[Infra] DB Clustering, fail-over, load-balancing (ft. Quartz)
지난 글 “[Spring Boot] 스케줄링과 Quartz”에서는 자바 및 스프링 진영에서 스케줄링을 위해 자주 사용되는 라이브러리 중 하나인 Quartz에 대해서 다뤘었다. 그리고 다른 스케줄링 도구들과 비교하여 어떤 점이 다른지 조사하던 중, “DB 기반 클러스터링”, “fail-over”, “load balancing”이라는 생소한 용어들을 보았었다. 그래서 이 글에서 해당 용어들을 개념, 이론적인 측면에서 정리해보고자 한다.
Clustering
cluster의 원 뜻은 “무리”, “그룹”의 의미를 담고 있다. 서버에서의 클러스터링은 여러 대의 서버들을 구성하고 이들을 하나로 묶어 연동하는 것을 의미한다.
한가지 유의할 점은, 우리는 보통 특정 회사에서 모두 같은 목적을 위해 모여서 각자 일들을 분배받아 수행하는 사람들의 모임을 “조직”이라고 부르지, 단순히 사람들이 모여 있다는 이유로 지하철, 버스와 같은 대중교통을 “조직”이라 부르진 않는다는 것이다. 마찬가지로 단순히 여러 대의 서버들이 모여있다는 이유로 이들을 클러스터링이라 부르기보다는, 이 여러 대의 서버들이 마차 하나의 시스템처럼 행동하도록 묶은 서버 그룹을 클러스터링이라 부르는 것이 적합하다.
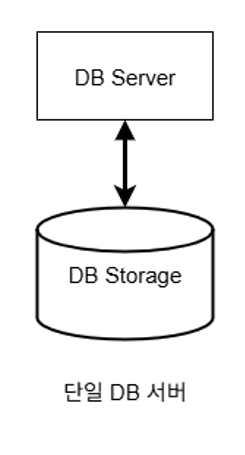
그림 1-1. 가장 간단하고 떠올리기 쉬운 단일 DB 서버 구조
데이터베이스를 예로 들면, 가장 간단한 경우에는 하나의 DB storage(저장소)와 이와 연동된 DB 서버로만 구성할 수 있다. 간단한 애플리케이션 구축이나 간단한 작업을 위해선 이 정도로도 충분하겠지만, 다음의 잠재적인 문제점들도 내포하게 된다.
- 해당 DB 서버가 어떠한 이유로 동작되지 않을 경우 데이터 관련 읽기, 쓰기 등의 작업도 할 수 없게 된다.
- 예를 들어 사용자가 많아져서 데이터 요청이 무수히 많아질 경우 하나의 서버만으로는 이 모든 요청 트래픽들을 감당할 수 없어 사용자 입장에서는 앱이 굉장히 느리다고 느낄 것이다.
이러한 잠재적인 문제점들은 곧 사용자의 불편함으로 이어진다.
DB 서버 link
DB storage는 말 그대로 데이터들을 저장하는 저장소이고, DB 서버는 클라이언트의 요청을 통해 데이터에 대한 CRUD 작업을 하며, DB storage에 있는 데이터들을 관리하는 서버를 의미한다. 흔히 알려진 MySQL, MariaDB, Oracle 등등이 DBMS이자 DB 서버라 보면 되겠다.
이러한 문제점들이 발생할 때를 대비하여 하나의 서버가 아닌 여러 대의 서버들로 구성하여 운영하면 위의 문제점들을 해결할 수 있다고 한다.
서버 클러스터링에는 방금 언급했듯 수많은 데이터 요청들로 인한 부하를 분산하기 위한 DB 기반 클러스터링과 더불어, 클라이언트로부터 오는 HTTP 요청 트래픽이 무수히 많을 경우 이들을 적절히 여러 서버에 분산시키기 위한 웹 서버 클러스터링으로 나뉜다. 이 글은 이 글을 작성하는 계기가 된 Quartz 라이브러리의 “DB 기반 클러스터링”이란 개념으로부터 시작되었기 때문에 여기서는 DB 기반 클러스터링을 기준으로 다루도록 하겠다.
서버 클러스터링의 주요 특징 및 장점은 다음처럼 알려져 있다.
- 고가용성 (High Availability) - 클러스터링은 말 그대로 여러 개의 서버들로 운영하기 때문에 한 쪽 서버가 다운되더라도 다른 쪽 서버에서 계속 서비스할 수 있어 서비스의 연속성을 보장한다. 클라이언트 입장에서는 특정 서버의 고장에 관계없이 계속 서버에 접근, 이용(available)이 가능하기 때문에 “고가용성”이라 이름이 붙여진 것으로 추측된다.
- 확장성 (Scalability) - 필요 시 여러 대의 서버를 더 추가하기만 하면 되기 때문에 확장성에 매우 용이하다고 볼 수 있다.
