을 DB에도 저장하여 활용할 수 있다. 이는 Quartz 내에서 JDBC JobStore 형태로 사용할 수 있다.
- 뿐만 아니라 굳이 작업에 관한 정보들을 DB에 저장할 필요가 없다면 in-memory 방식으로 사용할 수도 있다(default).
- DB 사용 시 스케줄링 관련 정보들을 저장하기 위한 DB 스키마가 각 RDBMS마다 정해져 있다. 이에 대해선 다음의 소스 코드를 참고하면 되겠다. https://github.com/quartz-scheduler/quartz/tree/main/quartz/src/main/resources/org/quartz/impl/jdbcjobstore
- 스케줄링 작업에 관한 정보들을 DB에 저장할 수 있는 기능 제공 덕분에 다음의 기능들도 활용할 수 있다.
- DB 기반 클러스터링, fail-over, 그리고 random 방식의 로드 밸런싱(load balancing) 기능 제공.
- 스케줄링할 작업 단위를 Job 클래스로 구현하고, 이를 주어진 특정 시간에 실행시키도록 해주는 Trigger 클래스를 이용하여 Job을 실행시키는 구조이다. 즉, 작업을 정의하는 로직과 이를 트리거하는 로직이 분리되어 있는 구조이다. 이로 인해 동일한 Job을 대상으로 여러 Trigger들을 적용하여 각각 여러 조건의 시간대에 실행시키도록 할 수 있다. 단, Quartz에서는 하나의 Trigger 객체에는 하나의 Job만 등록 가능하기 때문에 반대로 여러 Job들을 동일한 조건의 시간대에 실행되도록 할 수는 없다고 한다. 어찌되었건 이러한 특징으로 인해 작업들을 유연하게 스케줄링할 수 있다.
- JobListener, TriggerListener의 존재 덕분에 Job이나 Trigger의 실행 전, 실행 후, 실행 실패 등 각각의 경우에 대한 처리를 할 수 있다.
Quartz를 구성하는 컴포넌트들에는 다음과 같이 존재한다.
| 이름 | 종류 | 설명 |
|---|---|---|
| Scheduler | interface | Job(정확히는 JobDetails)와 Trigger 객체들을 등록, 관리, 실행한다. |
| SchedulerFactory | interface | Scheduler의 인스턴스를 생성하기 위한 인터페이스. |
| StdSchedulerFactory | class | SchedulerFactory의 구현체 중 하나. quartz.properties 설정 파일로부터 설정값들을 가져와 설정된 Scheduler 인스턴스를 생성한다. |
| DirectSchedulerFactory | class | SchedulerFactory의 구현체 중 하나로 singleton이다. 간단하게 사용하고자 할 때 사용된다. |
| Job | interface | 스케줄러로 실행하고자 하는 작업을 나타내는 인터페이스. 실제로는 개발자가 이 인터페이스의 구현체를 정의하여 execute() 메서드 내에서 작업을 정의하면 된다. |
| JobDetail | interface | Job 인스턴스에 세부적인 설정들을 추가할 때 사용하는 인터페이스. 실제 JobDetail 인스턴스는 JobBuilder 클래스를 통해 생성하며, Scheduler 인스턴스에 등록하고 내부에서 관리하는 것은 Job 인스턴스가 아니라 JobDetail 인스턴스이다. |
| JobBuilder | class | JobDetail 인스턴스 생성에 사용되는 클래스. 여기에 개발자가 구현한 Job 클래스와 바인딩한다. |
| Trigger | interface | 특정 Job의 실행을 트리거할 때 사용될 인터페이스. |
| SimpleTrigger | class | 주어진 시간 간격 Job을 실행하거나 이를 얼마나 반복 실행할 것인지 설정할 수 있는 Trigger 구현체 중 하나. |
| CronTrigger | class | cron 표현식을 이용하여 Job을 트리거할 때 사용. Trigger 구현체 중 하나. |
| TriggerBuilder | class | 실제 Trigger 인스턴스를 생성할 때 사용되는 클래스. |
| JobListener | interface | Job의 생명 주기 동안 발생하는 이벤트를 처리할 때 사용. |
| TriggerListener | inferface | Trigger의 생명 주기 동안 발생하는 이벤트를 처리할 때 사용. |
| JobStore | interface | Job, Trigger 정보 저장 메커니즘을 제공하는 구현체를 제작하기 위한 인터페이스. |
| RAMJobStore | class | Job, Trigger 정보를 RAM에 저장하도록 하는 JobStore 구현체 중 하나. RAM에 저장하기에 데이터 접근은 빠르나 휘발성을 가지고 있어 프로그램 종료 시 스케줄링 관련 데이터들이 소멸된다. |
| JobStoreSupport | class | JDBC 기반으로 DB에 Job, Trigger 정보를 저장하는데에 도움을 주는 JobStore 구현체 중 하나. |
이제 코드를 통해서 Quartz를 사용하여 스케줄링 하는 방법에 대해 살펴보겠다. 이 글에서는 주로 in-memory 방식으로만 다룰 것이다. 만약 DB 기반 방식으로 스케줄링 기능을 구현할 일이 생긴다면 나중에 별도의 포스트로 다뤄보겠다.
자바에서 Quartz 사용해보기
자바에서 Quartz를 이용하여 간단한 스케줄링을 구성해보자. 여기서 소개할 코드의 전체 소스 코드는 여기를 참고.
먼저 build.gradle에 다음과 같이 Quartz 의존성을 명시한다.
dependencies {
// 생략...
implementation 'org.quartz-scheduler:quartz:2.5.0'
// 생략...
}
코드 1-1.
Quartz 버전은 Quartz Maven Repository를 참고하면 되겠다.
