[Spring Boot] Spring Data JPA
이 글에서는 Spring Boot 환경에서의 Spring Data JPA에 대해 살펴보겠다. JPA와 hibernate에 관한 내용은 [Spring][DB] JPA & Hibernate 페이지에서 다뤘으므로 해당 글 참고.
Spring Data JPA는 기존의 JPA를 더 쉽게 사용할 수 있도록 하는 Spring에서 제공하는 하위 프레임워크이다. Spring Data JPA는 다음의 특징들을 가지고 있다.
- 기존 JPA에서처럼 개발자가 직접 EntityManagerFactory, EntityManager, EntityTransaction 등의 객체를 사용하지 않아도 스프링 프레임워크에서 자동으로 관리해준다. 이로 인해 개발자는 JPA 사용에 한 발자국 더 쉽게 다가갈 수 있게 된다.
- 엔티티 매니저 객체에서는 persist(), merge(), delete(), find() 등의 메서드들을 제공하였다. 개발자가 이러한 엔티티 매니저에 접근하지 않기에 해당 메서드들을 직접 사용할 순 없겠지만, 대신 Spring Data JPA에서는 Repository란 새로운 개념을 제공한다. 여기서의 Repository는 DB의 테이블과 매핑된 자바 객체인 Entity 객체와 영속성 컨텍스트를 통해 DB에 접근하기 위해 사용되는 인터페이스이다. 이러한 JPA Repository 인터페이스에서는 findById(), findByMyFieldContaining(…) 등 이미 규격화된 메서드 네이밍 룰(naming convention)을 따라 메서드명을 정의하기만 하면 스프링 프레임워크에서 이를 자동으로 쿼리문으로 바꾼 후 DB 작업을 해준다. 따라서 네이밍 룰만 잘 알아두면 손쉽게 DB에 접근할 수 있다. 만약 Spring Data JPA에서 제공하는 네이밍 룰을 따라도 원하는 쿼리문을 작성할 수 없다면 메서드를 정의한 후, 어노테이션을 통해 JPQL을 개발자가 직접 작성하여 적용할 수도 있다. 권장되지는 않지만 JPQL로도 처리할 수 없는 정말 복잡한 쿼리문 작성이 필요하다 하더라도 Native SQL을 지원하기에 사용할 수 있다. Native SQL 사용은 권장되지는 않는다고 한다. 아무래도 더 간단하게 사용할 수 있는 메서드 및 JPQL 방식이 있기도 하고, 두 방법 모두 DB를 객체 지향적으로 다루기 위함인데 Native SQL을 사용하면 JPA를 사용하는 의미가 없기에 권장되지 않는 것으로 추측된다. 어쨌거나 메서드를 이용한 DB 접근, JPQL, SQL 이렇게 선택지가 다양하다는 것 자체는 장점이라 볼 수 있겠다.
- 스프링 부트와 함께 사용하면 기존 JPA에서 필요했던 persistence.xml 설정 파일도 필요없게 된다. (다만 DB 연동 정보는 스프링 부트로 프로젝트 생성 시 제공되는 application.properties 파일에 저장하면 된다.
.properties확장자 파일은 xml보다 좀 더 가독성 있는 구조라서 환경 변수 설정에 용이하다)
.png)
그림 1-1. Spring Data JPA의 기존 JPA 및 JDBC와의 관계 및 DB 작업 처리의 흐름을 그린 그림. hibernate가 JDBC를 조금 더 사용하기 쉽고 코드양도 단축하기 위해, 그리고 개발자가 직접 JDBC를 사용하지 않고 hibernate를 사용하게끔 JDBC를 “캡슐화”한 것이나 마찬가지이고, Spring Data JPA도 기존의 사용하기 어려운 hibernate를 더 쉽게 만들고 개발자가 이러한 Spring Data JPA를 사용하게끔 기존의 hibernate를 “캡슐화”한 것이나 마찬가지란 생각을 해서 위와 같이 포함관계로 그려보았다.
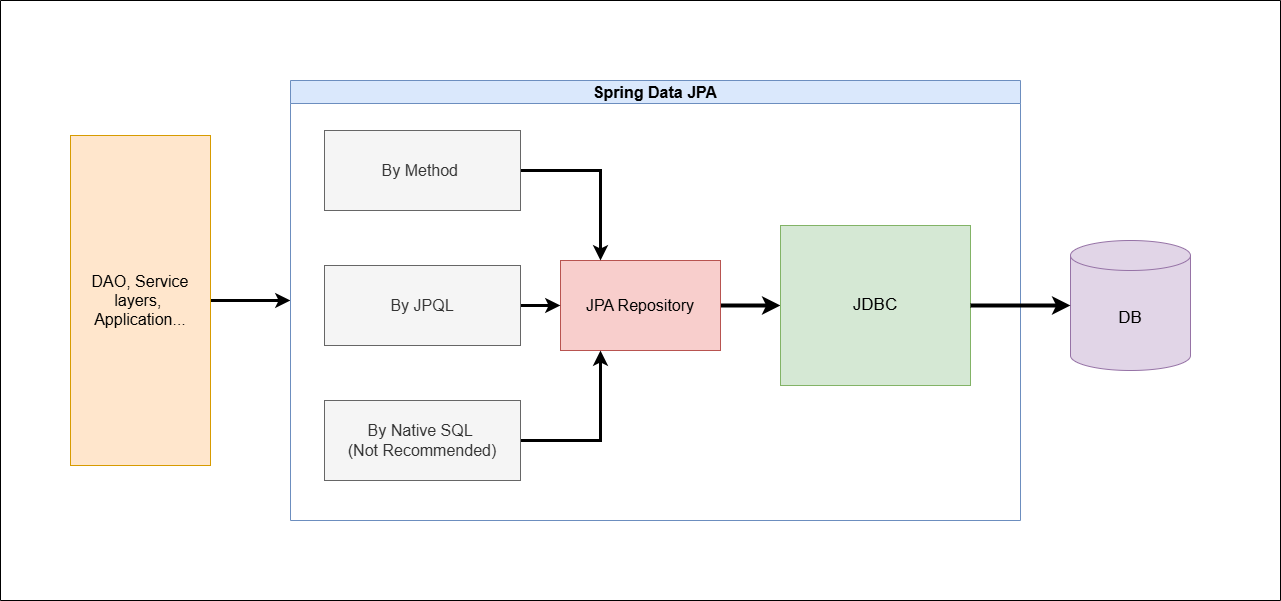
그림 1-2. JPA Repository 사용 구조.
이제 본격적으로 Spring Data JPA에 대해 살펴보도록 하겠다. 이 글에서는 코드 작성 시 Spring Boot, Gradle 및 Spring Web 환경에서 작성하여 실행할 것이니 참고 바란다.
이클립스에서 Spring Data JPA 준비
필자는 이클립스에서 다음과 같이 스프링 부트로 새 프로젝트를 만들었다.
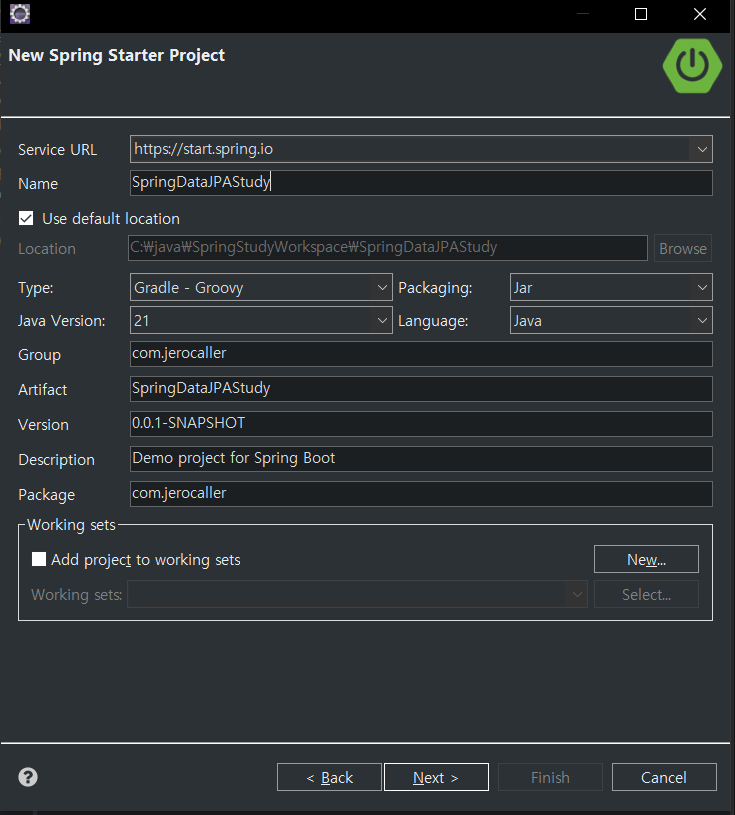
그 후 [Next]를 누르면 나오는 다음 창에서 다음 사진처럼 설정하였다.
