[Spring][DB] JPA & Hibernate
JPA 개요
JPA(Java Persistence API)은 자바에서 제공하는 ORM(Object-Relational Mapping) 기술 표준이다. JPA 자체는 ORM 프레임워크를 구현하기 위한 자바 표준 스펙, 즉 인터페이스들의 모임으로 그 자체로는 DB 작업을 할 수 없다. 대신 이 인터페이스들을 구현한 ORM 프레임워크를 사용하면 된다. 이러한 JPA 인터페이스를 구현한 프레임워크 중 하나로 hibernate가 존재한다.
ORM은 객체와 DB의 엔티티(테이블 등)를 매핑하는 프레임워크를 의미한다. JPA가 그 예이다. 그래서 DB 작업을 객체로 다뤄 자바 코드 내에서 작업할 수 있다. 심지어는 자바 코드 내에서 DB 테이블을 생성할 수도 있다.
한 편, MyBatis도 ORM이라는 관점이 있으나, MyBatis는 “객체”를 DB와 매핑하는 것이 아니라 개발자가 작성한 “SQL문”과 매핑하는 방식이기에 MyBatis를 ORM으로 보기 힘들다는 관점도 존재한다. (그래서 MyBatis를 SQL Mapper라 하기도 한다)
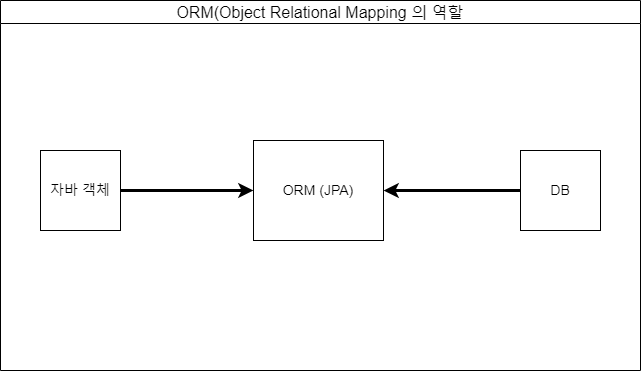
그림 1-1. ORM의 역할. ORM은 자바의 객체와 DB의 엔티티를 서로 매핑시켜주는 역할을 한다.
프로그래밍 언어에서의 객체와 DB의 엔티티는 분명 차이가 있기에 있는 그대로 서로를 매핑할 수는 없다. 따라서 이러한 불일치를 ORM이 대신 해결하여 둘을 연결하는 역할을 한다. JPA는 이러한 ORM을 자바로 구현하기 위한 인터페이스들의 모임으로, ORM이 조금 더 상위 개념이라 보면 되겠다.
JPA의 특징은 다음과 같다.
- 개발자가 SQL문을 작성하지 않아도 이미 관련 메서드가 있기에 해당 메서드를 호출하기만 하면 된다. 이로 인해 기존의 JDBC 방식처럼 개발자가 일일이 코드를 장황하게 작성할 필요가 없다.
- SQL문이 메서드에 내장되어 있는 형태이기에 개발자가 SQL문을 실수로 작성할 일도 방지할 수 있다.
- 참고로, JPA 이용 시 개발자가 SQL문을 작성할 필요가 없는 이유는 개발자가 직접 JDBC를 사용하는 방식이 아니라 JPA가 대신 JDBC에 직접 접근하여 DB 작업을 하는 방식이기 때문이다.
- 객체와 DB의 Entity를 매핑하는 형식이기에 RDBMS 종류에 상관없이 사용할 수 있다. 이로 인해 RDBMS의 종류가 바뀌어도 자바 코드는 그대로 유지되기에 유지보수성이 높다고 볼 수 있다.
- 이러한 이점에도 불구하고, 문법이 어려워 초보자들에게 학습 장벽이 높다는 단점이 존재한다. 단, Spring에서는 Spring Data JPA를 제공하여 조금 더 쉽게 사용할 수 있다고 한다. Spring Data JPA은 나중에 다른 페이지에서 살펴보겠다.
- 복잡한 쿼리문이 필요할 때에는 ORM만으로는 이를 해결할 수 없다. 이 경우 JPQL(Java Persistence Query Language)을 이용하면 된다고 한다. 만약 JPQL로도 복잡한 쿼리문을 작성할 수 있다면 그 때에는 일반적인(native) SQL을 사용해야 한다.
.png)
그림 1-2. JPA를 이용한 DB 작업 처리 흐름.
영속성 컨텍스트 (Persistence Context)
영속성 컨텍스트는 엔티티 객체를 영구적으로 저장하는 환경을 의미한다. 여기서의 “영구적 저장”이라는 것은 사용자로부터의 DB 작업 요청 결과를 DB에 직접 반영하여 영속성을 부여한다는 의미가 아니다. 영속성 컨텍스트는 애플리케이션의 실행이 끝나기 전까지는 DB 작업 결과가 메모리 상에 유지되도록 하는 역할이라 보면 되겠다. 애플리케이션의 실행 종료 전까지 데이터를 유지한다는 측면에서의 “영구적 저장”인 것이다. 이 때 영속성 컨텍스트에 들어온 엔티티 객체를 영속 객체(Persistence Object)라 한다. 영속성 컨텍스트 내부는 JPA가 관리하며 이러한 영속 객체들의 생명 주기를 관리한다. JPA는 영속성 컨텍스트 내부에 있는 엔티티 객체의 DB와의 매핑 정보를 통해 DB 작업 결과를 DB에 반영하는 역할을 한다. 즉, 자바에서 엔티티 객체를 통해 DB 작업을 한다고 해서 바로 DB에 반영되는 것이 아니라, 해당 엔티티 객체가 영속성 컨텍스트에 먼저 들어간 다음 그 곳에서 JPA에 의해 DB에 영구적으로 반영되는 방식인 것이다. 즉, JPA를 사용하면 개발자가 직접 DB 작업 결과물을 DB에 반영하는 방식이 아닌, JPA가 대신 반영하는 것이다.
클라이언트가 DB 서버에 접속할 때에도 사용자 단위의 session이 형성된다. 영속성 컨텍스트의 생명 주기는 이러한 세션 단위로 주어진다. 사용자가 DB에 접속하는 순간 session이 생성되는데, 이 때 영속성 컨텍스트도 같이 생성된다. 반대로 사용자가 DB 접속을 끊으면 영속성 컨텍스트도 같이 사라진다. 이를 통해서도 다시 한 번 알 수 있는 것은, 영속성(persistence)이란 이름이 붙은 영속성 컨텍스트라고 해서 데이터도 DB에 영속적으로 반영된다는 것은 아니라는 것이다. 이 영속성 컨텍스트도 메모리(RAM 등 휘발성 기억 장치) 상에 존재하기 때문이다.
엔티티 객체를 영속성 컨텍스트에 저장 또는 분리, 삭제, 관리하는 역할을 하는 것이 엔티티 매니저(entity manager)이다. 엔티티 매니저는 이러한 영속성 컨텍스트를 바탕으로 하여 직접 DB에 접근하여 CRUD 작업을 수행한다.