여기서는 간단하게 두 개의 Job들을 정의하고, 콘솔에 로그를 찍는 방식으로 하였다. 다음과 같이 두 개의 작업들을 정의하였다.
package jobs;
import lombok.extern.slf4j.Slf4j;
import org.quartz.Job;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
@Slf4j
public class FirstJob implements Job {
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
log.info("This is First Job");
}
}
코드 1-2. FirstJob.java
package jobs;
import lombok.extern.slf4j.Slf4j;
import org.quartz.Job;
import org.quartz.JobDataMap;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
import org.quartz.PersistJobDataAfterExecution;
@Slf4j
@PersistJobDataAfterExecution // JobData update 시 필수
public class SecondJob implements Job {
@Override
public void execute(JobExecutionContext context) throws JobExecutionException {
// JobDetail 객체의 usingJobData() 메서드에 입력한 데이터 맵을 가져온다.
JobDataMap dataMap = context.getJobDetail().getJobDataMap();
// JobDataMap에서 key가 "counter"인 값을 가져온다.
int counter = dataMap.getInt("counter");
log.info("{}번째 세컨 잡 실행", counter);
++counter;
// JobDataMap에 "counter"값을 갱신한다.
dataMap.put("counter", counter);
}
}
코드 1-3. SecondJob.java
위 코드들처럼 스케줄링할 작업을 정의하고자 한다면 Job 인터페이스의 execute() 메서드를 구현하면 된다. 첫 번째 클래스에서는 단순히 콘솔창에 특정 메시지를 출력하도록 작업을 정의하였다. 두 번째 클래스에서는 여기서 더 나아가 해당 작업이 스케줄링에 의해 현재 몇 번째까지 실행되었는지를 출력하도록 정의하였다. 이를 위한 counter 데이터는 JobDetail 인스턴스의 usingJobData(String dataKey, Integer value) 를 이용하여 해당 job에 추가해줄 수 있다. 이에 대한 코드는 바로 뒤에 소개할 Main.java 코드를 참고하면 되겠다. SecondJob 클래스 내부에서는 이렇게 외부에서 들어온 데이터를 가져와 이를 출력한 뒤, 다음을 위해서 값을 1 증가시키고 이를 기존 JobDataMap에 반영시키도록 하고 있다. 이렇게 JobData의 값을 업데이트하여 JobDetail에 영속화하고자 한다면 Job 구현체 클래스에 @PersistJobDataAfterExecution 어노테이션을 부여해야 한다. 그렇지 않으면 해당 데이터의 값이 갱신되지 않는다.
다음은 앞서 정의한 작업들을 스케줄러에 등록하여 스케줄링하는 코드이다.
/**
* <p>
* 순수 자바 애플리케이션에서 Quartz 라이브러리 사용 방법 살펴보기.
* </p>
*/
import jobs.FirstJob;
import jobs.SecondJob;
import lombok.extern.slf4j.Slf4j;
import org.quartz.JobBuilder;
import org.quartz.JobDetail;
import org.quartz.Scheduler;
import org.quartz.SchedulerException;
import org.quartz.SimpleScheduleBuilder;
import org.quartz.Trigger;
import org.quartz.TriggerBuilder;
import org.quartz.impl.StdSchedulerFactory;
@Slf4j
public class Main {
public static void main(String[] args) {
System.out.println("main 메서드 시작.");
JobDetail firstJob = JobBuilder.newJob(FirstJob.class)
.withIdentity("firstJob", "group1")
.build();
Trigger firstJobTrigger = TriggerBuilder.newTrigger()
.withIdentity("firstTrigger", "group1")
.startNow()
.withSchedule(
SimpleScheduleBuilder.simpleSchedule()
.withIntervalInSeconds(1)
.withRepeatCount(10)
)
.build();
JobDetail secondJob = JobBuilder.newJob(SecondJob.class)
.withIdentity("secondJob", "group2")
.usingJobData("counter", 1)
.build();
Trigger secondJobTrigger = TriggerBuilder.newTrigger()
.withIdentity("secondTrigger", "group2")
.startNow()
.withSchedule(
SimpleScheduleBuilder.simpleSchedule()
.withIntervalInSeconds(1)
.withRepeatCount(10)
)
.build();
try {
Scheduler scheduler = new StdSchedulerFactory().getScheduler();
scheduler.start();
scheduler.scheduleJob(firstJob, firstJobTrigger);
scheduler.scheduleJob(secondJob, secondJobTrigger);
//scheduler.shutdown(true);
} catch (SchedulerException e) {
log.info("====== 스케줄링 작업 중 예외가 발생했습니다. =====");
e.printStackTrace();
}
}
}
코드 1-4. Main.java
먼저 JobBuilder를 이용하여 JobDetail 인스턴스들을 생성해주고 있다. 여기서 앞서 정의한 Job 구현체들은 newJob(FirstJob.class) 와 같이 Class 타입으로 JobBuilder에 대입하여 바인딩한다. 그 후
.withIdentity("firstJob", "group1") 메서드를 통해 해당 Job의 이름 및 그룹명을 설정해준다. 실제에서는 수많은 Job들이 스케줄링 될 수도 있는데, 이 Job들을 고유하게 구별해주는 용도이다.
SecondJob에 대해서는 해당 작업이 스케줄링에 의해 현재 몇 번째로 호출되었는지 출력, 저장하기 위해 .usingJobData("counter", 1) 와 같이 카운터 데이터를 추가해주었다.
두 개의 Job에 대해 각각의 Trigger 객체들을 위와 같이 생성하였다. .withSchedule() 내부에서는 크게 SimpleScheduleBuilder 와 CronScheduleBuilder 중 하나를 이용하여 스케줄링을 위한 시간 간격 및 반복 횟수, 또는 특정 시각을 지정해줄 수 있다. SimpleScheduleBuilder 는 시간 간격 및 반복 횟수로 지정할 때 사용되며, CronScheduleBuidler 는 시, 분, 한 달 중 특정 날짜, 특정 달, 특정 요일들을 기준으로 주기적으로 실행시키고자 할 때 사용된다.