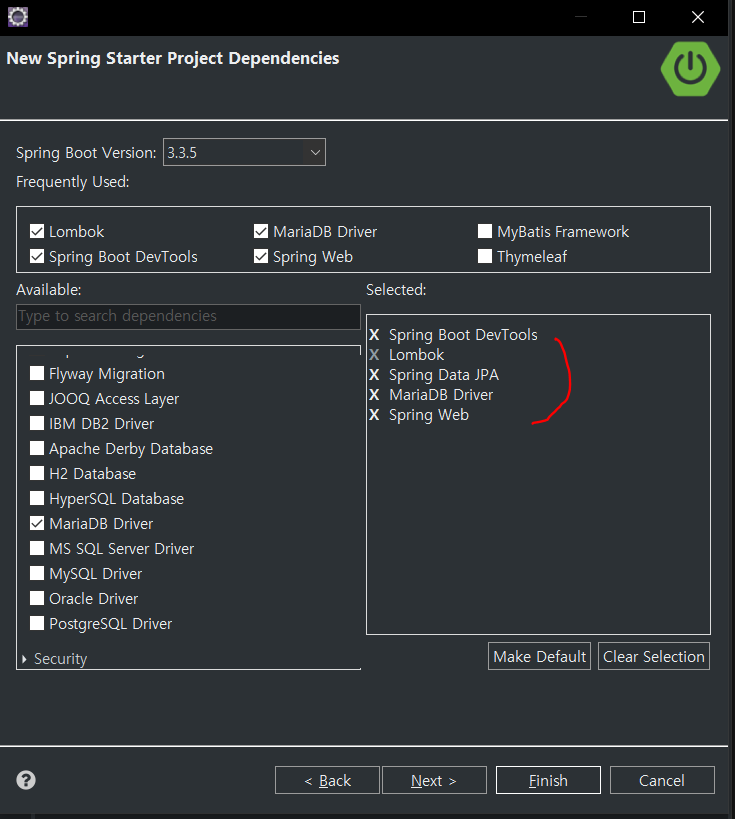
아무래도 JPA도 DB 연동 작업에 관련된 것이기에 Lombok과 MariaDB Driver도 추가하였다. 그리고 Spring Data JPA도 추가하였다.
그 후, src/main/resources 폴더 내부에 자동으로 생성된 application.properties 파일에 다음과 같이 DB 설정 및 JPA 설정 코드를 삽입하였다.
spring.application.name=SpringDataJPAStudy
# Mariadb server connect
spring.datasource.driver-class-name=org.mariadb.jdbc.Driver
spring.datasource.url=jdbc:mariadb://127.0.0.1:3306/mvc
spring.datasource.username=root
spring.datasource.password=1111
# jpa
spring.jpa.properties.hibernate.show_sql=true
spring.jpa.properties.hibernate.format_sql=true
spring.jpa.properties.hibernate.use_sql_comments=true
logging.level.org.hibernate.SQL=debug
logging.level.org.hibernate.type.descriptor.sql=trace
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MariaDBDialect
application.properties
DB에 연동할 정보(JDBC Driver, user name 등)를 작성하였고, 그 아래에 jpa 관련 설정들도 추가하였다. 위와 같은 형태로 설정하면 되겠다.
show_sql: 설정은 hibernate가 DB에 전송하는 모든 쿼리문들을 콘솔창에 출력하게 할 것인지에 대한 설정이다.format_sql: “show_sql”을 true로 설정하여 콘솔창에 SQL문이 보일 때 좀 더 사람이 보기 편하게 출력하도록 할 것인지를 설정한다.use_sql_comments: “show_sql” 설정을 true로 함으로써 콘솔창에 출력되는 모든 SQL문 양앞에 주석(/*, */)을 달아준다.type.descriptor.sql=trace: 외부에서 SQL문에 동적으로 값을 할당하고자 할 때 ? 문자를 사용한다. 이러한 ? 문자에 실제로 들어간 값이 무엇인지를 보고자 할 때 사용하는 설정.-
spring.jpa.properties.hibernate.dialect: 어떤 RDMBS의 방언(dialect)를 사용할 것인지를 설정한다. 여기서는 MariaDB를 사용할 것이기에org.hibernate.dialect.MariaDBDialect이란 값으로 설정하였다. 값으로 설정할 수 있는 각 RDBMS의 설정값들은 다음의 사이트의 “Class Summary” 탭에서 볼 수 있다. spring.jpa.hibernate.ddl-auto: JPA를 이용하면 자바 측에서 DB 테이블 생성에 관여할 수도 있다. 해당 옵션이 이 기능을 수행한다. 설정 가능한 설정값으로 다음이 존재한다.- create : 애플리케이션 실행 시 DB 내 기존 테이블이 있다면 이를 삭제하고 새로 생성. 즉, 애플리케이션이 실행될 때마다 자바 클래스로 정의된 Entity 클래스의 정보가 DB 테이블로 생성된다.
- create-drop : create와 비슷하나, 애플리케이션 종료 시 DB 내 테이블을 삭제한다.
- update : Entity 객체의 구조가 바뀐다면 이에 맞게 DB 내 테이블도 자동으로 수정한다.
- validate : Entity와 DB 내 테이블이 제대로 매핑되는지 확인한다. 만약 두 정보가 서로 다르면 에러가 발생한다.
- none : ddl-auto 기능 자체를 사용하지 않는다. 이 설정값 자체를 명시하지 않으면 기본값으로 설정되는 것으로 추정된다.
spring.jpa.hibernate.ddl-auto 설정 자체를 application.properties 파일에 명시하지 않으면 자바에서 Entity 객체를 만든다고 해서 DB에 테이블이 새로 생성되거나 기존 테이블이 삭제되지는 않음을 봤었다. 따라서 이 경우 기본적으로 none으로 설정되는 것으로 추측된다. 참고로 이 글에서는 필자가 이전에 개인적으로 만들었던 DB 내 테이블을 사용할 것이기에 ddl-auto 기능은 사용하지 않을 것이다.
Entity
다음은 Entity 클래스 코드이다.
package com.jerocaller.model.entity;
import jakarta.persistence.Column;
import jakarta.persistence.Entity;
import jakarta.persistence.Id;
import jakarta.persistence.Table;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Getter;
import lombok.NoArgsConstructor;
@Entity
@Table(name = "site_users") // 어차피 테이블명과 같으므로 생략 가능.
@Getter
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class SiteUsers {
@Id
@Column(name = "member_id") // 테이블 내 컬럼명과 동일하므로 생략 가능.
private int memberId;
private String signUpDate;
private int classNumber;
private int mileage;
private String username;
private Integer averPurchase;
private String recommBy;
}
예제 1-1
클래스명은 실제 DB 내 테이블명과 똑같이 맞췄다. 위 클래스 내부에는 실제 DB 내 “site_users”라는 테이블 내 필드명들을 따라 작성한 것이다. 실제 테이블에는 다음의 필드명들이 존재한다.
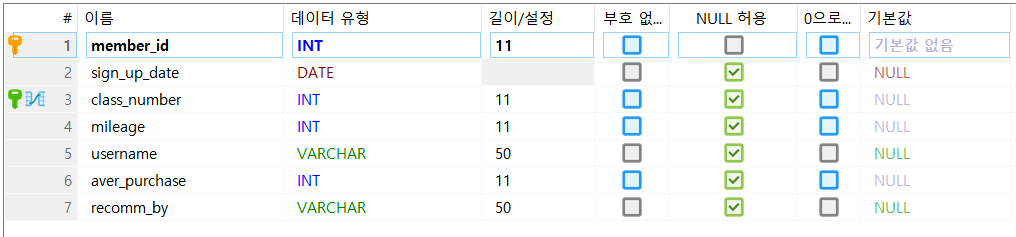
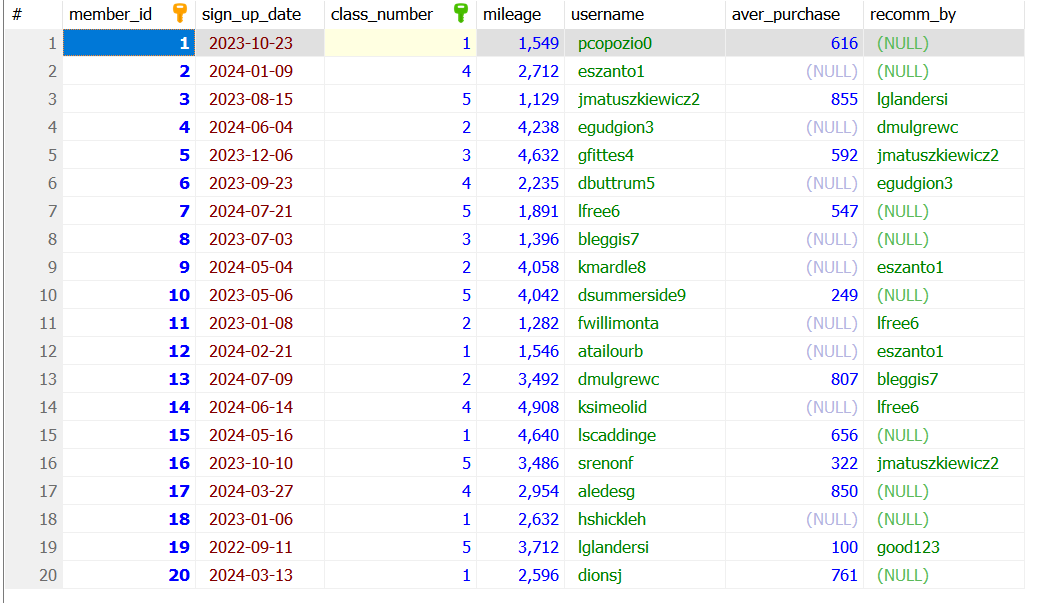
그런데 자세히보면 DB 내 테이블 내 컬럼명들은 “class_number”와 같이 스네이크 케이스로 작성되어 있는데, 자바 클래스 내 필드명은 camel case로 작성되어 있다. 두 이름이 엄연히 다름에도 실제로 DB 작업이 잘된다. 그 이유는 자바 클래스 내에서 필드명 또는 클래스명에서 맨 첫 글자를 제외한 나머지 대문자들은 DB 작업 시 자동으로 언더바와 소문자로 변경되기 때문이다. 즉, 카멜 케이스가 자동으로 스네이크 케이스로 변하기 때문이다. 클래스명을 “SiteUsers”라 하면 테이블로 변경 시 “site_users”로 변경된다. “classNumber”는 “class_number”와 같이 변경된다.