영속성 컨텍스트 내부는 크게 “1차 캐시 저장소”와 “SQL 저장소”가 있다.
- 1차 캐시 저장소 : Entity 객체의 정보를 저장한다. 여기에 존재하는 Entity 객체는 영속(managed) 상태에 놓인다. (영속 상태에 대해서는 후술) 조금 더 자세히 말하자면, 이 영역에는 엔티티 객체 참조 및 이전 영속 상태의 엔티티 복사본(snapshot) 객체를 가지고 있다. (엔티티 객체 자체가 아니라 참조가 존재하는 것이다)
- SQL 저장소 : 애플리케이션이 실행되면서 DB 접근을 위해 사용되는 쿼리문들을 보관하는 장소이다.
이러한 저장소들의 존재로 인해, DB 작업이 실행될 때마다 관련 엔티티 객체와 쿼리문을 해당 저장소에 저장한 후, 이 후에 똑같은 DB 작업 요청이 들어올 때 DB에 또 접근하는 것이 아니라 영속성 컨텍스트 내에서 그 결과값을 반환하면 되는 구조이다. 이 덕분에 DB 서버에 부담을 덜 주게 되고, 이전에 저장되어있던 쿼리문 결과들이 해당 저장소에 저장되어 있기 때문에 DB 작업 속도도 더 올라간다.
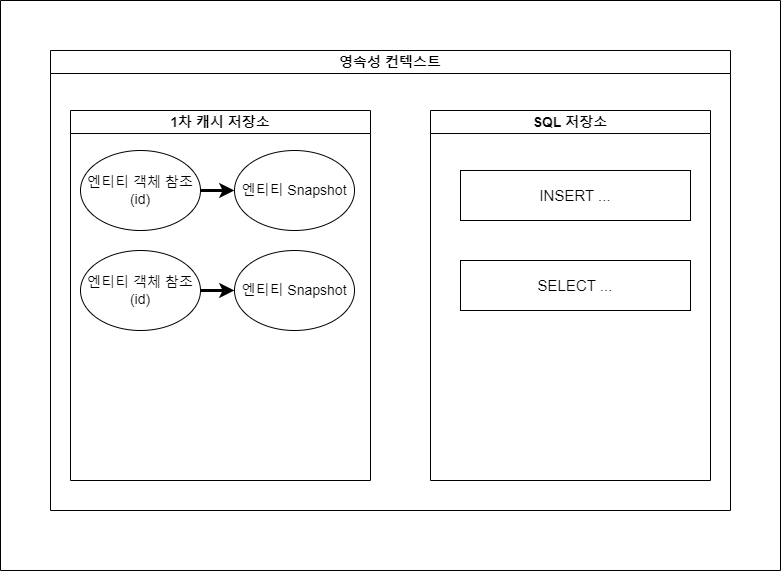
그림 2-1. 영속성 컨텍스트의 구조.
영속성 컨텍스트 내부에서의 엔티티 객체의 생명주기
한 편, 영속성 컨텍스트 내부에 존재하는 엔티티 객체의 생명주기는 다음과 같이 4가지 상태로 구분된다.
- 비영속(New)
-
메모리 상에서는 엔티티 객체가 생성되었으나, 이 엔티티 객체가 아직 영속성 컨텍스트에 추가되지 않은 상황.
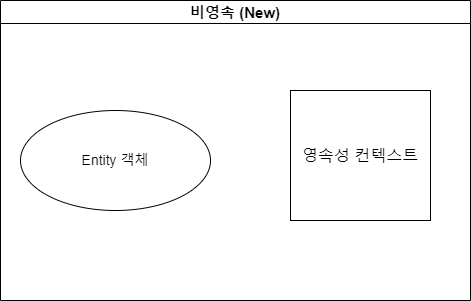
그림 2-2. 비영속(New)
-
- 영속(Managed)
- 엔티티가 영속성 컨텍스트에 추가되어 관리되는 상태. (아직 DB에 결과가 반영되지 않은 상태)
-
persist() 메서드 호출 시 해당 상태로 전환됨. 이 때 SQL 저장소에는 INSERT 쿼리문이 저장된다.
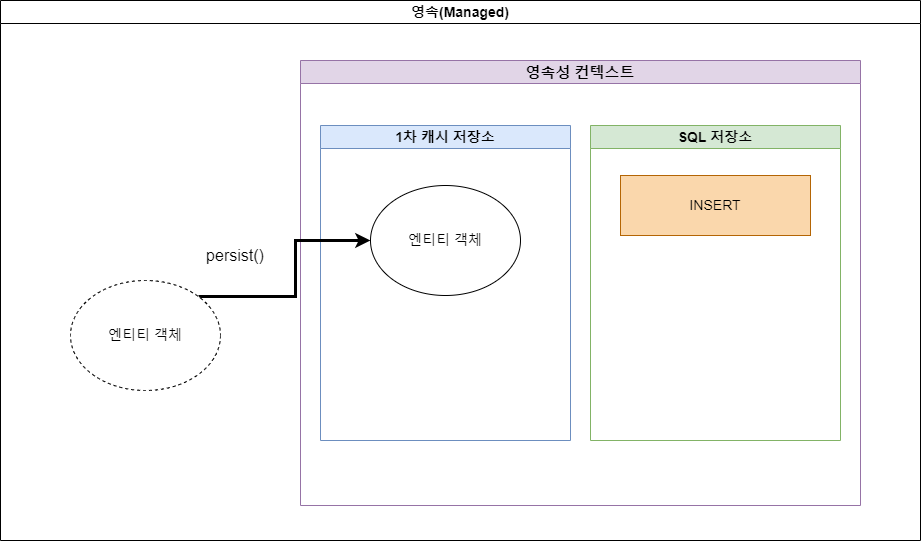
그림 2-3. 영속 (Managed)
- 준영속(Detached)
- 영속성 컨텍스트에서 관리되던 엔티티 객체가 영속성 컨텍스트와 분리된 상태.
-
detach(), clear(), close() 메서드 호출 시 해당 상태로 전환됨.
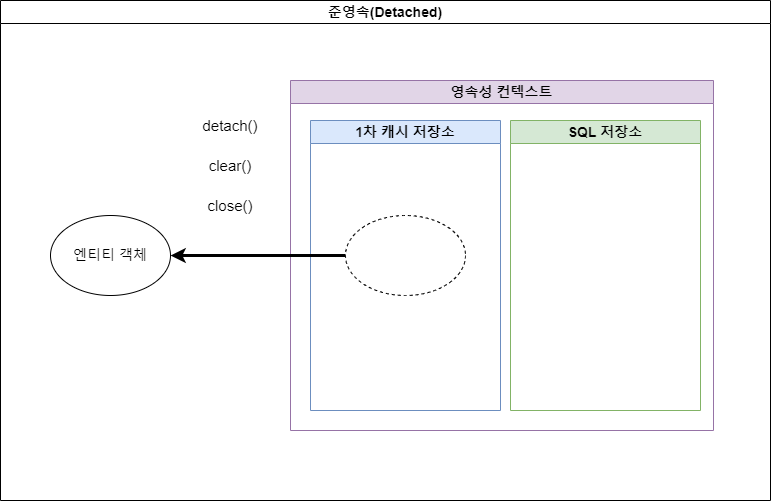
그림 2-4. 준영속 (Detached)
- detach() : 영속성 컨텍스트 내 특정 entity 객체만을 준영속 상태로 전환시킨다.