참고) cron 표현식을 적용한 Trigger 인스턴스 생성하기 link
참고로 cron은 Unix 계열 운영체제에서의 시간 기반 잡 스케줄러 프로그램으로, 주로 여기서 사용되는 시간 표현식을 언급하는 의미로 쓰인다. Github Docs에 따르면 cron 표현식은 다음과 같이 구성되어 있다.
┌───────────── minute (0 - 59)
│ ┌───────────── hour (0 - 23)
│ │ ┌───────────── day of the month (1 - 31)
│ │ │ ┌───────────── month (1 - 12 or JAN-DEC)
│ │ │ │ ┌───────────── day of the week (0 - 6 or SUN-SAT)
│ │ │ │ │
│ │ │ │ │
│ │ │ │ │
* * * * *
코드 1-5. Unix 기반 cron 표현식
| 연산자 | 뜻 | 예시 |
|---|---|---|
* |
아무 값 | 30 * * * * 는 매일 매시각의 30분일 때마다 실행. 1시 30분, 2시 30분, 3시 30분, … 등에 워크플로우를 실행 |
, |
값 열거를 위한 구분자 | 30 5,17 * * * 은 매일 오전 5시 30분 및 오후 5시 30분에 워크플로우를 실행 |
- |
값 범위 지정 | 30 5-17 * * * 은 매일 오전 5시 30분부터 1시간 간격으로 오후 5시 30분까지 워크플로우를 실행. 오전 5시 30분, 6시 30분, 7시 30분, … , 오후 4시 30분, 오후 5시 30분에 각각 실행됨. |
/ |
step 값 | 20/15 * * * * 은 20분부터 59분까지 15분 간격으로 워크플로우를 실행. 매 시간의 20분, 35분, 50분에 실행. |
표 1-1. cron 표현식에 사용되는 연산자들
Quartz에서는 다음과 같이 활용 가능하다.
// 매주 월요일 오전 10시마다 실행
CronTrigger cronTrigger = TriggerBuilder.newTrigger()
.withIdentity("myTrigger", "group1")
.withSchedule(CronScheduleBuilder.cronSchedule("0 0 10 ? * MON"))
.build();
코드 1-6. cron 방식. 출처: https://adjh54.tistory.com/170
그런데 위 코드를 자세히 보면 앞서 소개한 unix 기반 cron 표현식에서는 총 5자리만 사용하는 것에 비해 위 코드에서는 6자리를 사용하는 것을 볼 수 있다. 이는 사실 Quartz에서는 Quartz cron이라는 것을 별도로 사용하기 때문이다. 따라서 사실 Unix 기반 cron이 아닌 Quartz cron 표현식을 따라야 한다.
* * * * * * [*]
초, 분, 시, 일[1-31], 월[1-12], 요일[0-6], [연도](생략가능)
// 요일) 0 - 일요일, ... 6 - 토요일
코드 1-7. Quartz cron 표현식 구조
연도의 경우 생략 가능하며, 생략 시 매년마다 실행되고, 생략하지 않고 특정 연도를 기입하면 해당 연도일 때에만 실행된다.
한 편 Quartz cron에는 기존의 Unix 기반 cron에는 보이지 않던 몇 가지 옵션들이 있다. 그 중 하나로 ? 가 있는데, 이는 “설정값 없음”을 뜻한다. 일(day of month)과 요일(day of week)에서만 사용 가능하며, 이 두 필드는 동시에 특정 값으로 지정할 수 없다. 따라서 둘 중 하나는 반드시 ? 를 사용해야하는 셈이다. 이렇게 하지 않으면 에러가 발생할 수 있다고 한다.
앞서 정의한 job을 스케줄링 하기 위해 try 문 안에 Scheduler 인스턴스를 생성하였다. start() 메서드를 호출하면 Scheduler에 등록된 Trigger를 실행(fire)할 SchedulerThread를 동작시켜 결과적으로 스케줄링을 시작하게 한다. 그리고 scheduler.scheduleJob(jobDetail, trigger) 메서드에 각각 스케줄링할 작업(JobDetail)과 이를 실행시킬 Trigger 객체를 등록하면 스케줄링이 시작된다.
위 코드를 실행시키면 콘솔창에 다음과 같이 출력된다.
[DefaultQuartzScheduler_Worker-1] INFO jobs.FirstJob - This is First Job
[DefaultQuartzScheduler_Worker-2] INFO jobs.SecondJob - 1번째 세컨 잡 실행
[DefaultQuartzScheduler_Worker-3] INFO jobs.FirstJob - This is First Job
[DefaultQuartzScheduler_Worker-4] INFO jobs.SecondJob - 2번째 세컨 잡 실행
[DefaultQuartzScheduler_Worker-5] INFO jobs.FirstJob - This is First Job
[DefaultQuartzScheduler_Worker-6] INFO jobs.SecondJob - 3번째 세컨 잡 실행
[DefaultQuartzScheduler_Worker-7] INFO jobs.FirstJob - This is First Job
[DefaultQuartzScheduler_Worker-8] INFO jobs.SecondJob - 4번째 세컨 잡 실행
// 생략...
코드 1-8. 콘솔창 출력 결과
이와 같이 2개의 작업이 설정된 시간 간격과 반복 횟수에 따라 동시에 실행되어 스케줄링되는 것을 확인할 수 있다.
Quartz 설정 파일
Quartz에서는 quartz.properties 파일을 통해 Quartz 관련 설정을 할 수 있다. 생략해도 상관없으며, 해당 파일에는 org.quartz. 로 시작하는 여러 설정값들을 설정할 수 있다. 여기에는 JobStore 방식, thread pool size 등을 설정할 수 있다. 설정값들 및 설정에 관한 자세한 사항은 Quartz docs 참고.