이를 확인하기 위해 일부러 클래스명의 맨 끝에 s를 빼어 “SiteUser”라 해봤을 때 다음의 에러 메시지를 볼 수 있다.
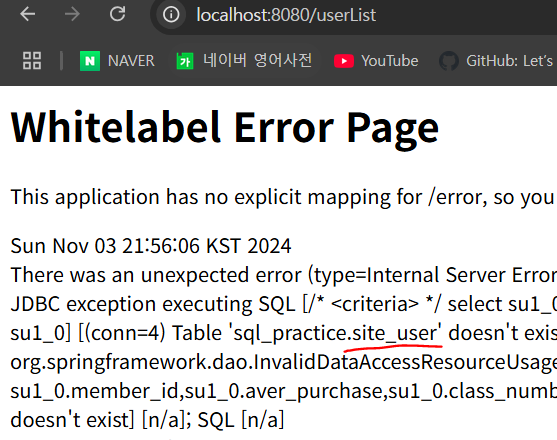
정말로 “SiteUser”가 “site_user”로 변경되었음을 확인할 수 있다.
한 편, 위 코드에서 나온 또는 나오지 않은 Entity 관련 어노테이션을 정리하면 다음과 같다.
Entity Annotations
@Entity: 해당 클래스가 Entity 클래스임을 명시.ddl-auto를 사용하지 않는 경우 기존에 존재하는 DB 내 특정 테이블과 매핑된다.@Table: Entity 클래스명과 매핑될 테이블명이 서로 다를 경우 사용하는 어노테이션으로, 만약 맞게 설정했다면 해당 어노테이션은 생략해도 된다.name = "테이블명": 매핑할 테이블명을 적는다. 예를 들어 엔티티 클래스명이MyEntity이라고 하고,@Table(name = "user")이라 하면 ‘user’ 테이블과 매핑된다. 만약 이 어노테이션을 생략할 경우, ‘my_entity’라는 테이블과 매핑된다.
@Id: 테이블 내 기본키(PK)가 걸린 컬럼과 매핑될 엔티티 클래스 내 필드에 거는 어노테이션이다. 즉, 해당 필드가 테이블의 기본키 컬럼임을 명시하는 어노테이션이다. 참고로 Entity를 사용하려면 반드시 기본키가 존재해야 하며, 그래서 Entity 클래스 내에서@Id어노테이션이 특정 필드에 적용되어야 한다.@GeneratedValue:@Id어노테이션이 적용된 필드에 같이 적용할 수 있는 어노테이션이다(이 어노테이션을 필수로 사용해야 하는 건 아니다).@GeneratedValue(strategy = GenerationType.AUTO)와 같이 사용할 수 있다. 이 어노테이션이 적용된 필드를 어떻게 자동 생성할 지 그 방법을 명시하기 위한 어노테이션이다.- strategy 속성에 적용 가능한 값들 (GenerationType라는 Enum 내의 정해진 상수값을 이용한다)
AUTO: 기본값. 어떤 dialect를 사용하는 지를 자동으로 감지하여IDENTITY,SEQUENCE,TABLE값 중 하나를 자동으로 택한다. 매핑된 테이블 내 PK가 걸린 필드를 토대로 생성한다.IDENTITY:AUTO와 같이 해당 필드에auto_increment가 적용된다. 그런데 MariaDB, MySQL 사용 시AUTO를 사용하는 것은 불안정하다고 한다. 그래서 이 경우AUTO대신 이 값을 사용한다고 한다. 기본값 생성을 DB에 위임하는 방식. DB의 AUTO_INCREMENT와 같은 역할을 하여 새로운 레코드가 삽입될 때마다 자동으로 1씩 증가하여 삽입된다고 한다.SEQUENCE,TABLE값도 있다. 해당 값들의 기능을 아직 제대로 이해하지 못하여 여기까지만 언급하겠다.
- strategy 속성에 적용 가능한 값들 (GenerationType라는 Enum 내의 정해진 상수값을 이용한다)
@Column: Entity 클래스의 필드명과 테이블의 컬럼명을 매핑시키기 위한 어노테이션. 이미 이름을 맞게 지었다면 생략해도 되는 어노테이션이다.name요소를 사용하여 테이블 내 실제 컬럼명을 작성하면 그에 맞게 매핑된다. 또한 해당 어노테이션에는 그 외 다른 요소들도 지원한다.nullable: true, false 중 하나값을 적용할 수 있으며, true 시 해당 필드만 생략하여 새 레코드를 삽입해도 되도록 하고, false 시 해당 필드에도 반드시 값을 입력하도록 강제할 수 있다.insertable: true, false 중 하나의 값을 사용. Entity에서 해당 필드에 새 값을 입력할 수 있게 할 것인지 결정.updatable: true, false 중 하나의 값을 사용. Entity에서 해당 필드의 값을 수정할 수 있게 할 것인지 결정.columnDefinition: 자바에서 제공하는 primitive type 또는 객체 타입에는 없는 타입이 DB에는 존재한다. TEXT 등이 그 예인데,columnDefinition속성값에 이를 명시하여 어떤 타입인지 자바 컴파일러에 알려줄 수 있다.length: 입력값의 최대 길이 설정. DB에서VARCHAR(20)이라고 되어있으면length = 20이라고 명시할 수 있다.unique: 해당 필드에 unique key가 걸려있는 경우 이를 명시할 때 사용. true, false 중 하나를 명시한다.- 이 외에도 여러 요소들이 있다.
@PrePersist: 메서드에 적용 시 persist, 즉 데이터가 저장되기 전에 해당 메서드가 수행되도록 한다. 특정 필드값을 초기화하고자 할 때 사용할 수 있다.@Entity public class MyEntity { // 생략 private LocalDateTime registerDate; @PrePersist private void initDate() { registerDate = LocalDateTIme.now(); } }
JPA Repository
Spring Data JPA에서는 Repository 인터페이스를 제공한다. 이 인터페이스는 Entity 객체를 이용하여 DB에 대한 CRUD 작업을 영속성 컨텍스트를 통해 수행해주는 인터페이스로, 기본 메서드들을 제공하기에 이 메서드를 호출하기만 하면 DB 작업을 복잡한 코드 없이 간단하게 수행할 수 있다는 큰 장점이 있다. DAO의 역할을 한다고 볼 수 있으며, DB layer에 접근할 수 있는 인터페이스이다.
원래 인터페이스라 하면 그 추상 메서드를 구현 클래스에서 구현하여 사용해야하지만, 이 인터페이스는 그냥 정의만 해도 기본적인 DB의 CRUD 작업을 수행할 수 있으며, 설령 개발자가 원하는 기본 메서드가 없어도 정해진 네이밍 룰(naming convention)에 따라 메서드명을 JPA Repository 인터페이스에 정의하거나 JPQL을 사용하여 개발자가 원하는 조금 더 복잡한 쿼리문 작성도 가능하다. 기존의 JDBC 직접 사용 방식에 비해선 훨씬 사용 방법이 쉽다고 볼 수 있겠다.
Spring Data JPA에서 제공하는 Repository 인터페이스는 다음 그림과 같은 상속 관계를 가진다.
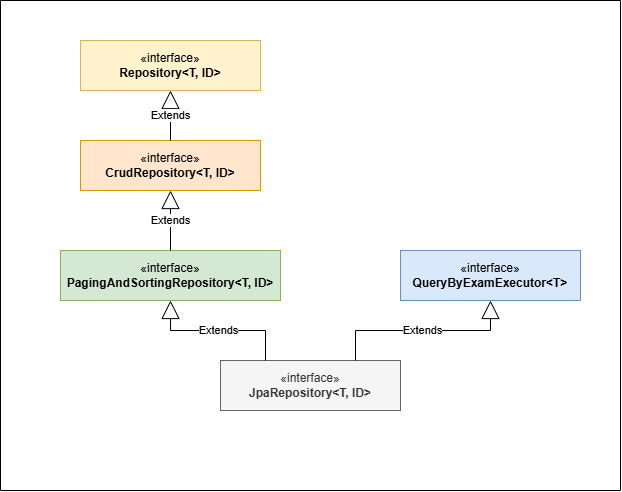
그림 2-1. Spring Data JPA Repository 인터페이스들의 상속 관계.