- clear() : 영속성 컨텍스트 내 모든 entity 객체들을 준영속 상태로 전환시킨다.
- close() : EntityManager를 닫는 메서드로, EntityManager를 닫으면 영속성 컨텍스트도 메모리 상태에서 사라진다. 영속성 컨테이너 자체가 사라지므로 기존에 영속성 컨텍스트 내부에 있던 Entity 객체들은 자연스레 준영속 상태가 된다.
- 삭제 (Removed)
- DB의 레코드 삭제 요청(DELETE)을 받아 특정 엔티티 객체를 영속성 컨텍스트에서 제외한다.
- 이 과정에서 Delete Query문이 SQL 저장소에 저장된다.
-
remove() 메서드 호출 시 해당 상태로 전환됨.
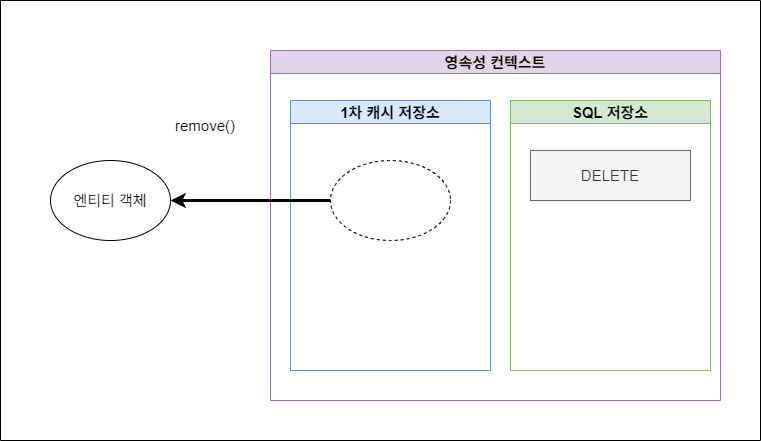
그림 2-5. 삭제 (Removed)
DB와의 직접적 소통
영속성 컨텍스트 내 SQL 저장소 내에 저장되어 있는 모든 SQL문들은 EntityManager의 flush() 메서드가 호출될 때 DB에 쿼리 결과가 영구적으로 반영된다. 단 해당 메서드를 호출하더라도 entity 객체는 영속성 컨텍스트에 그대로 저장되어 있다. 이는 영속성 컨텍스트와 DB를 동기화하여 쿼리문을 DB에 영속화(영구적으로 저장)시키는 방식이기 때문이다.
EntityManager의 find() 메서드는 쿼리문의 SELECT와 같아 DB 내에서 데이터들을 조회해온다. DB로부터 조회해온 데이터들을 토대로 Entity 객체를 생성하여 영속성 컨텍스트에 저장한다. 이 때, 똑같은 Entity 객체 조회 시 다시 DB에 직접 접근하여 데이터를 조회해오는 것이 아니라, 1차 캐시 저장소에 존재하는 해당 Entity를 반환하는 방식이기에 역시 DB 서버에 부담도 주지 않고 성능적으로도 더 뛰어나다.
즉 DB와 직접적으로 소통할 수 있는 메서드는 EntityManager 객체의 find()와 flush() 메서드 이 두 개이다.
방금 언급한 것과 더불어 JPA 사용 시 DB에 쿼리문을 반영하거나 반대로 DB로부터 데이터를 가져오는 등 DB와 직접적으로 소통하는 방법에는 다음이 존재한다.
- 개발자가 직접 flush() 메서드를 호출하여 반영.
- transaction 후 commit 될 때.
- JPQL 쿼리문이 실행될 떄.
엔티티 매니저 (Entity Manager)
엔티티 매니저는 말 그대로 엔티티 객체를 관리하는 객체이다. 엔티티 매니저 객체에는 CRUD 작업을 위한 메서드들을 제공하는데, SELECT 역할의 find(), INSERT 역할의 persist() 등이 그 예이다. 이러한 메서드들을 이용하여 엔티티 매니저 객체를 통해 CRUD 작업을 하면 그에 해당하는 엔티티 객체가 영속성 컨텍스트에 저장되는 방식이다. 이러한 영속성 컨텍스트에서 엔티티 매니저가 엔티티 객체를 관리하는 방식이다. 횟집에 비유를 들면, 영속성 컨테이너가 커다란 수족관이고, 그 안에 든 생선들이 엔티티 객체라면, 횟집 사장 또는 직원이라는 엔티티 매니저가 이 생선들을 관리하는 것이라고 보면 되겠다.
이러한 엔티티 매니저는 CRUD 작업으로 인해 생성되는 엔티티 객체를 저장, 관리하는 역할 뿐만 아니라 실질적인 DB 작업도 수행한다. 앞서 실제 DB에 쿼리문이 반영되는 경우에는 flush() 라는 메서드 호출 시 진행된다고 하였는데, 이 메서드도 EntityManager가 보유하고 있는 메서드이다.
이러한 엔티티 매니저는 EntityManagerFactory로부터 생성되며, EntityManagerFactory는 여러 개의 엔티티 매니저 객체들을 생성할 수 있다. DB에서의 transaction이 발생할 때마다 스레드 별로 엔티티 매니저가 생성된다.
Spring 환경에서는 여러 엔티티 매니저가 같은 transaction 범위에 있을 경우 하나의 동일한 영속성 컨텍스트에 접근하여 사용한다. 이로 인해 엔티티 매니저와 영속성 컨텍스 간의 일대다 관계가 성립될 수 있다. 반면 일반적인 Java application과 같은 j2se(java standard edition) 환경에서는 무조건 1대1 관계라고 한다.