- 로드 밸런싱 (Load Balancing) - 과도한 요청 트래픽으로 인한 부하를 여러 서버에 분산시키는 기술을 load balancing이라 한다. 서버 클러스터링은 수많은 요청 트래픽으로 인한 부하를 분산시키기 위해 여러 대의 서버들을 구축하는 것인데, 그냥 여러 대의 서버를 구축한다고 해서 자동으로 부하가 분산되지 않기에 로드 밸런싱이라는 별도의 기술을 적용해야 한다고 한다.
한 편, 클러스터링에도 유형이 있다고 한다.
DB 클러스터링의 유형
- Active - Active clustering : 두 대 이상의 DB 서버들로 구성된 클러스터링에서 모든 서버들이 Active 상태, 즉 활동 상태로 운영되는 방식을 의미한다.
- 장점)
- 하나의 서버가 고장나도 다른 서버에서 게속 서비스를 제공할 수 있다.
- 로드 밸런싱을 통해 부하를 여러 서버로 분산시켜 성능 저하를 방지할 수 있다.
- 단점)
- 여러 서버들이 단 하나의 공유 스토리지를 공유하므로, 병목현상이 일어날 수 있다.
- 바로 다음에 소개할 Active - Stand-by 방식에 비하면 모든 서버가 계속 작동하는 상태이므로 서버 운영 비용이 상대적으로 더 많이 들 것이다.
- 장점)
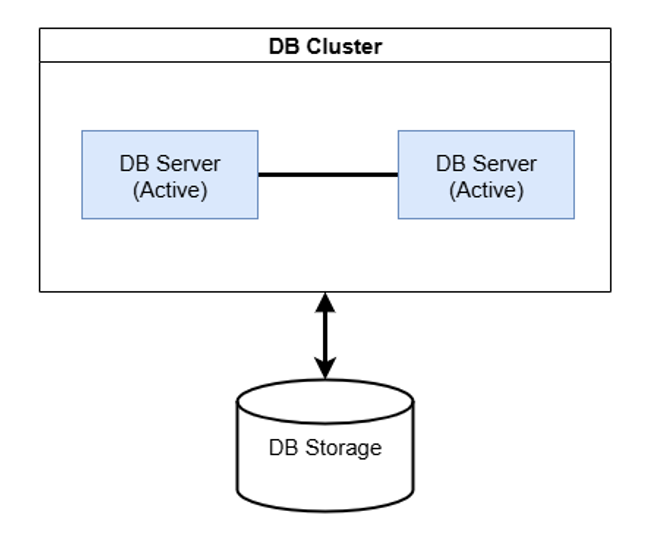
그림 2-1. active - active clustering 예시 그림.
- Active - Stand-by clustering (stand-by 대신 passive란 용어가 대신 사용되기도 한다) : 클러스터링을 구성하는 여러 서버들을 Active 서버와 Stand-by 서버로 나눠 운영하는 방법. 즉 Active 서버는 계속 동작하는 상태이고, Stand-by 서버는 Active 서버에 문제가 생겨 더 이상 서비스를 제공할 수 없을 때 이 Stand-by 서버를 Active 서버로 전환시켜 장애에 대응하는 용도로 사용된다.
- 장점)
- Active - Active 방식에 비해 DB storage에 접근하는 서버의 개수가 상대적으로 적기 때문에 병목현상을 방지할 수 있다.
- Active - Active 방식에 비해 항상 작동 상태인 서버의 수가 적으므로 운영 비용도 그만큼 덜 든다.
- Active - Active 방식과 마찬가지로 어느 한 서버에서 장애 발생 시 다른 서버를 통해 이에 대응할 수 있다.
- 단점)
- Active 서버에서 장애 발생 시 Stand-by 서버로 전환하는 데에 시간이 걸리기 때문에 그 동안 서비스 이용이 불가능하다. 수십초에서 길게는 수십분 걸린다고 한다.
- Active - Active에 비해 작동 상태의 서버의 수가 적으므로 부하 분산에 불리하다.
- 장점)
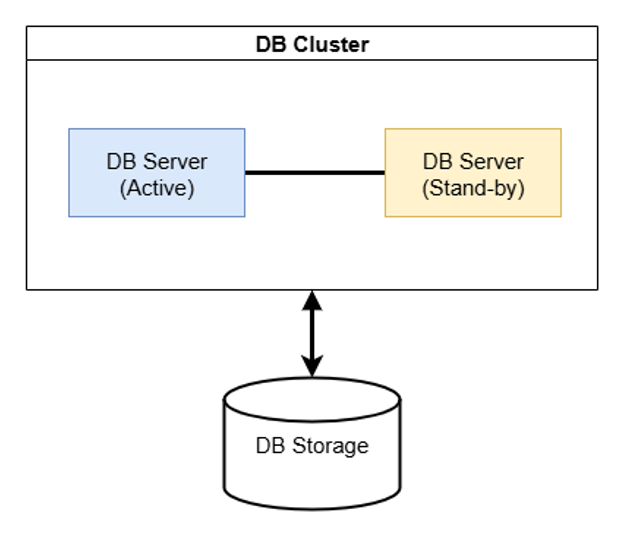
그림 2-2. Active - Stand-by clustering 방식의 예시 그림.