CrudRepository 인터페이스에서는 이름 그대로 CRUD를 위한 기본적인 메서드를 제공한다. save(), findById() 등이 그 예이다.
한 편 PagingAndSortingRepository 인터페이스에서는 페이징 및 정렬 기능을 제공한다. 조회된 데이터를 화면에 출력할 때 데이터가 너무 많으면 페이징 기능을 사용하기도 하고, 원하는 목적에 따라 정렬 기준을 세워 출력되도록 하고자 할 때 이 인터페이스를 사용한다.
QueryByExampleExecutor 인터페이스에서는 다른 Repository 인터페이스에는 없는 더 많은 CRUD 메서드를 제공한다. findOne(), findAll() , count() , exists() 등이 그 예이다.
사실 JpaRepository 인터페이스가 위에서 언급한 모든 Repository 인터페이스를 상속하는 셈이기 때문에 이 인터페이스를 사용하면 위에서 언급한 모든 기능을 사용할 수 있게 된다.
코드 상으로는 다음과 같이 사용하면 된다.
package com.jerocaller.model.repository;
import org.springframework.data.jpa.repository.JpaRepository;
import com.jerocaller.model.entity.SiteUsers;
public interface SiteUserRepository
extends JpaRepository<SiteUsers, Integer> {
}
예제 2-1
지금은 별도의 쿼리 수행이 불필요하기에 인터페이스 안에 아무것도 정의하지 않은 상태이다. 이렇게 개발자가 아무것도 정의하지 않았음에도 JpaRepository에서 기본적인 DB 작업 관련 메서드들을 제공하기에 위 코드와 같이 인터페이스 내부에 아무것도 작성하지 않아도 되는 것이다.
다음은 Jpa Repository 인터페이스 내에서 쿼리문 생성을 위한 메서드명 naming convention의 일부이다. (스프링 공식 사이트(References [7])에서는 이러한 메서드를 “Query Method”라고 부르고 있다)
find[엔티티명]~: 원래 find 이름 바로 뒤에 엔티티명이 오나, 생략 가능하다. 해당 엔티티 객체와 매핑된 테이블로부터 데이터를 조회하겠다는 뜻이다. Native SQL문으로 따지면SELECT (컬럼명) FROM (테이블명)과도 같다.findBy필드명(param): 특정 필드명을 만족시키는 엔티티 객체만 조회. JPQL로 번역하면SELECT e FROM MyEntity e WHERE e.필드명 = :param과도 같다.findDistinctBy필드명: Native SQL에서의distinct와 같다.findBy필드명1And필드명2(param1, param2): And는 말 그대로 둘 이상의 조건문을 동시에 만족하는 데이터만 조회할 때 쓰인다. JPQL의WHERE 필드명1 = ?param1 AND 필드명2 = ?param2과도 같다.
이 외에도 메서드명에 작성될 수 있는 다양한 키워드들이 있다. 모든 키워드에 대해선 다음 사이트를 참고하면 되겠다.
JPA Query Methods :: Spring Data JPA
다음은 쿼리 메서드를 이용하여 특정 조건의 데이터만을 조회하는 예제이다.
package com.jerocaller.model.repository;
import java.util.List;
import org.springframework.data.jpa.repository.JpaRepository;
import com.jerocaller.model.entity.SiteUsers;
public interface SiteUserRepository
extends JpaRepository<SiteUsers, Integer> {
/**
* 클래스 넘버가 특정 넘버이고, 추천자가 있는 모든 유저 조회.
* @param classNumber
* @return
*/
List<SiteUsers> findByClassNumberAndRecommByNotNull(int classNumber);
/**
* 마일리지가 minimum 이상 maximum 이하인 유저들을 마일리지 기준 내림차순으로 조회.
* @param minimum
* @param maximum
* @return
*/
List<SiteUsers> findByMileageBetweenOrderByMileageDesc(int minimum, int maximum);
}
예제 2-2. SiteUserRepository.java
위 코드에서 naming convention에 따라 쿼리 메서드를 작성하였다. 아래 코드들은 위 repository에서 새로 생성한 쿼리 메서드를 사용하기 위한 코드들이다.
package com.jerocaller.model.service;
import java.util.List;
import java.util.stream.Collectors;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import com.jerocaller.model.DtoEntityConverter;
import com.jerocaller.model.dto.SiteUsersDto;
import com.jerocaller.model.entity.SiteUsers;
import com.jerocaller.model.repository.SiteUserRepository;
@Service
public class Business {
@Autowired
private SiteUserRepository repository;
/**
* 모든 필드를 포함하여 모든 데이터 가져오기.
* @return - Entity 객체를 Dto 객체로 변경하여 반환.
*/
public List<SiteUsersDto> getUserAll() {
/*
return repository.findAll()
.stream()
.map(DtoEntityConverter :: toDto)
.collect(Collectors.toList());
*/
return resultToDtos(repository.findAll());
}
public List<SiteUsersDto> getUsersByClassNumberAndRecommByNotNull(int classNumber) {
/*
return repository.findByClassNumberAndRecommByNotNull(classNumber)
.stream()
.map(DtoEntityConverter :: toDto)
.collect(Collectors.toList());*/
return resultToDtos(repository.findByClassNumberAndRecommByNotNull(classNumber));
}
public List<SiteUsersDto> getUsersByMileageBetween(int minimum, int maxinum) {
return resultToDtos(repository.findByMileageBetweenOrderByMileageDesc(minimum, maxinum));
}
private List<SiteUsersDto> resultToDtos(List<SiteUsers> entityResults) {
return entityResults.stream()
.map(DtoEntityConverter :: toDto)
.collect(Collectors.toList());
}
}
예제 2-3. Business.java
package com.jerocaller.controller;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import com.jerocaller.model.service.Business;
@Controller
public class MyController {
@Autowired
private Business business;
@GetMapping("/")
public String index() {
return "/index";
}
@GetMapping("/userList")
public String userList(Model model) {
model.addAttribute("users", business.getUserAll());
return "/userList";
}
@GetMapping("/userList2")
public String userList(
Model model,
@RequestParam("classNumber") int classNumber
) {
model.addAttribute("users", business.getUsersByClassNumberAndRecommByNotNull(classNumber));
return "/userList";
}
@GetMapping("/userList3")
public String userList(
Model model,
@RequestParam("min") int minimum,
@RequestParam("max") int maximum
) {
model.addAttribute("users", business.getUsersByMileageBetween(minimum, maximum));
return "/userList";
}
}
예제 2-4. MyController.java
<!DOCTYPE html>
<html xmlns:th="https://www.thymeLeaf.org">
<head>
<meta charset="UTF-8">
<title>Insert title here</title>
</head>
<body>
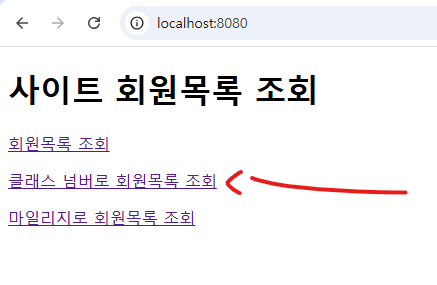
<h1>사이트 회원목록 조회</h1>
<p><a th:href="@{/userList}">회원목록 조회</a></p>
<p><a th:href="@{/userList2?classNumber=1}">클래스 넘버로 회원목록 조회</a></p>
<p><a th:href="@{/userList3?min=3000&max=5000}">마일리지로 회원목록 조회</a></p>
</body>
</html>
예제 2-5. index.html
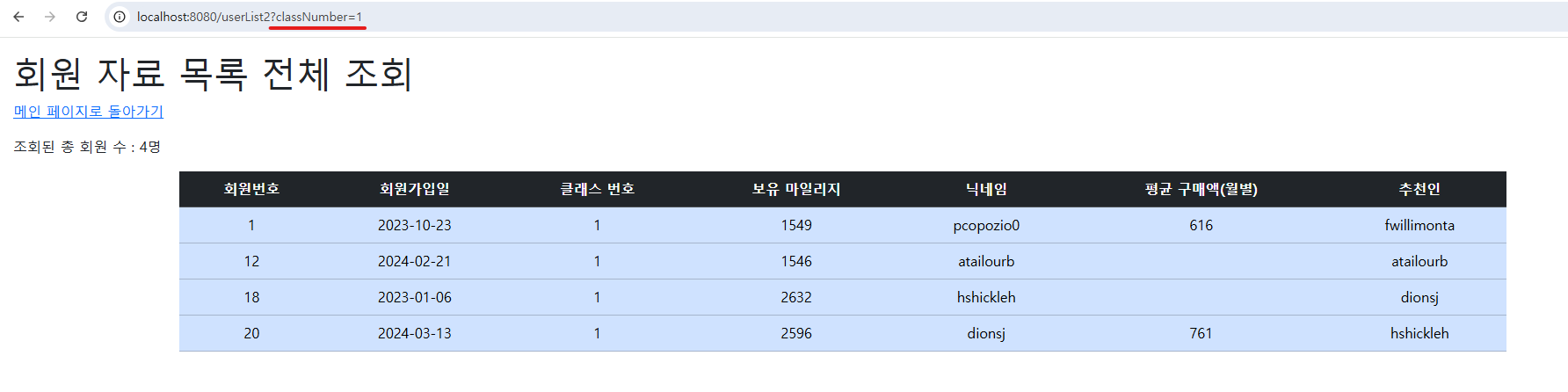
1, 2번째 사진에서는 “클래스 넘버로 회원목록 조회”를 한 모습으로, findByClassNumberAndRecommByNotNull 이란 쿼리 메서드를 사용한 것이다. 여기서는 HTTP URL 요청에 classNumber를 1로 주었다. 따라서 클래스 넘버가 1이면서 동시에 추천인이 존재하는 회원들만 조회된 것이다.