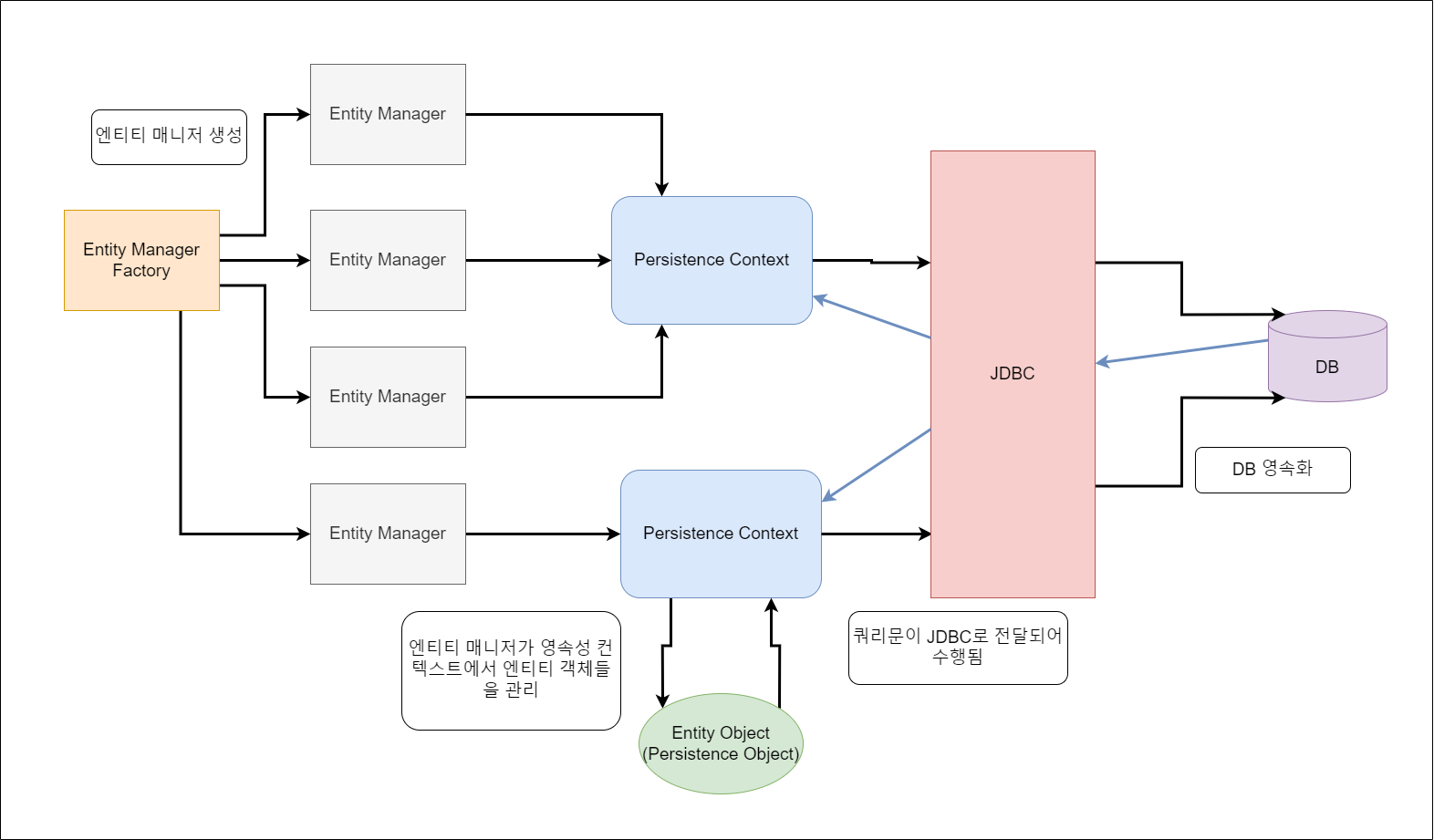
그림 3-1. 엔티티 매니저 팩토리 - 엔티티 매니저 - 영속성 컨텍스트 - DB 간 관계와 흐름을 정리한 그림.
그 외 JPA 관련 개념
- Dirty Checking (변경 감지) - 엔티티 객체의 수정 사항을 영속성 컨텍스트가 자동으로 감지하는 것을 의미한다. 영속성 컨텍스트 내부의 엔티티 객체들에 대해서만 해당되므로 준영속 상태의 엔티티 객체는 dirty checking의 대상에서 제외된다. flush 또는 commit을 통해 쿼리문을 DB에 전송하려고 할 때, 엔티티 매니저는 먼저 1차 캐시 저장소에 있던 복사본(snapshot)과 실제 엔티티 객체를 대조한다. 이를 통해 두 엔티티 객체 간의 정보가 다르다면 이를 “변경”으로 감지하는 것이다. 이 경우 UPDATE 쿼리문을 생성하여 SQL 저장소에 저장한 다음, 이를 DB에 반영하는 방식이다. 이러한 이유로 UPDATE 쿼리문에 해당하는 메서드가 존재하지 않는다. 실제 코드에서는 굳이 persist() 메서드를 호출하지 않아도 자동으로 변경된 사항을 감지하여 이를 UPDATE로 처리해준다.
Spring Data JPA
hibernate와 같은 기존의 JPA의 경우 사용 방법이 어렵다는 단점이 있다. 하지만 기존 hibernate를 사용하기 편리하게 만든 Spring Data JPA가 있다. 기존의 hibernate를 직접 사용하려면 개발자가 엔티티 매니저를 다뤄야하는 번거로움이 있으나 Spring Data JPA에서는 이러한 과정도 해당 프레임워크가 자동으로 처리하기 때문에 개발자 입장에서는 더 편리하게 사용할 수 있다. Spring Data JPA에 대한 자세한 내용과 코드에 대한 내용은 먼저 Spring Boot에 대해 정리한 후에 자세히 다뤄보겠다.
JPA(hibernate) 살펴보기
JPA(hibernate)를 코드 상에서 접해보기 위해 코드 상에서 간단히 살펴보겠다. 실무에서는 JPA를 더 쉽게 사용할 수 있는 Spring Data JPA를 사용한다고 한다. 따라서 여기서는 간단하게만 살펴보겠다. 아래에 소개할 코드들의 자바 클래스 구조는 다음의 그림에서 설명되고 있다.