스프링부트에서 Quartz 사용하기
이 챕터에서 보일 스프링부트 기반 코드들의 전체 소스 코드는 다음을 참고.
spring-boot-study-with-intellij/QuartzStudy at master · JeroCaller/spring-boot-study-with-intellij
스프링부트에서는 Quartz 사용 편의성을 제공해주는 'org.springframework.boot:spring-boot-starter-quartz' 의존성을 제공한다. 스프링부트에서는 기존 자바에서의 Quartz에는 없는 SchedulerFactoryBean이라는 클래스를 제공한다. 이 클래스는 Quartz의 스케줄링 기능 사용을 위해 필요한 Scheduler 객체를 자동 구성해주고 이 객체를 Spring context에서 관리하는 역할을 담당한다. 따라서 앞서 살펴본 자바에서의 Quartz와 달리 스프링 부트에서는 개발자가 직접 Scheduler 인스턴스를 생성하거나 Job, Trigger 할당, start() 메서드 호출을 하지 않아도 된다. 물론 필요하다면 Scheduler를 DI(Dependency Injection)를 통해 가져와 사용할 수도 있다.
스프링부트에서 제공하는 Quartz를 사용하기 위해 build.gradle의 dependency에 다음의 의존성을 명시하면 된다.
implementation 'org.springframework.boot:spring-boot-starter-quartz'
코드 2-1. 스프링 부트 Quartz 의존성
Job 인터페이스를 구현하여 스케줄링할 작업을 정의하는 것은 아까와 동일하다. 다만 해당 구현체는 @Component 등을 이용하여 스프링 빈에 등록하는 과정이 필요하다. 다음은 그 예시이다.
package com.jerocaller.QuartzStudy.schedule.job;
import com.jerocaller.QuartzStudy.service.GoogleTrendService;
import lombok.RequiredArgsConstructor;
import org.quartz.Job;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
import org.quartz.PersistJobDataAfterExecution;
import org.springframework.stereotype.Component;
@Component // Job 구현체를 Spring Bean으로 등록해야 함.
@RequiredArgsConstructor
@PersistJobDataAfterExecution
public class GoogleTrendKeywordJob implements Job {
private final GoogleTrendService googleTrendService;
@Override
public void execute(JobExecutionContext context) throws JobExecutionException {
googleTrendService.saveData();
}
}
코드 2-2.
이미 어떠한 비즈니스 로직을 수행할 서비스 bean을 만들어놓은 상황이고, 이를 스케줄링할 것이라면 위 코드처럼 Job 구현체 클래스에 의존성 주입하여 execute() 메서드 내부에 호출 코드를 작성하도록 구성할 수 있다.
스프링부트를 이용하여 웹 앱을 만드는 경우 정의한 대로 스케줄링 되는지 확인하기 위해 로그를 콘솔창에 출력하도록 할 필요가 있을 것이다. 이를 위해 특정 Job이 실행되기 전과 실행 후 각각 실행 시작 및 실행 완료를 로그로 출력하기 위해 다음과 같이 JobListener의 구현체를 정의하였다.
package com.jerocaller.QuartzStudy.schedule.listener;
import com.jerocaller.QuartzStudy.mapper.DateMapper;
import com.jerocaller.QuartzStudy.schedule.ProcessedJobData;
import lombok.extern.slf4j.Slf4j;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
import org.quartz.JobListener;
import org.springframework.stereotype.Component;
import java.time.LocalDateTime;
@Slf4j
@Component
public class GlobalJobListener implements JobListener {
@Override
public String getName() {
return "GlobalJobListener";
}
/**
* Job 실행 전 수행
*
* @param context
*/
@Override
public void jobToBeExecuted(JobExecutionContext context) {
ProcessedJobData processedJobData = new ProcessedJobData(context);
log.info("{}: {}번째 {} job 실행 개시",
processedJobData.getFireDateTimeToString(),
processedJobData.getCounter(),
processedJobData.getJobName()
);
}
/**
* Job 실행 실패 또는 중단 시 수행
*
* @param context
*/
@Override
public void jobExecutionVetoed(JobExecutionContext context) {
ProcessedJobData processedJobData = new ProcessedJobData(context);
log.error("{} job 실행 실패.", processedJobData.getJobName());
processedJobData.persistNextCounter();
}
/**
* Job 실행 이후 수행
*
* @param context
* @param jobException
*/
@Override
public void jobWasExecuted(JobExecutionContext context, JobExecutionException jobException) {
ProcessedJobData processedJobData = new ProcessedJobData(context);
String currentDateTimeString = DateMapper.toDateTimeFormatString(LocalDateTime.now());
log.info("{}: {}번째 {} job 실행 완료.",
currentDateTimeString,
processedJobData.getCounter(),
processedJobData.getJobName()
);
processedJobData.persistNextCounter();
}
}
코드 2-3.
package com.jerocaller.QuartzStudy.schedule;
import com.jerocaller.QuartzStudy.mapper.DateMapper;
import lombok.Getter;
import org.quartz.JobDetail;
import org.quartz.JobExecutionContext;
import java.time.LocalDateTime;
@Getter
public class ProcessedJobData {
private JobExecutionContext context;
private String jobName;
private Integer counter;
private LocalDateTime fireDateTime;
private String fireDateTimeToString;
public ProcessedJobData(JobExecutionContext context) {
this.context = context;
process();
}
private void process() {
JobDetail jobDetail = context.getJobDetail();
jobName = jobDetail.getKey().getName();
counter = jobDetail.getJobDataMap().getInt(ScheduleNames.COUNTER);
fireDateTime = DateMapper.toLocalDateTime(context.getFireTime());
fireDateTimeToString = DateMapper.toDateTimeFormatString(fireDateTime);
}
public void persistNextCounter() {
context.getJobDetail().getJobDataMap()
.put(ScheduleNames.COUNTER, counter + 1);
}
}
코드 2-4. 코드 2-3에서 Job 관련 데이터들을 편리하게 추출하기 위해 정의한 클래스. 작업 호출 횟수를 출력하기 위해 이 횟수를 업데이트하는 persistNextCounter() 메서드도 정의하였다.