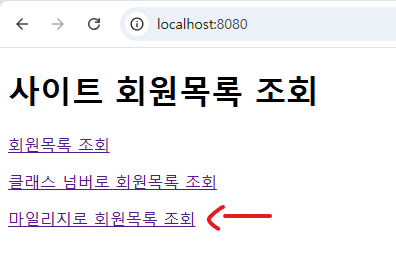
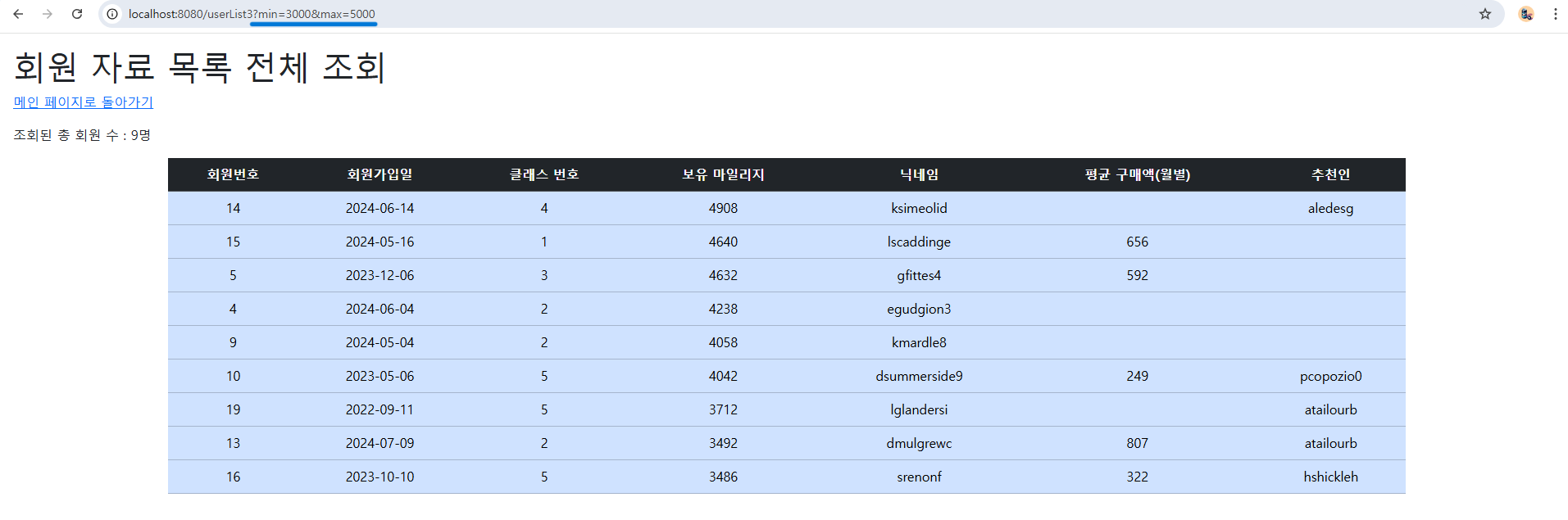
3, 4번째 사진에서는 “마일리지로 회원목록 조회”하는 페이지로, a 태그 링크에 마일리지가 3000이상 5000이하인 회원들을 조회하는 모습이다. 이렇게 Repository 내 쿼리 메서드를 정의하기만 해도 원하는 데이터를 조회할 수 있음을 알 수 있다.
필자는 현재 각자 다른 환경에서 작업을 하기에 DB 내용이 전혀 다르므로 참고 바란다. 그래서 같은 쿼리 메서드를 사용하더라도 DB 내 데이터 자체가 다르기에 결과물이 다를 수 있다. 한 예로, 클래스 넘버와 추천자를 이용한 첫 번째 사진에서는 필자가 사용하는 환경이 달라 어떤 컴퓨터에서는 DB 내 데이터 자체가 달라 단 하나의 데이터만 나온다.
JPQL In Repository
JPQL은 Java Persistence Query Language의 줄임말로, 말 그대로 JPA 내에서 사용하는 쿼리문을 의미한다. SQL문과 거의 비슷하나, JPQL에서는 Entity 객체와 그 필드명을 이용하여 쿼리문을 작성한다는 것이 차이점이다.
예를 들어 엔티티 클래스명이 SiteUser라 하고, 해당 객체에 nickname과 classNumber라는 필드가 있다고 한다면
// Pseude code
@Entity
public class SiteUser {
@Id
private String id;
private String nickname;
private int classNumber;
}
예제 3-1.
JPQL에서는 다음과 같이 사용할 수 있다.
SELECT s FROM SiteUser s WHERE s.nickname = 'kimquel' AND s.classNumber = 1
SiteUser -> 엔티티 객체 타입
s.nickname, s.classNumber -> 엔티티 객체 필드
사실 앞서 본 예제 2-2의 쿼리 메서드를 JPQL로 변환하면 다음과 같다.
// SELECT s FROM SiteUsers s WHERE s.classNumber = ?1 AND s.recommBy IS NOT NULL
List<SiteUsers> findByClassNumberAndRecommByNotNull(int classNumber);
// SELECT s FROM SiteUsers s WHERE s.mileage BETWEEN ?1 AND ?2
List<SiteUsers> findByMileageBetweenOrderByMileageDesc(int minimum, int maximum);
그리고 Jpa repository 인터페이스를 상속받은 인터페이스 내에서는 메서드에 @Query("SELECT ...") 어노테이션을 적용하면 해당 JPQL을 그 메서드에 적용할 수 있다. 그래서 위에서 사용한 쿼리메서드는 사실 다음과 같이 작성해도 똑같이 작동한다.
package com.jerocaller.model.repository;
import java.util.List;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.query.Param;
import com.jerocaller.model.entity.SiteUsers;
public interface SiteUserRepository
extends JpaRepository<SiteUsers, Integer> {
/**
* 클래스 넘버가 특정 넘버이고, 추천자가 있는 모든 유저 조회.
* @param classNumber
* @return
*/
List<SiteUsers> findByClassNumberAndRecommByNotNull(int classNumber);
/**
* 마일리지가 minimum 이상 maximum 이하인 유저들을 마일리지 기준 내림차순으로 조회.
* @param minimum
* @param maximum
* @return
*/
List<SiteUsers> findByMileageBetweenOrderByMileageDesc(int minimum, int maximum);
@Query("SELECT s FROM SiteUsers s WHERE s.classNumber = ?1 AND s.recommBy IS NOT NULL")
List<SiteUsers> findByClassNumberAndRecommBy(int classNumber);
@Query("SELECT s FROM SiteUsers s WHERE s.mileage BETWEEN :min AND :max")
List<SiteUsers> findByMileage(@Param(value = "min") int minimum, @Param(value = "max") int maximum);
}
예제 3-2
참고로 JPQL에 특정 값을 동적으로 받아 넣고자 할 때에는 두 가지 방법이 있다. 하나는 ?1 , ?2 와 같이 사용한 후 메서드의 매개변수에 차례대로 값을 넣는 순서에 의한 매핑 방법이다. 위 예제의 findByClassNumberAndRecommBy 메서드와 그 JPQL을 보면, JPQL 내부에 작성된 ?1 자리에 매개변수 int classNumber 에 담길 인자값이 전달되는 방식인 것이다. JPQL에 삽입하고자 하는 값들이 여러개 이면 JPQL 에서는 차례대로 ?1, ?2, ?3 등을 사용하고, 그 순서에 맞게 매개변수들을 정의하면 된다.
또 다른 방법은 이름 기반 매핑 방식인 :변수명 을 JPQL 내에서 사용하는 것이다. 위 예제에서의 findByMileage 메서드가 이를 사용하고 있다. 이 때 매개변수에서는 매개변수 앞에 @Param(value = "이름") 어노테이션을 적용해야 한다. @Param() 어노테이션 내에 명시된 이름과 자바 매개변수명이 꼭 같을 필요는 없다. 다만 @Param 어노테이션 내에 명시한 이름과 JPQL에 콜론(:)과 함께 명시한 이름은 같아야 한다.
만약 JPQL이 아닌 Native SQL, 즉 원래 DB에서 사용하는 SQL를 사용하고자 한다면 @Query(value = "...", nativeQuery = true) 와 같이 사용하면 된다. Native SQL을 사용하더라도 ?1 또는 :var 와 같은 매핑 방식은 그대로 적용 가능하다.