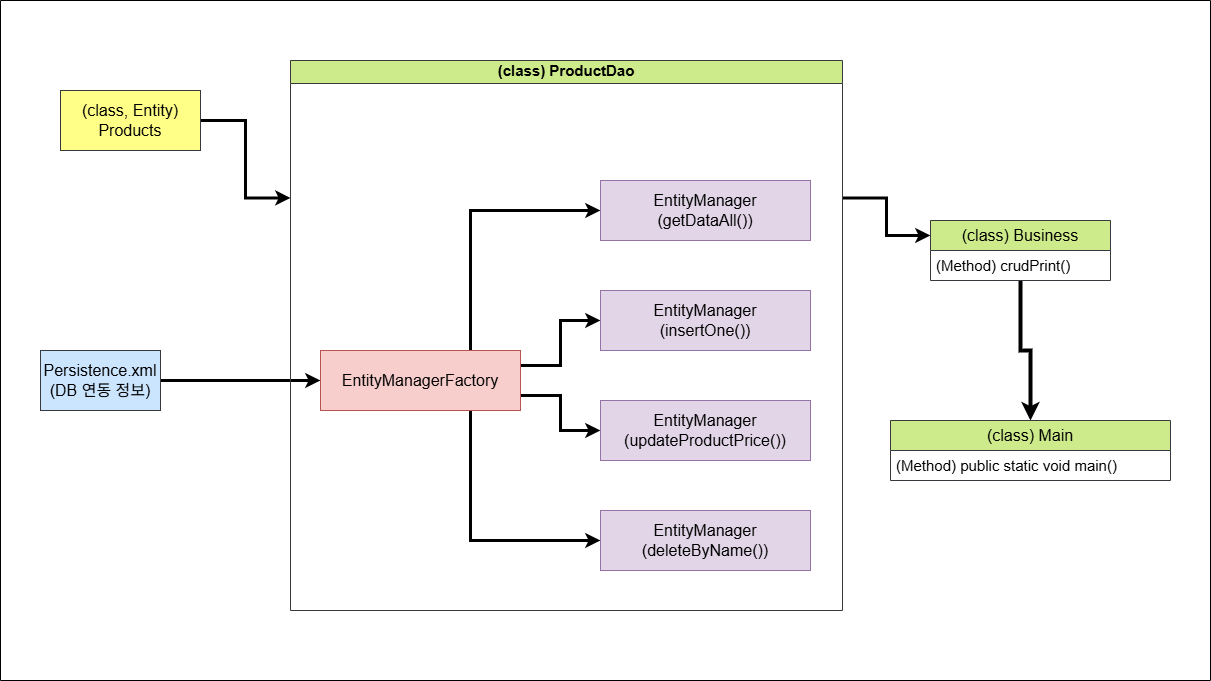
Maven을 이용하여 자바 애플리케이션을 통해 살펴볼 것이다(Spring Boot는 사용하지 않았다). 이를 위해선 몇 가지 준비할 것들이 있다. 먼저 첫 번쨰로 pom.xml 내용을 다음과 같이 새 의존성을 추가해준다.
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.jerocaller</groupId>
<artifactId>BasicJpaStudy</artifactId>
<version>0.0.1-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>6.1.10</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
<version>6.1.10</version>
</dependency>
<!-- MariaDb driver -->
<dependency>
<groupId>org.mariadb.jdbc</groupId>
<artifactId>mariadb-java-client</artifactId>
<version>3.4.1</version>
</dependency>
<!-- lombok 추가 -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.34</version>
</dependency>
<!-- JPA (hibernate) -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
<version>5.3.36.Final</version>
</dependency>
</dependencies>
</project>
pom.xml
DB에 이미 존재하는 한 개의 테이블이 객체로 매핑될 엔티티 클래스는 다음과 같다.
package jero.model.entity;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.Table;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Getter;
import lombok.NoArgsConstructor;
@Entity
@Table(name = "products")
@Getter
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class Products {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private int id;
private String name;
private int price;
private String category;
}
Products.java
실제 테이블명은 products이고, 이를 @Table 어노테이션으로 명시하고 있다. 물론 위 경우에는 대문자를 빼면 테이블명과 클래스명이 같기에 해당 어노테이션을 생략해도 된다. 단, DB 내 테이블명과 엔티티 클래스명이 다르면 반드시 해당 어노테이션을 사용하여 실제 DB 내 테이블명을 명시해줘야 한다.
실제 테이블에서 id라는 컬럼에 PK가 걸려있으므로, PK를 뜻하는 @Id 어노테이션을 해당 필드명에 걸었다. 또한 실제 테이블 내 id 컬럼에는 AUTO_INCREMENT가 적용되어 있어 이를 알려주기 위해 @GeneratedValue 라는 어노테이션을 적용하였다. 원래는 GenerationTyp.AUTO 를 사용해도 되지만 MariaDB, MySQL 한정으로는 해당 값 사용 시 안정성이 떨어진다고 한다. 따라서 이 경우에는 IDENTITY를 대신 사용한다.
사실 엔티티 필드에도 @Column(name = "...") 어노테이션을 걸어 실제 테이블의 컬럼명과 매핑할 수 있으나 만약 엔티티 필드명 자체를 실제 테이블의 컬렴명과 동일하게 작성한 경우에는 해당 어노테이션을 생략할 수 있다.
해당 엔티티 클래스에는 롬복 라이브러리를 이용하여 getter와 builder를 적용하였다. 엔티티 클래스에 setter 메서드를 생성하면 의도치 않게 영속성 컨텍스트에 있는 기존 엔티티 정보를 바꿀 수 있기에 이를 방지하기 위해 setter 어노테이션은 적용하지 않았다. 그 대신 builder 어노테이션을 적용하였는데, 이는 Builder Design Pattern을 이용하여 객체 생성 시 생성자 메서드 대신 사용하여 필드들을 초기화 해주는 메서드라 보면 되겠다. 상황에 따라 모든 필드명을 초기화하여 객체를 생성하지 않고 원하는 필드만 초기화한 채로 객체를 생성할 수 있는데, 이를 가능케 하려면 생성자 메서드를 오버로딩해야 한다. 이는 비슷한 코드들이 중복된다는 문제점이 있는데, builder pattern이 이 문제를 해결해준다. 따라서 객체 생성자 호출 시 builder를 대신 이용하면 좋다. 롬복에서는 클래스에 @Builder 어노테이션을 적용하려면 @NoArgsConstructor 및 @AllArgsConstructor 어노테이션도 적용해야 한다.
다음은 JPA의 핵심이 들어있는 코드이다.
package jero.model;
import java.util.List;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.EntityTransaction;
import javax.persistence.Persistence;
import javax.persistence.TypedQuery;
import org.springframework.stereotype.Repository;
import jero.model.entity.Products;
@Repository
public class ProductDao {
public List<Products> getDataAll() {
EntityManagerFactory factory = Persistence.createEntityManagerFactory("myjpa");
EntityManager manager = factory.createEntityManager();
List<Products> products = null;
try {
// JPQL을 이용하여 테이블 내 모든 상품들 조회.
String jpql = "SELECT p FROM Products p";
TypedQuery<Products> query = manager.createQuery(jpql, Products.class);
products = query.getResultList();
} catch (Exception e) {
System.out.println("=== DB 작업 중 에러 발생! ===");
e.printStackTrace();
} finally {
manager.close();
factory.close();
}
return products;
}
public void insertOne() {
EntityManagerFactory factory = Persistence.createEntityManagerFactory("myjpa");
EntityManager manager = factory.createEntityManager();
EntityTransaction transaction = manager.getTransaction();
try {
transaction.begin();
Products products = Products.builder()
.name("냉동피자")
.price(10000)
.category("food")
.build();
manager.persist(products);
transaction.commit();
} catch (Exception e) {
System.out.println("=== DB 작업 중 에러 발생! ===");
e.printStackTrace();
// 오류 발생 시 이전까지의 작업들을 모두 취소하고 이전 커밋으로 되돌아감.
transaction.rollback();
} finally {
manager.close();
factory.close();
}
}
public void updateProductPrice() {
EntityManagerFactory factory = Persistence.createEntityManagerFactory("myjpa");
EntityManager manager = factory.createEntityManager();
EntityTransaction transaction = manager.getTransaction();
try {
transaction.begin();
Products targetProduct = findByName(manager, "냉동피자");
// 만약 엔티티 객체에 setter가 있었다면
// setter를 통해 값을 바꾸기만 해도
// 수정된 값이 영속성 컨텍스트에 반영된다.