위 코드 2-3에서는 Job이 Scheduler에 의해 실행될 때 해당 Job이 몇 번째로 실행되는지, 그리고 실행 완료되었는지 여부를 로그로 출력하도록 하였다. JobListener에서는 다음과 같은 추상 메서드들을 제공한다.
getName()- JobListener를 고유하게 식별하기 위한 이름을 반환. 구현 시 이름을 지어 이를 반환하도록 한다.jobToBeExecuted()- Job이 실행되기 직전에 수행되는 메서드.jobExecutionVetoed()- Job 실행이 실패 또는 중단되었을 때 실행되는 메서드.jobWasExecuted()- Job 실행 이후 실행되는 메서드.
따라서 Job이 정상적으로 실행되는 경우 JobListener에서는 jobToBeExecuted() → Job.execute() (작업 실행) → jobWasExecuted() 순으로 실행된다. 이러한 JobListener에서는 스케줄링되는 job의 실행 이전, 이후, 중단 등의 이벤트를 계속 listening하여 해당 이벤트가 발생할 경우 해당되는 메서드가 실행되는 방식인 것이다.
TriggerListener도 이와 마찬가지로 특정 Trigger의 실행에 따라 발생하는 이벤트에 대한 처리를 할 수 있다. 다음은 어떤 Trigger가 어떤 Job을 실행시키는지 확인하기 위해 TriggerListener 구현체를 정의한 코드이다.
package com.jerocaller.QuartzStudy.schedule.listener;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.quartz.JobExecutionContext;
import org.quartz.Trigger;
import org.quartz.TriggerListener;
import org.springframework.stereotype.Component;
@Slf4j
@Component
public class GlobalTriggerListener implements TriggerListener {
@Override
public String getName() {
return "GlobalTriggerListener";
}
@Override
public void triggerFired(Trigger trigger, JobExecutionContext context) {
ProcessedTriggerData processedTriggerData = getProcessedTriggerData(trigger, context);
log.info("{} Trigger가 {} Job을 트리거하였습니다.",
processedTriggerData.getTriggerName(),
processedTriggerData.getJobName()
);
}
@Override
public boolean vetoJobExecution(Trigger trigger, JobExecutionContext context) {
return false;
}
@Override
public void triggerMisfired(Trigger trigger) {}
@Override
public void triggerComplete(
Trigger trigger,
JobExecutionContext context,
Trigger.CompletedExecutionInstruction triggerInstructionCode
) {
ProcessedTriggerData processedTriggerData = getProcessedTriggerData(trigger, context);
log.info("==== {} 트리거 실행 완료 ====", processedTriggerData.getTriggerName());
if (!trigger.mayFireAgain()) {
log.info("{} Trigger는 더 이상 {} job을 트리거하지 않습니다.",
processedTriggerData.getTriggerName(),
processedTriggerData.getJobName()
);
}
}
private ProcessedTriggerData getProcessedTriggerData(
Trigger trigger,
JobExecutionContext context
) {
String jobName = context.getJobDetail()
.getKey()
.getName();
String triggerName = trigger.getKey()
.getName();
return ProcessedTriggerData.builder()
.jobName(jobName)
.triggerName(triggerName)
.build();
}
@Getter
@NoArgsConstructor
@AllArgsConstructor
@Builder
static class ProcessedTriggerData {
private String jobName;
private String triggerName;
}
}
코드 2-5.
TriggerListener에는 다음의 추상 메서드들이 있다.
getName()- TriggerListener 구현체를 고유하게 식별하는 이름을 반환. 개발자는 이름을 정해 이를 return하도록 해야 한다.triggerFired()- Trigger가 실행되고 이 Trigger와 연결된 JobDetail이 실행되기 직전 호출할 메서드.vetoJobExecution()- Trigger가 실행되고 이 Trigger와 연결된 JobDetail이 실행되기 직전 호출하는 메서드로, 특정 조건에 따라 이 job을 실행시킬 것인지 여부를 결정할 수 있다. true 반환 시 job은 실행되지 않고, false 반환 시 job이 그대로 실행된다.triggerFired()호출 이후에 실행되는 메서드. 이 메서드에서 true 반환으로 인해 해당 Job이 실행 중단되었을 때, Scheduler에 등록된JobListener.jobExecutionVetoed()가 실행된다.triggerMisfired()- Trigger가 중단되었을 때(제대로 실행되지 않았을 때) 호출되는 메서드.triggerComplete()- Trigger가 실행되고 이 Trigger와 연결된 JobDetail의 실행이 완료될 때 호출되는 메서드.