Bulk 연산과 @Modifying
@Query 어노테이션을 이용하여 JPQL을 적용할 때 UPDATE, INSERT, DELETE와 같이 데이터의 변경에 영향을 주는 DML로 작성이 되었다면 해당 JPQL이 데이터 변경을 위한 DML임을 알리기 위해 @Modifying 어노테이션도 같이 적용해주어야 한다. 적용을 하지 않으면 에러가 발생한다. 이는 DDL 언어도 마찬가지이다. (SELECT 문은 데이터를 조회하는 키워드지 변형하는 키워드가 아니므로 적용하지 않는다) 이렇게 DML로 작성된 @Query 어노테이션이 적용된 메서드에 대해서는 실제 데이터 변경 작업에 대해서 bulk 연산이 일어나게 된다.
Bulk 연산이란, update, delete문에 대해, 즉 데이터의 수정과 삭제 시 하나의 쿼리문으로 한꺼번에 여러 개의 데이터에 대해 수정 또는 삭제 작업을 하는 것을 일컫는다. hibernate의 경우 insert문도 이에 해당된다.
JPA에서 이러한 Bulk 연산을 수행하면 해당 연산은 영속성 컨텍스트를 거치지 않고 바로 DB에 반영한다는 특징을 가지고 있다. 만약 수정하고자 하는 데이터가 몇천, 몇만 건이라고 하면 영속성 컨텍스트를 거쳐야 할 때 수정의 경우, 모든 대상 데이터들에 대한 dirty checking이 수행되어야 한다. 이러한 작업은 대용량의 데이터들에 대해서 성능이 떨어진다. 따라서 벌크 연산을 통해 하나의 쿼리를 이용하여 여러 데이터들을 한꺼번에 수정 또는 삭제를 하는 것이다. 순수 JPA에서는 EntityManager 객체의 executeUpdate() 메서드를 호출하면 벌크 연산을 할 수 있다.
이렇게 영속성 컨텍스트를 거치지 않고 바로 DB에 반영하는 벌크 연산의 특징에 의해, 벌크 연산 후에도 계속 JPA를 이용하여 DB 작업을 해야 할 때 실제 DB와 영속성 컨텍스트 내 데이터들의 내용이 다르다는 문제가 발생한다. 이러한 문제를 해결하기 위해서는 영속성 컨텍스트를 비워주는 @Modifying(clearAutomatically = true) 속성을 사용해야 한다. 해당 속성을 사용하면 결국에는 DB 내 변경된 데이터들의 내용과 영속성 컨텍스트 내 데이터 내용이 같게 된다. 이렇게 되는 것에는 다음의 순서들을 거쳐 벌크 연산이 진행되기 때문이다.
- 벌크 연산이 DB에 직접 전달되어 수행된다.
- 벌크 연산 수행 이후에는
clearAutomatically = true라는 속성에 의해 영속성 컨텍스트 내에 있던 기존 엔티티 객체들의 참조값이 초기화되어 소멸된다. - 벌크 연산 수행 이후 DB 내 데이터 조회 시도 시 영속성 컨텍스트에는 아무런 영속 객체가 없기에 DB로부터 데이터를 조회한 후 이 데이터들을 포함하는 새로운 엔티티 객체들이 생성되어 영속성 컨텍스트에 업로드된다.
- 영속성 컨텍스트에 방급 업로드 된 새 엔티티 객체를 조회해온다. 이로 인해 DB 내 데이터와 영속성 컨텍스트 내의 엔티티 객체에 담긴 데이터 내용이 같을 수밖에 없다.
다음은 위에서 설명한 내용을 정리한 그림이다. 바로 아래의 그림은 clearAutomatically = true 속성을 적용하지 않은 상태에서 벌크 연산 후 데이터 조회 시 일어나는 과정을 그린 그림이다.
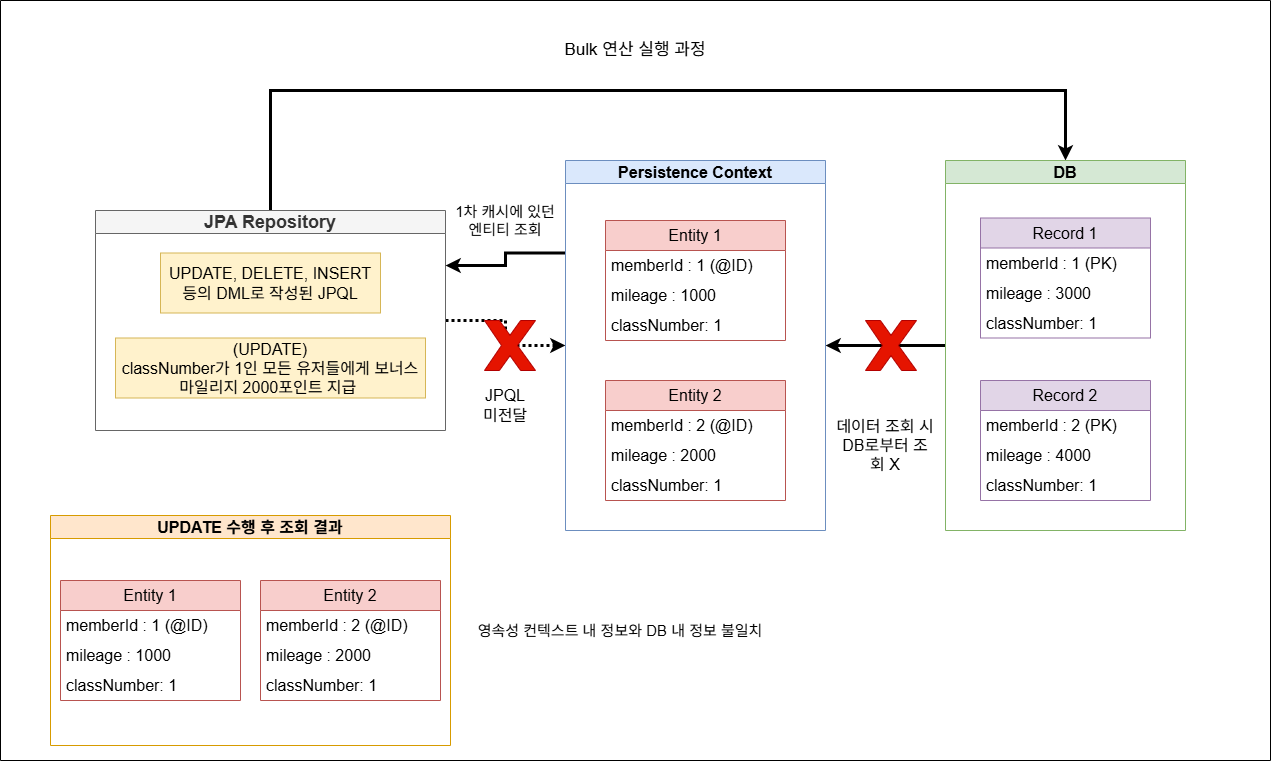
그림 3-1. DML 대상 JPQL 실행 시 벌크 연산의 흐름과 그 후 데이터 조회 순서를 표현한 그림.
다음은 반대로 clearAutomatically = true 을 적용했을 때의 bulk 연산 수행 후 데이터를 조회하는 과정을 그린 그림이다.
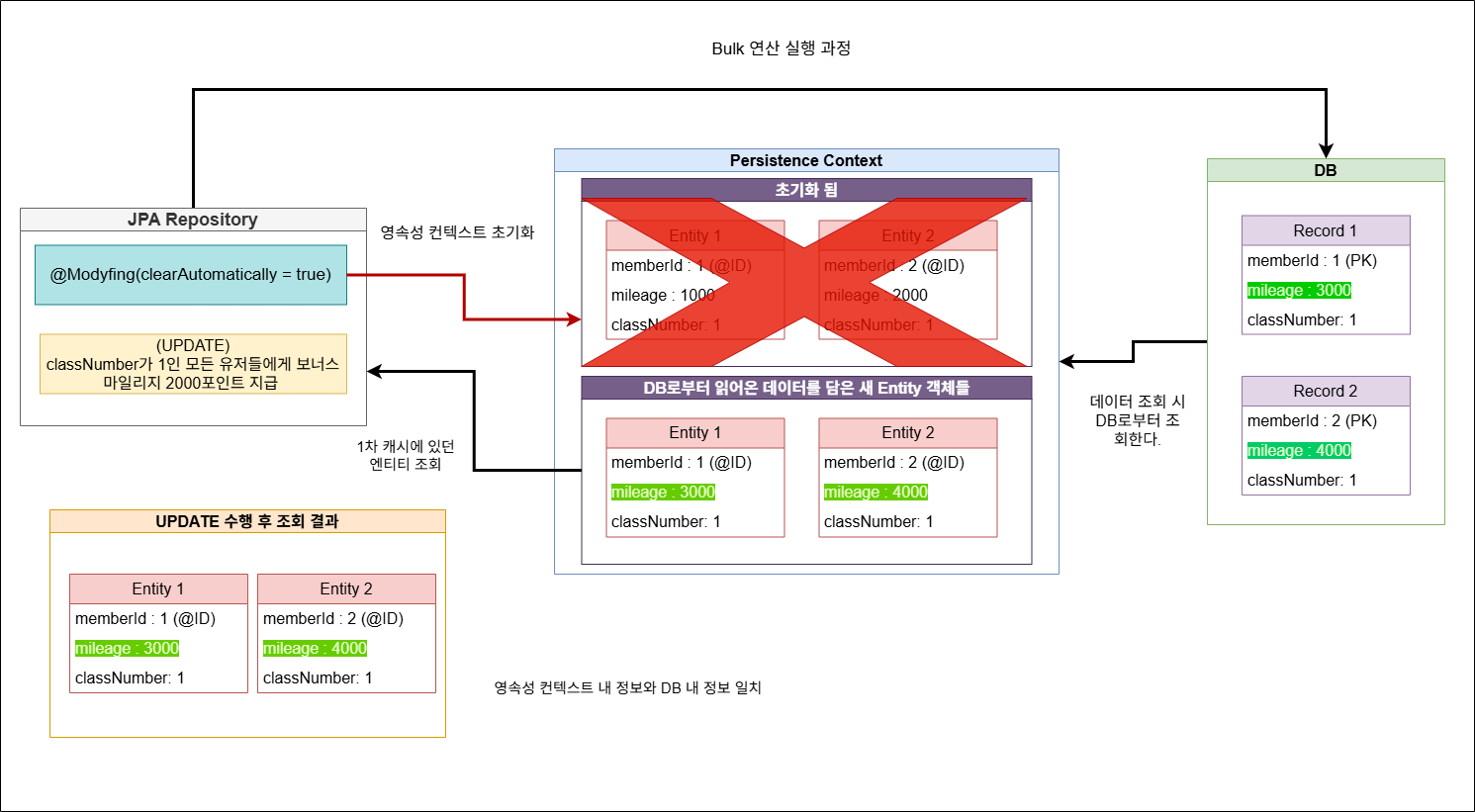
그림 3-2. clearAutomatically = true로 준 경우의 bulk 연산 후 데이터 조회 흐름도.