// 왜냐면 해당 엔티티 객체는 이미 영속성 컨텍스트 내부에 포함되어 있는
// 영속 객체이기에 dirty checking이 자동으로 되고 있기 때문.
//targetProduct.setPrice(targetProduct.getPrice() + 1000);
Products updateProduct = Products.builder()
.id(targetProduct.getId())
.name(targetProduct.getName())
.category(targetProduct.getCategory())
.price(targetProduct.getPrice() + 1000)
.build();
// persist()를 수정용으로 사용하려고 하면 에러가 발생한다.
// 대신 merge() 메서드를 사용해야 한다.
manager.persist(updateProduct);
//manager.merge(updateProduct);
transaction.commit();
} catch (Exception e) {
System.out.println("=== DB 작업 중 에러 발생! ===");
e.printStackTrace();
// 오류 발생 시 이전까지의 작업들을 모두 취소하고 이전 커밋으로 되돌아감.
transaction.rollback();
} finally {
manager.close();
factory.close();
}
}
public void deleteByName() {
EntityManagerFactory factory = Persistence.createEntityManagerFactory("myjpa");
EntityManager manager = factory.createEntityManager();
EntityTransaction transaction = manager.getTransaction();
try {
transaction.begin();
Products targetProduct = findByName(manager, "냉동피자");
manager.remove(targetProduct);
transaction.commit();
} catch (Exception e) {
System.out.println("=== DB 작업 중 에러 발생! ===");
e.printStackTrace();
// 오류 발생 시 이전까지의 작업들을 모두 취소하고 이전 커밋으로 되돌아감.
transaction.rollback();
} finally {
manager.close();
factory.close();
}
}
public Products findByName(EntityManager manager, String targetName) {
String sql = "SELECT p FROM Products p WHERE p.name = :targetName";
return manager.createQuery(sql, Products.class)
.setParameter("targetName", targetName)
.getSingleResult();
}
}
ProductDao.java
위 코드에 대한 설명은 먼저 다음의 코드들을 소개한 다음에 하겠다.
다음은 위 Dao 클래스를 이용하여 DB 작업 과정을 콘솔창에 출력하는 클래스이다.
package jero.model;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class Business {
@Autowired
private ProductDao dao;
public void printAllProducts() {
System.out.println("현재 보유 물품 목록");
dao.getDataAll().forEach(product -> {
String oneRecord = String.format("%d %s %d %s",
product.getId(),
product.getName(),
product.getPrice(),
product.getCategory()
);
System.out.println(oneRecord);
});
System.out.println("====================");
}
public void insertOne() {
dao.insertOne();
}
public void deleteOne() {
dao.deleteByName();
}
public void updateOne() {
dao.updateProductPrice();
}
public void crudPrint() {
printAllProducts();
System.out.println("=== DML 작업 전 목록이었음 ===");
insertOne();
printAllProducts();
System.out.println("=== 데이터 한 건 삽입 후의 목록이었음 ===");
updateOne();
printAllProducts();
System.out.println("=== 데이터 한 건 수정 후의 목록이었음 ===");
deleteOne();
printAllProducts();
System.out.println("=== 데이터 한 건 삭제 후의 목록이었음 ===");
}
}
Business.java
위 클래스의 crudPrint()에서는 차례대로 DB 내 데이터 조회 → 삽입 → 수정 → 삭제 순으로 진행되도록 하였다.
다음은 main 메서드가 포함되어 있는 클래스의 코드이다.
package jero;
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
import jero.model.Business;
@Configuration
@ComponentScan(basePackages = {"jero", "jero.model", "jero.model.entity"})
public class Main {
public static void main(String[] args) {
AnnotationConfigApplicationContext context
= new AnnotationConfigApplicationContext(Main.class);
Business business = context.getBean("business", Business.class);
business.crudPrint();
}
}
Main.java
먼저 맨 처음 DB 조회에 사용된 ProductDao 클래스 내 메서드와 그 출력 결과물을 보겠다.
1 얼큰한 라면 1봉 3000 food
2 도시락 3종 세트 12000 food
3 순대국 5000 food
4 롤케잌 10000 food
5 맨투맨 15000 cloth
6 바지 13000 cloth
7 신발 60000 cloth
8 모자 8000 cloth
9 식사용 접시 3000 sundries
10 공구세트 20000 sundries
11 메모장 5000 sundries
12 책받침 6000 sundries
====================
=== DML 작업 전 목록이었음 ===
콘솔창 결과
public List<Products> getDataAll() {
EntityManagerFactory factory = Persistence.createEntityManagerFactory("myjpa");
EntityManager manager = factory.createEntityManager();
List<Products> products = null;
try {
// JPQL을 이용하여 테이블 내 모든 상품들 조회.
String jpql = "SELECT p FROM Products p";
TypedQuery<Products> query = manager.createQuery(jpql, Products.class);
products = query.getResultList();
} catch (Exception e) {
System.out.println("=== DB 작업 중 에러 발생! ===");
e.printStackTrace();
} finally {
manager.close();
factory.close();
}
return products;
}
ProductDao.getDataAll()
위 코드를 보면 다음의 순으로 흘러가고 있다.
- 엔티티 매니저 팩토리를 생성한다. 이 때 persistence.xml 파일 내
<persistence-unit>태그의 name 속성에 지정된 값을 그대로 입력하면 된다. 그러면 자바 클래스 내에서 persistence.xml에 저장되어 있는 여러 DB 정보들을 인식하여 DB와 연동할 수 있는 것이다. - 엔티티 매니저 팩토리로부터 엔티티 매니저를 생성한다. 이 엔티티 매니저 객체를 통해 데이터 조회 및 삽입, 수정, 삭제를 할 수 있다.
-
원하는 쿼리문을 수행해주는 메서드가 엔티티 매니저 객체 내에 없을 경우 JPQL을 이용하여 수행할 수 있다. JPQL은 일반적인 SQL (Native SQL이라 한다) 과 형태는 거의 비슷하나, JPQL에서는 엔티티 클래스와 그 필드를 명시하여 쿼리문을 작성해야한다는 것이 차이점이다. 위 코드에서는
SELECT p FROM Products p라 되어 있는데, 이는 다음과 같은 자바 코드로 해석할 수 있겠다.// pseudo code Products p = new Products(); // FROM Products p return p; // SELECT p ) 조회된 엔티티 객체를 반환. - 만약 try 블록 내부에 있는 코드가 정상적으로 수행되면 읽어온 데이터를 리스트 컬렉션으로 반환한다.
다음은 데이터 한 건 삽입 작업을 수행하는 메서드와 그 결과물이다.