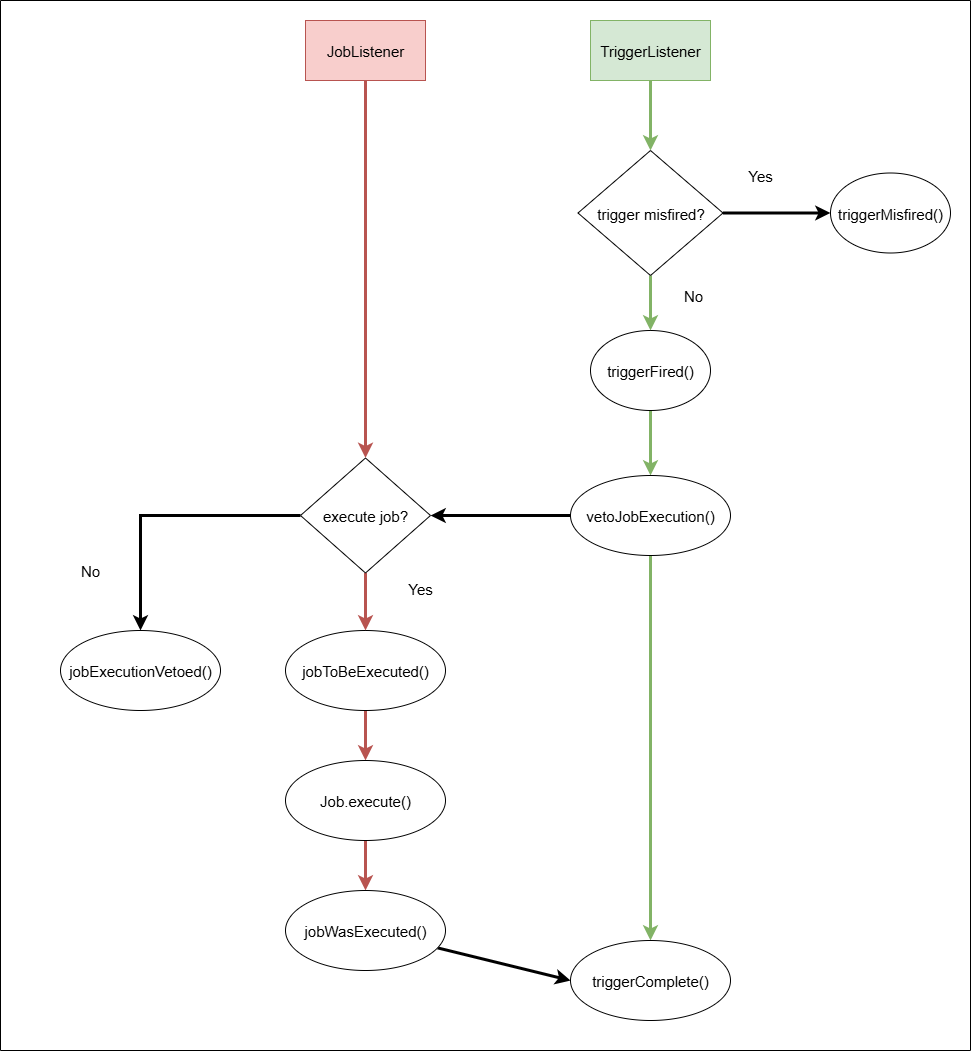
그림 1-1. JobListener와 TriggerListener 모두 스케줄러에 등록되었을 때 각 메서드들의 호출 순서도.
이제 앞서 만든 JobListener, TriggerListener, Job들을 Spring Bean으로 등록하여 스케줄링을 실행해보자. 이를 위해 다음과 같은 설정 클래스를 정의하였다.
package com.jerocaller.QuartzStudy.config;
import com.jerocaller.QuartzStudy.schedule.ScheduleNames;
import com.jerocaller.QuartzStudy.schedule.job.GoogleTrendKeywordJob;
import com.jerocaller.QuartzStudy.schedule.job.SimilarityJob;
import com.jerocaller.QuartzStudy.schedule.job.WordAnalysisJob;
import com.jerocaller.QuartzStudy.schedule.listener.GlobalJobListener;
import com.jerocaller.QuartzStudy.schedule.listener.GlobalTriggerListener;
import lombok.RequiredArgsConstructor;
import org.quartz.JobBuilder;
import org.quartz.JobDetail;
import org.quartz.SimpleScheduleBuilder;
import org.quartz.Trigger;
import org.quartz.TriggerBuilder;
import org.springframework.boot.autoconfigure.quartz.SchedulerFactoryBeanCustomizer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.quartz.SchedulerFactoryBean;
/**
* <h3>Note</h3>
* <p>
* 스프링부트에서는 Quartz의 Scheduler 객체가 auto-configure되며,
* JobDetail, Trigger, Calendar 타입의 Bean들을 자동으로 찾아 Scheduler 객체에
* 등록한다고 한다. 따라서 JobDetail과 Trigger는 각자 별도로 Bean으로 등록해야
* 에러 없이 작동 가능하다. 만약 하나의 메서드에 JobDetail, Trigger 객체를 모두 생성하고
* Trigger 객체만 반환하는 방식을 취한다면 JobDetail 객체는 Spring Bean에 등록되지 않으므로
* 에러가 발생한다.
* </p>
*/
@Configuration
@RequiredArgsConstructor
public class SchedulingConfig implements SchedulerFactoryBeanCustomizer {
private final GlobalJobListener globalJobListener;
private final GlobalTriggerListener globalTriggerListener;
private final int JOB_REPEAT = 3;
/**
* 자동 구성될 스케줄러 빈을 초기화하기전 커스텀하기.
* 여기서는 jobListener 및 triggerListener를 등록한다.
* 이 메서드에서 커스텀 설정이 적용된 후, 해당 스케줄러 빈이 초기화된다.
*
* @param schedulerFactoryBean
*/
@Override
public void customize(SchedulerFactoryBean schedulerFactoryBean) {
schedulerFactoryBean.setGlobalJobListeners(globalJobListener);
schedulerFactoryBean.setGlobalTriggerListeners(globalTriggerListener);
}
/**
* org.quartz.SchedulerException: Jobs added with no trigger must be durable.
* 위 에러 방지를 위해 `.storeDurably(true)`를 추가해야 한다.
*
* @return
*/
@Bean
public JobDetail googleTrendJobDetail() {
return JobBuilder.newJob(GoogleTrendKeywordJob.class)
.withIdentity("googleTrendKeywordJob")
.usingJobData(ScheduleNames.COUNTER, 1)
.storeDurably(true) // job이 trigger와 분리되어도 저장되도록 함.