참고로 위에서 언급한 벌크 연산은 오로지 DML이 사용된 @Query 어노테이션을 적용한 메서드에서만 일어난다. 쿼리 메서드나 JPA Repository에서 기본으로 제공하는 메서드를 이용하면 벌크 연산을 비롯한 위에서 언급한 과정들이 일어나지 않는다. 만약 대량의 데이터들에 대한 변경 작업이 필요하다면 쿼리 메서드 대신 JPQL을 이용하여 벌크 연산을 함으로써 데이터 변경 작업의 성능 향상을 고려해볼 수도 있겠다.
이제 @Modifying 어노테이션을 코드에 적용해보겠다. 다음은 위 그림대로 class number가 1등급인 모든 회원들에게 보너스 마일리지 2,000포인트를 지급하기 위해 작성한 JPQL이다. UPDATE로 진행되며, 일단 @Modifying 어노테이션 자체를 적용하지 않았을 때 어떤 일이 발생하는 지 살펴보는 코드이다.
@Query("UPDATE SiteUsers s SET s.mileage = s.mileage + ?1 WHERE s.classNumber = ?2")
int giveBonusMileage(int bonus, int classNumber);
예제 4-1. SiteUserRepository.java에 새로 추가한 내용.
위 코드의 실행을 위해 다음의 코드들을 추가하였다.
/**
* 특정 클래스 넘버에 해당하는 모든 유저들에게 보너스 마일리지 지급.
* DB에는 추가된 마일리지로 업데이트된다.
* @param bonus
* @param classNumber
* @return - 업데이트 성공 시 true, 실패 시 false
*/
public boolean giveBonusForClassNumber(int bonus, int classNumber) {
int result = repository.giveBonusMileage(bonus, classNumber);
if (result == 0) return false;
return true;
}
예제 4-2. Business.java에 추가한 내용
@GetMapping("/bonus")
public String goToBonusPage() {
return "bonus";
}
@PostMapping("/bonus")
public String bonus(
Model model,
@RequestParam("classNumber") int classNumber,
@RequestParam("bonus") int bonus
) {
boolean result = business.giveBonusForClassNumber(bonus, classNumber);
if (!result) return "redirect:/failed";
return "redirect:/";
}
@GetMapping("/failed")
public String goToFailPage() {
return "failed";
}
예제 4-3. MyController.java에 추가한 내용
<!DOCTYPE html>
<html xmlns:th="https://www.thymeLeaf.org">
<head>
<meta charset="UTF-8">
<title>Insert title here</title>
</head>
<body>
<h2>보너스 마일리지 지급해주기</h2>
<form th:action="@{/bonus}" method="post">
<p>지급 대상 클래스 넘버 : <input type="number" name="classNumber"> </p>
<p>지급할 보너스 마일리지 : <input type="number" name="bonus"></p>
<button type="submit">지급하기</button>
</form>
<p>지급 후 전체 회원 목록으로 자동 이동합니다.</p>
<p><a th:href="@{/}">메인으로 돌아가기</a></p>
</body>
</html>
예제 4-4. bonus.html. UPDATE 수행을 할 페이지.
<!DOCTYPE html>
<html xmlns:th="https://www.thymeLeaf.org">
<head>
<meta charset="UTF-8">
<title>Insert title here</title>
</head>
<body>
<h2>작업 실패</h2>
<a th:href="@{/}">메인으로 돌아가기</a>
</body>
</html>
예제 4-5. failed.html. 작업 실패 시 이동할 공간
이제 실행해보면 다음의 결과를 얻게 된다.
Expecting a SELECT Query [org.hibernate.query.sqm.tree.select.SqmSelectStatement], but found org.hibernate.query.sqm.tree.update.SqmUpdateStatement [UPDATE SiteUsers s SET s.mileage = s.mileage + ?1 WHERE s.classNumber = ?2]
@Modifying 어노테이션을 적용하지 않으면 스프링에서는 개발자가 작성한 JPQL을 기본적으로 SELECT 문으로 인식하게 된다. 이러한 이유로 위와 같은 에러가 발생한 것이다. 따라서 @Modifying 어노테이션을 반드시 적용해야 한다. 다음은 해당 어노테이션을 적용한 이후의 과정이다.
@Modifying
@Query("UPDATE SiteUsers s SET s.mileage = s.mileage + ?1 WHERE s.classNumber = ?2")
int giveBonusMileage(int bonus, int classNumber);
예제 4-6. @Modifying 어노테이션을 추가하였다.
Executing an update/delete query
org.springframework.dao.InvalidDataAccessApiUsageException: Executing an update/delete query
@Transactional 어노테이션을 적용하지 않았기에 발생하는 문제이다. 이를 추가해준다.
@Modifying
@Transactional // import jakarta.transaction.Transactional;
@Query("UPDATE SiteUsers s SET s.mileage = s.mileage + ?1 WHERE s.classNumber = ?2")
int giveBonusMileage(int bonus, int classNumber);
예제 4-7
그 후 브라우저에서 보너스 마일리지를 지급해주면 다음과 같은 결과를 얻는다.
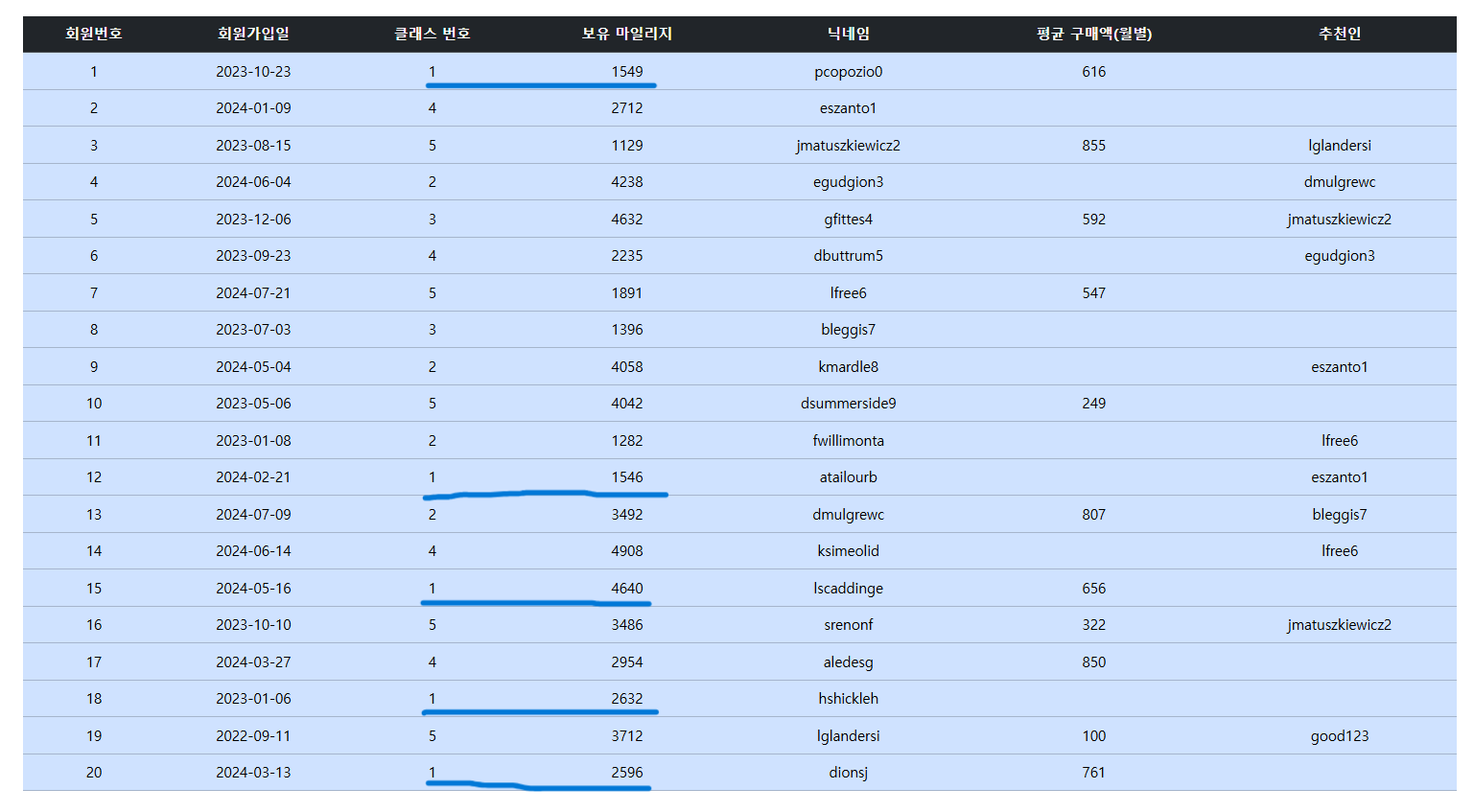
보너스 마일리지 지급 전 1등급 유저들의 현재 마일리지 보유 현황이다.