1 얼큰한 라면 1봉 3000 food
2 도시락 3종 세트 12000 food
3 순대국 5000 food
4 롤케잌 10000 food
5 맨투맨 15000 cloth
6 바지 13000 cloth
7 신발 60000 cloth
8 모자 8000 cloth
9 식사용 접시 3000 sundries
10 공구세트 20000 sundries
11 메모장 5000 sundries
12 책받침 6000 sundries
20 냉동피자 10000 food => 새 데이터 추가됨
====================
=== 데이터 한 건 삽입 후의 목록이었음 ===
콘솔창 출력 결과
public void insertOne() {
EntityManagerFactory factory = Persistence.createEntityManagerFactory("myjpa");
EntityManager manager = factory.createEntityManager();
EntityTransaction transaction = manager.getTransaction();
try {
transaction.begin();
// new Products("냉동피자", 10000, "food");
Products products = Products.builder()
.name("냉동피자")
.price(10000)
.category("food")
.build();
manager.persist(products);
transaction.commit();
} catch (Exception e) {
System.out.println("=== DB 작업 중 에러 발생! ===");
e.printStackTrace();
// 오류 발생 시 이전까지의 작업들을 모두 취소하고 이전 커밋으로 되돌아감.
transaction.rollback();
} finally {
manager.close();
factory.close();
}
}
Products.insertOne
위 메서드 내에서는 EntityTransaction이라는 객체가 새로 등장하였는데, 이는 DB의 transaction과 동일하다. 즉, 여러 DB 작업들이 모두 성공적으로 진행된 후에야 이를 commit하여 DB에 영구적으로 반영하기 위한 작업 단위를 나타내는 객체이다. transaction의 시작을 begin() 메서드를 호출하여 설정하고 transaction 작업 코드를 그 아래에 작성하면 된다. 그 후 모든 쿼리문 수행 작업이 성공하면 commit() 메서드를 호출하여 영구히 반영하는 것이다. 만약 중간에 에러가 난 경우 지금까지의 작업들이 DB에 반영되지 않고 이전 커밋으로 돌아가게끔 rollback() 메서드를 호출하도록 하였다. DQL과 같이 단순한 데이터 조회 작업은 DB 내용을 바꾸지 않으므로 굳이 transaction을 사용하지 않아도 되나, DML과 같이 DB 내 데이터를 조작하는 쿼리문 사용 시에는 transaction을 사용하는 것이 안전하다.
한 편, 새로운 Products 엔티티를 builder를 이용하여 생성하고 있다. 새 데이터들이 초기화된 엔티티 객체가 생성된 후, EntityManager 객체의 persist() 메서드에 이를 인자로 넘겨 호출함으로써 영속성 컨텍스트에 데이터 삽입 쿼리문과 동시에 해당 엔티티 객체가 등록된다.
다음은 수정 코드와 그 결과물이다.
=== DB 작업 중 에러 발생! ===
javax.persistence.PersistenceException: org.hibernate.PersistentObjectException: detached entity passed to persist: jero.model.entity.Products
콘솔창 출력 결과
public void updateProductPrice() {
EntityManagerFactory factory = Persistence.createEntityManagerFactory("myjpa");
EntityManager manager = factory.createEntityManager();
EntityTransaction transaction = manager.getTransaction();
try {
transaction.begin();
Products targetProduct = findByName(manager, "냉동피자");
// 만약 엔티티 객체에 setter가 있었다면
// setter를 통해 값을 바꾸기만 해도
// 수정된 값이 영속성 컨텍스트에 반영된다.
// 왜냐면 해당 엔티티 객체는 이미 영속성 컨텍스트 내부에 포함되어 있는
// 영속 객체이기에 dirty checking이 자동으로 되고 있기 때문.
//targetProduct.setPrice(targetProduct.getPrice() + 1000);
Products updateProduct = Products.builder()
.id(targetProduct.getId())
.name(targetProduct.getName())
.category(targetProduct.getCategory())
.price(targetProduct.getPrice() + 1000)
.build();
// persist()를 수정용으로 사용하려고 하면 에러가 발생한다.
// 대신 merge() 메서드를 사용해야 한다.
manager.persist(updateProduct);
//manager.merge(updateProduct);
transaction.commit();
} catch (Exception e) {
System.out.println("=== DB 작업 중 에러 발생! ===");
e.printStackTrace();
// 오류 발생 시 이전까지의 작업들을 모두 취소하고 이전 커밋으로 되돌아감.
transaction.rollback();
} finally {
manager.close();
factory.close();
}
}
Products.updateProductPrice
위 메서드를 실행하면 에러가 발생하면서 update 작업이 실행되지 않는다. 왜 그럴까? 우선 위 코드에서는 먼저 수정하고자 하는 엔티티 객체(targetProduct)를 findByName() (필자가 직접 만든 메서드) 를 호출하여 찾았다. 그 후, 새로운 엔티티 객체를 builder를 이용하여 생성하면서 필드값들을 앞서 찾은 엔티티 객체 내 정보 그대로 초기화하고 있다. 여기서 바꾸고자 하는 정보가 price 단 하나 뿐이므로 그렇게 한 것이다. 그 후, 새로운 엔티티 객체를 persist() 하고 있다.
새로 생성된 엔티티 객체가 영속성 컨텍스트에 포함되기 위해 persist() 메서드를 호출하였는데, 해당 메서드는 INSERT문을 실행한다. 그런데 PK가 걸린 컬럼값이 같은 데이터가 DB 내에 이미 있기에 그에 해당하는 기존 엔티티 객체와 그 정보가 충돌하기에 에러가 발생한 것이다.
그렇다고 아무런 메서드를 호출하지 않으면 updateProduct 엔티티 객체는 현재 준영속 객체이기에 dirty checking의 대상에서 제외되어 자동으로 변경 내용이 영속성 컨텍스트에 반영되지도 않는다. 따라서 이 경우엔 merge() 메서드를 사용해야 한다. 해당 메서드의 인자로 전달된 엔티티 객체에 대해, 영속성 컨텍스트 내 똑같은 ID 필드값을 가지는 엔티티가 존재할 경우 두 엔티티 객체를 합병한다 (git의 merge와 비슷하다고 보면 되겠다). 이를 통해 준영속 객체 내 정보로 덮어씌워진다.
위 코드의 경우, findByName() 메서드를 통해 같은 PK 필드값을 가진 데이터를 DB로부터 가져와 이 정보를 담은 엔티티 객체 targetProduct가 영속성 컨텍스트에 존재하게 된다. 이후에 새 엔티티 객체 updateProduct를 생성하여 merge() 메서드를 호출하고 있는데, 이를 통해 updateProduct 엔티티 객체가 targetProduct 객체와 병합되며 이 병합되어 탄생한 새로운 엔티티 객체가 영속성 컨텍스트 내에 존재하게 된다. 여기서 주의할 점은 사실 updateProduct라는 준영속 객체 자체는 영속성 컨텍스트 내부로 들어온 건 아니라는 것이다. 준영속 객체였던 updateProduct 의 필드값들로 덮어씌워지게 된다. 이 과정에서 UPDATE 쿼리문이 SQL 저장소에 저장된다.