.build();
}
@Bean
public Trigger googleTrendJobTrigger() {
return TriggerBuilder.newTrigger()
.withIdentity("googleTrendKeywordJobTrigger")
.forJob(googleTrendJobDetail()) // 트리거 할 jobDetail 등록
.startNow()
.withSchedule(
SimpleScheduleBuilder.simpleSchedule()
.withIntervalInMinutes(1)
.withRepeatCount(JOB_REPEAT)
)
.build();
}
@Bean
public JobDetail wordAnalysisJobDetail() {
return JobBuilder.newJob(WordAnalysisJob.class)
.withIdentity("wordAnalysisJob")
.usingJobData(ScheduleNames.COUNTER, 1)
.storeDurably(true)
.build();
}
@Bean
public Trigger wordAnalysisJobTrigger() {
return TriggerBuilder.newTrigger()
.withIdentity("wordAnalysisJobTrigger")
.forJob(wordAnalysisJobDetail())
.startNow()
.withSchedule(
SimpleScheduleBuilder.simpleSchedule()
.withIntervalInSeconds(30)
.withRepeatCount(JOB_REPEAT)
)
.build();
}
@Bean
public JobDetail similarityJobDetail() {
return JobBuilder.newJob(SimilarityJob.class)
.withIdentity("similarityJob")
.usingJobData(ScheduleNames.COUNTER, 1)
.storeDurably(true)
.build();
}
@Bean
public Trigger similarityJobTrigger() {
return TriggerBuilder.newTrigger()
.withIdentity("similarityJobTrigger")
.forJob(similarityJobDetail())
.startNow()
.withSchedule(
SimpleScheduleBuilder.simpleSchedule()
.withIntervalInSeconds(45)
.withRepeatCount(JOB_REPEAT)
)
.build();
}
}
코드 2-6.
앞서 정의한 Listener들을 Scheduler에 등록하기 위해선 SchedulerFactoryBeanCustomizer.customize() 메서드를 구현해야 한다. 이 메서드의 매개변수인 SchedulerFactoryBean 객체에 앞선 두 Listener 객체들을 등록하면 된다. 그러면 Listener들이 등록된 Scheduler 객체를 자동 구성할 수 있게 된다. 한 편, 각각의 Listener들을 순수 자바에서 Scheduler에 등록하려면 다음의 코드들을 사용하면 된다.
scheduler.getListenerManager().addJobListener(new MyJobListener());
scheduler.getListenerManager().addTriggerListener(new MyTriggerListener());
코드 2-7. 순수 자바 코드에서 각각의 Listener 객체 등록하는 코드 예시.
한 편, 위 코드에서는 총 3개의 작업들을 스케줄러에 등록하려고 하고 있다. 그리고 한 작업 당 하나의 트리거씩 배정하였다. JobDetail과 Trigger 객체 모두 Spring bean에 등록을 해야 Spring container에서 이들을 Scheduler에 자동으로 연관시켜 스케줄링할 수 있다.
앱을 실행해보면 콘솔창에서는 다음의 결과를 얻는다.
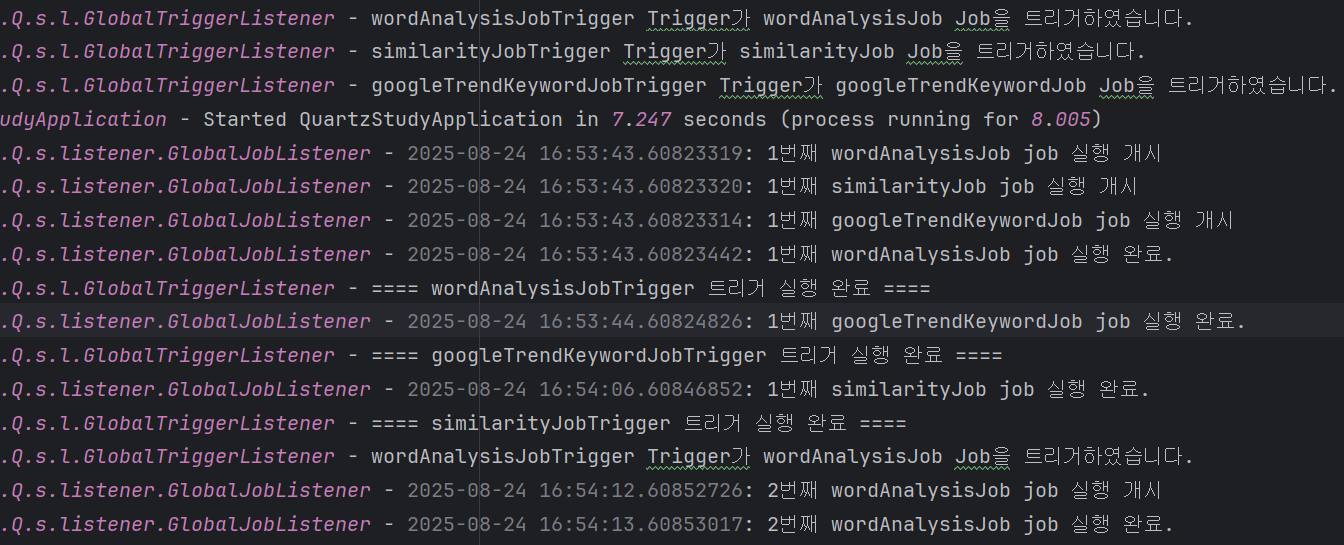
사진 1-1.
wordAnalysis 를 보면 맨 처음에 wordAnalysisJobTrigger 가 해당 job을 트리거했다는 메시지가 출력되고, 그 후 해당 job 실행 개시 → job 실행 완료 → wordAnalysisJobTrigger 트리거 실행 완료 순으로 출력되는 것을 볼 수 있다. 이는 앞서 보인 JobListener 및 TriggerListener의 각 메서드들의 호출 순서에 맞게 호출된다는 것을 보여준다.