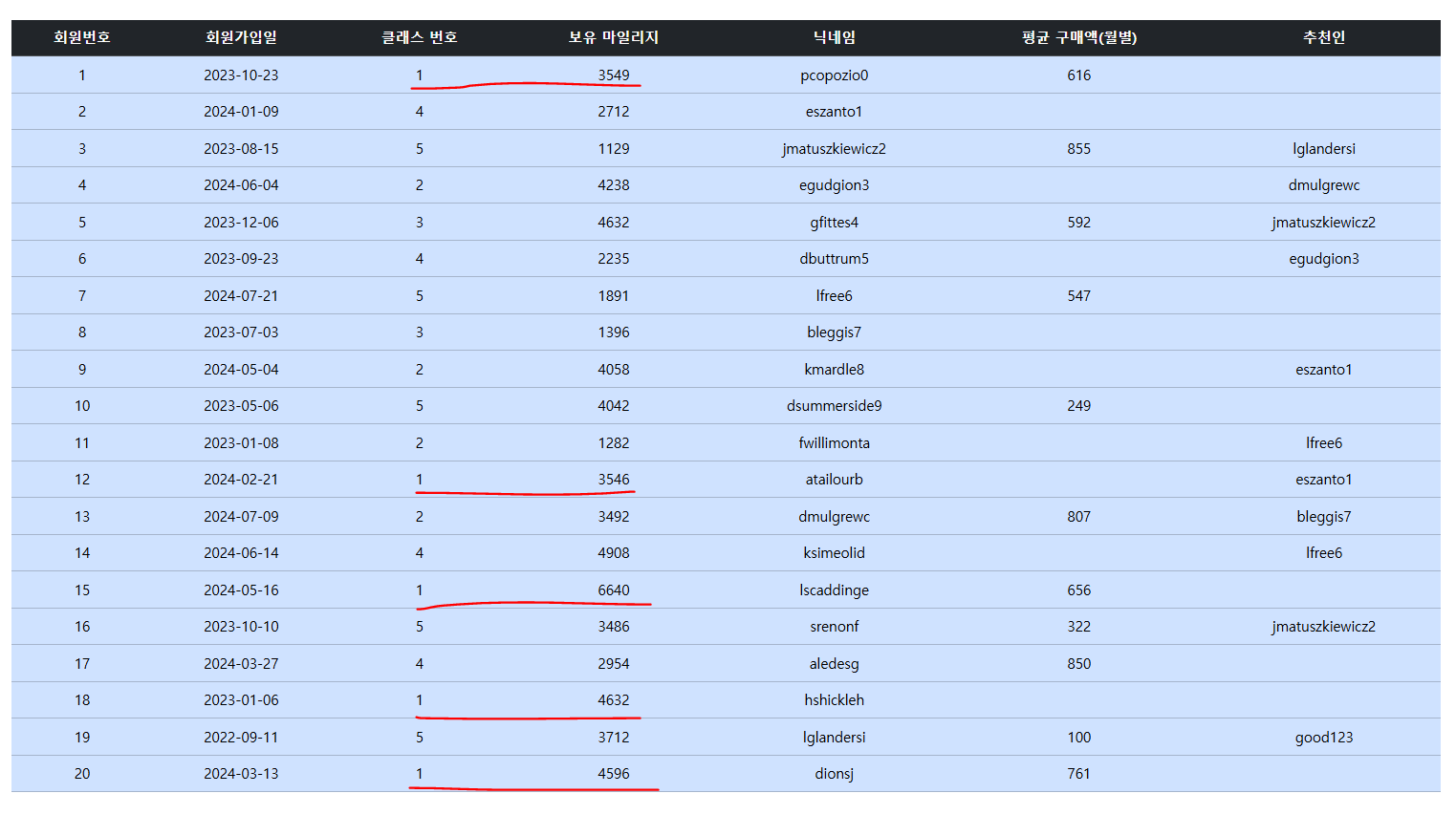
자세히 보면 1등급 유저들의 보유 마일리지가 2000포인트 증가했음을 볼 수 있다. 이렇게 DML을 JPQL로 실행하고자 할 때 @Modifying 어노테이션을 사용하는 것이다.
글을 마치며…
사실 Spring Data JPA에 대해 이 글에서는 아직 다 못 다룬 내용들이 있다.
- Entity와 DTO
- Entity로 둘 이상의 Entity 객체 join하기
- JPA Repository에서 제공하는 페이징 및 정렬 기능
Spring Data JPA에 대해 다루다보니 이 페이지에서는 글이 너무 길어진 관계로, 위 주제들은 각자 별도의 페이지에서 다뤄보도록 하겠다.
Spring Data JPA 및 순수 JPA은 그 자체로 내용이 너무 방대하고 이해하기 어려워 처음에는 “실무에서는 MyBatis보다도 이 기술을 더 많이 쓴다는데, 왜 굳이 배우기 어려운 기술로?”라는 생각이 들었다. 하지만 막상 관련 연습 문제들을 풀어보니 왜 JPA를 사용하는 지를 알 수 있었다. 내가 생각하기에 사람들이 JPA, 그것도 Spring Data JPA를 더 많이 사용하는 이유는 다음과 같이 추측된다.
- 일단 DB를 보지 않고 자바 코드 내에서 DB 작업을 할 수 있다. 물론 기존 DB 내 테이블과 매핑되기 위한 엔티티 객체를 작성할 때에는 어쩔 수 없이 테이블명과 컬럼명이 자바 클래스의 클래스명 및 필드명까지 맞아야 하기에 그 때에는 DB 내용을 볼 수밖에 없다. 하지만 그 후에는 엔티티 클래스들 간의 관계 및 구조만 알면 되기에 더 편리하게 DB 작업을 할 수 있다. 심지어는 아예 자바 코드로 DB 테이블 설계 및 생성이 가능하기에 DBMS 자체를 개발자가 직접 볼 필요가 없게 된다. 괜히 이클립스와 DBMS GUI 프로그램 화면을 들락날락하는 것보다는 더 편하다고 볼 수 있겠다.
- DB 작업을 객체지향적으로 수행할 수 있다. JPA Repository에서 제공하는 쿼리 메서드 또는 JPQL을 통해 DB 작업을 하기에 DB 작업에서까지 일관성 있게 객체지향적으로 프로그래밍할 수 있다.
- JPA Repository에서 제공하는 쿼리 메서드를 통해 쿼리문을 작성하지 않고도 DB 작업을 수행할 수 있기에 압도적인(?) 편리함을 제공한다. 또한 쿼리 메서드로 해결되지 않는 상황에서는 JPQL을 사용하면 되는데, 잘만 사용하면 Native SQL로 작성한 쿼리문보다 더 축약하여 작성할 수 있다.
References
[1] 에이콘아카데미(강남) 강의
[2] 박영권 - “데이터 과학자 + 프로그래머 세상”
[3] 장정우, “스프링 부트 핵심 가이드 - 스프링 부트를 활용한 애플리케이션 개발 실무”, (위키북스, 2024)
[4] JPA
[5] Spring Boot property 파일 설정
[6] GeneratedValue 어노테이션의 strategy 파라미터 값들에 대한 설명.
[JPA] 기본키(PK) 매핑 방법 및 생성 전략 - Heee’s Development Blog
[7] Jpa repository method naming convention
JPA Query Methods :: Spring Data JPA
[8] 벌크 연산
[JPA] 벌크 연산(Bulk Operation)이란?
[9] 벌크 연산
[10] 벌크 연산
Spring Data JPA @Modifying 알아보기
[11] 벌크연산과 modifying 어노테이션
| [Spring Data JPA @Modifying Annotation | Baeldung](https://www.baeldung.com/spring-data-jpa-modifying-annotation) |
[12] @Modifying 어노테이션 공식 API docs
Modifying (Spring Data JPA Parent 3.3.5 API)
This content is licensed under
CC BY-NC 4.0
![]()
![]()
![]()

댓글남기기