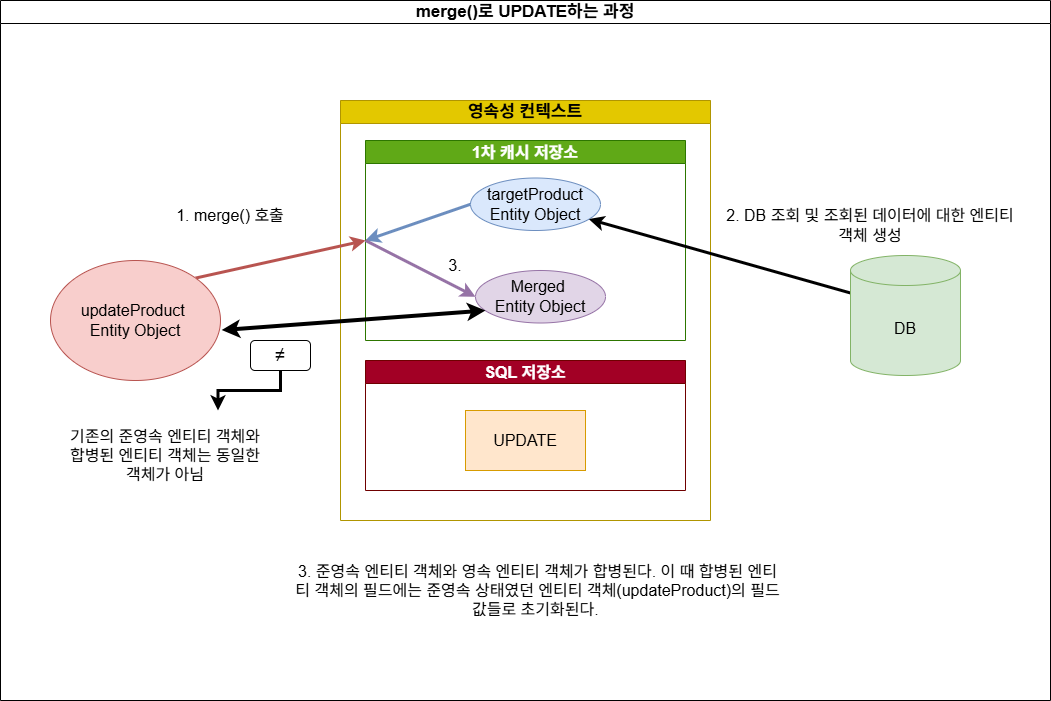
merge()는 영속성 컨텍스트 내에 존재하지 않는 준영속 엔티티 객체를 새로운 엔티티 객체로 합병하여 이를 영속성 컨텍스트 내부로 포함시킬 때 사용하는 메서드이다. (다시 한 번 말하지만, 기존 준영속 엔티티 객체가 영속성 컨텍스트로 들어가는 것이 아니라, 준영속 엔티티 객체로부터 병홥되어 탄생한 새로운 엔티티 객체가 영속성 컨텍스트 내부에 들어가게 되는 것이다)
merge()의 이러한 성질에 의해, 새 엔티티 객체를 생성할 때 특정 필드값들을 초기화하지 않은 상태에서 merge()로 합병하려고 하면 초기화되지 않은 값이 반영되므로 null값이 할당될 수 있다. 이로 인해 update 작업은 사실 영속성 컨텍스트에 존재하는 엔티티 객체를 가져온 후 해당 객체의 setter 메서드를 통해 값을 바꾸는 게 더 좋다. 그러면 다른 메서드를 호출하지 않아도 dirty checking 되고 있기에 자동으로 변경을 감지하여 이를 반영하기 때문이다.
아무튼 앞선 코드에서 merge() 호출문의 주석을 제거하고 persist() 호출문에 주석을 걸어 재실행해보면 데이터가 잘 수정된다.
1 얼큰한 라면 1봉 3000 food
2 도시락 3종 세트 12000 food
3 순대국 5000 food
4 롤케잌 10000 food
5 맨투맨 15000 cloth
6 바지 13000 cloth
7 신발 60000 cloth
8 모자 8000 cloth
9 식사용 접시 3000 sundries
10 공구세트 20000 sundries
11 메모장 5000 sundries
12 책받침 6000 sundries
21 냉동피자 11000 food => 천원이 추가되어 있다!
====================
=== 데이터 한 건 수정 후의 목록이었음 ===
콘솔창 출력 결과
한 편, 이번 예제에서 특정 필드값을 토대로 특정 엔티티 객체 하나를 조회하는 메서드를 다시 보면 다음과 같다.
public Products findByName(EntityManager manager, String targetName) {
String sql = "SELECT p FROM Products p WHERE p.name = :targetName";
return manager.createQuery(sql, Products.class)
.setParameter("targetName", targetName)
.getSingleResult();
}
ProductDao.findByName
JPQL 사용 시 상황에 따라 삽입될 값이 달라질 경우, 위와 같이 JPQL 문 안에서 :parameter 와 같이 콜론(:) 문자를 사용한다. 그 후, setParameter() 메서드를 통해 첫 번쨰 인자로 파라미터 이름을 명시한 후, 두 번째 인자로 실제 그 파라미터 자리에 삽입할 데이터를 넣으면 된다.
Spring과 Maven 환경에서 Java Application에서 JPA를 간단하게 사용해보았다. 해당 코드를 보면 알 수 있듯, 별도의 XML 설정 파일이 필요하며, 개발자가 직접 EntityManagerFactory, EntityManager, EntityTransaction을 조종해야 함을 알 수 있다. 하지만 Spring Boot 환경에서의 Spring Data JPA를 사용하게 되면 이 모든 설정들을 스프링 프레임워크가 자동으로 수행해주며, 관련 문법들도 더 쉽게 사용할 수 있어 개발자가 DB 작업을 더 수월하게 해줄 수 있다. Spring Data JPA에 대한 자세한 사항은 다른 글에서 다뤄보겠다.
바로 이전에 든 예제의 소스 코드는 다음의 깃허브 repo에서 모두 볼 수 있다.
spring-study/BasicJpaStudy at master · JeroCaller/spring-study
References
[1] 에이콘아카데미(강남) 강의
[2] 박영권 - “데이터 과학자 + 프로그래머 세상”
[3] JPA VS MyBatis
JPA vs Mybatis, 현직 개발자는 이럴 때 사용합니다. I 이랜서 블로그
[4] JPA
[5] 장정우, “스프링 부트 핵심 가이드 - 스프링 부트를 활용한 애플리케이션 개발 실무”, (위키북스, 2024)
[6] 영속성 컨텍스트
[Spring JPA] 영속성 컨텍스트(Persistence Context)
[7] DB에서의 Session?
Database session이란? 그리고 MySQL에서의 thread
[8] 영속성 컨텍스트 내 엔티티 객체의 생명주기
[9] JPA에서의 UPDATE 주의사항
This content is licensed under
CC BY-NC 4.0
![]()
![]()
![]()

댓글남기기