Spring Boot에서의 Quartz 설정
순수 자바에서 Quartz 관련 설정을 위해 quartz.properties 파일을 생성, 작성하고, 각 설정 속성들은 org.quartz 로 시작하는 반면, Spring Boot에서 Quartz 관련 설정 시 application.yml 파일에서 한꺼번에 설정할 수 있다. Spring Boot에서의 Quartz 설정 속성들은 모두 spring.quartz 또는 spring.quartz.properties 로 시작한다. 그리고 대부분 기존의 Quartz에서 제공하는 속성들을 그대로 사용할 수 있다.
spring:
quartz:
# 앱 실행 시 스케줄링 자동 시작 여부 설정.
# 기본값은 true로, 앱 샐행과 동시에 자동으로 스케줄링이 되길 원한다면
# 굳이 설정값을 작성하지 않아도 됨.
auto-startup: false
코드 3-1. application.yml 설정 예시
위 코드 3-1에서는 Spring Boot 내에서 작성한 Quartz 스케줄러가 앱 실행 시 자동으로 시작되지 않도록 하고자 할 때 사용되는 속성값이다. 이를 이용하면 설정 파일만으로도 개발 환경에서는 Quartz 스케줄러가 작동되지 않도록 하고 프로덕션 환경에서는 작동되도록 유연하게 설정할 수 있다.
Spring Boot에서의 Quartz의 job store 설정에 관해서는 Spring docs 참고.
Quartz 내부 아키텍처 정리
](/images/2025-08-24/spring-boot-scheduling-and-quartz/3.png)
참고 사진 1-1. Quartz architecture. 출처: https://advenoh.tistory.com/51
](https://examples.javacodegeeks.com/wp-content/uploads/2019/05/quartz-architecture.jpg.webp)
참고 사진 1-2. Quartz architecture. 출처: https://examples.javacodegeeks.com/java-development/enterprise-java/quartz/java-quartz-architecture-example/
앞서 살펴본 Quartz 사용 방법 및 흐름과 위 참고 사진들을 토대로 Quartz 내부 아키텍처를 정리하면 다음과 같다.
- 하나의 JVM에서는 여러 개의 Scheduler 객체들을 메모리 상에서 등록, 조회, 관리할 수 있다고 한다. 이러한 Scheduler 객체들을 저장, 관리하는 SchedulerRepository란 컴포넌트가 있다. SchedulerFactory 컴포넌트가 여기서 Scheduler 객체를 검색하여 가져오거나 새로 생성한다.
- 필요하다면 Scheduler 객체에 JobListener, TriggerListener 객체들을 등록할 수 있다.
- 이 Scheduler 객체는 SchedulerThread라는 단일 메인 스레드가 관리한다.
- Scheduler 객체는 JobStore(RAM이든 DB든)에 저장되어 있는 Trigger들 중 바로 다음에 실행될 예정인 Trigger를 감시(polling)한다.
- Trigger의 실행 시간이 되었음을 발견하면 SchedulerThread는 해당 Trigger와 여기에 미리 연결되어 있던 JobDetail 객체를 JobStore로부터 가져와 이 JobDetail 객체와 바인딩되어 있던 Job 구현체에 대해 WorkerThread들이 있는 ThreadPool로 실행 요청을 전달한다. ThreadPool로부터 Job을 배정받은 WorkerThread는 해당 Job 구현체의
execute()메서드를 호출하여 해당 작업을 실행한다. - 그러는 동안 SchedulerThread는 계속 다음에 실행될 Trigger들을 감시하며 위 과정을 반복한다.
글을 마치며…
이 글에서는 자바 진영에서 스케줄링 기능을 사용하기 위한 Quartz 라이브러리의 개념, 사용법 및 구조에 대해 살펴보았다. 그리고 이를 Spring Boot에서도 사용할 수도 있음을 보았다. 이 글에서는 스케줄링 및 Quartz에 대해서만 집중적으로 소개하고, 글이 길어진 관계로 몇몇 개념들을 생략하였는데, 다음의 개념들을 다른 포스트에서 소개하겠다.
- Spring Boot에서 기본으로 제공되는
@Scheduled을 이용한 스케줄링. - DB 클러스터링, fail-over, 로드 밸런싱에 대한 개념.
그리고 Spring Quartz하면 간혹 같이 언급되는 Spring Batch라는 것도 있는데, 나중에 기회가 있을 때 학습하여 글로 정리해보겠다.
References
[1] Quartz 공식 문서
Quartz Enterprise Job Scheduler
[2] Spring Quartz
Quartz Scheduler :: Spring Boot
[3] quartz
[Java] 스케줄링 & Spring Boot Quartz 이해하고 적용하기 -1 : 설정 및 간단예시
[4] quartz 상세
[Java] Spring Boot Quartz 상세 이해하기 -2 : 주요 메서드 및 흐름, 처리과정
[5] Introduction to Quartz | Baeldung
[7] Spring Quartz 사용
[8] [JAVA] Quartz 스케줄러 만들기 (2) - Listener
[9] Java Quartz Architecture Example - Java Code Geeks
[10] 스프링부트에서의 jobListener 등록법
[11] 서버 클러스터링 개념
[12] 스케줄링 & Spring Boot Quartz
[13] 스케줄링에 어떤 기술을 사용할까?(@Scheduled vs Spring Batch vs Quartz)
[14] Quartz 클러스터링 예시
[Quartz] Spring Boot에서 Quartz 클러스터 적용
[15] 스프링부트 제공 스케줄러 사용법
스프링부트 Scheduler 정해진 시간마다 동작 시키는법
[16] 스프링부트 제공 스케줄러 사용법 및 quartz와의 차이점
[spring] spring scheduler vs quartz scheduler
[17] 스프링부트 제공 스케줄러 사용 및 fixedDelay vs fixedRate
Spring Boot - 스케줄러 사용해보기 1. FixedDelay vs FixedRate
[18] fail-over
[19] cron
[20] quartz 기반 cron 표현식
[Java] quartz Job Scheduler 크론 (Cron) 과 크론 표현식
This content is licensed under
CC BY-NC 4.0
![]()
![]()
![]()

댓글남기기