Replication
앞서 살펴본 클러스터링의 경우, DB 서버는 계속 늘릴 수 있어도 이 모든 서버가 단 하나의 storage를 공유한다는 사실은 변치 않는다는 것을 볼 수 있다. 이와 대조적으로, 서버와 스토리지 모두 여러 개로 복제하여 사용하는 기법이 있는데 이를 replication(레플리케이션)이라고 한다.
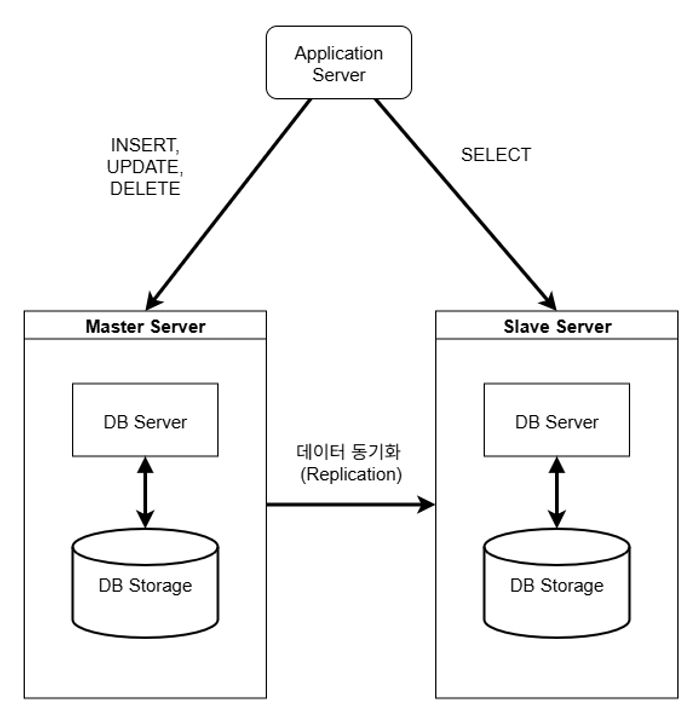
그림 3-1. replication 예시 그림
replication은 위 그림과 같이 서버-스토리지 구조 자체를 복제하여 운영하는 구조이다. 여기에는 위 그림과 같이 주로 메인으로 사용될 master 서버와, 이 서버를 복제한 slave 서버로 나뉜다. 보통 master 서버에서는 데이터의 INSERT, UPDATE, DELETE 등 DML 관련 요청을 처리하는 용도로 사용되고, slave 서버는 SELECT와 같은 데이터 읽기 작업 요청을 처리할 때 사용된다고 한다. 이렇게 작업을 나눠서 데이터 요청 트래픽을 분산시키는 방법인 것이다.
master 서버에서 발생할 DML 관련 작업에는 트랜잭션 수행으로 인한 로그 파일이 생성되는데, 이를 slave의 IO thread에서 복제를 해온 후, SQL thread에서 이 파일들을 한 줄씩 읽으면서 slave 서버 내 storage에 갱신된 데이터들을 가져와 저장하는 방식으로 동기화가 이루어진다고 한다.
한 편, 필요하다면 slave 서버는 여러 대 증축하여 사용할 수도 있다고 한다.
- replication의 장점 및 용도
- scale-out : 급격히 증가하는 트래픽에 대응하기 위해 서버를 늘려 성능을 개선하기 위한 용도로 사용됨.
- 서버 증설로 요청 부하에 따른 성능 저하를 해결하는 scale-out과 달리, 기존 서버의 성능 자체를 확장하는 것을 scale-up 방식이라고 한다.
- 백업 : 혹시나 모를 장애에 대비하여 master 서버에 있는 원본 DB 데이터를 백업할 수 있다. slave 서버를 단순히 백업 용도로만 사용한다면 위 그림 3-1에서 slave에는 아무런 데이터 요청이 들어가지 않고, SELECT를 포함한 모든 요청이 master로 몰리는 구조로 구현할 수 있다고 한다.
- 데이터 분석 : 데이터 분석을 위해서는 DB로부터 읽기(SELECT) 작업을 해야 하는데, 사용자가 서비스를 이용하기 위해 데이터에 대한 DML 작업 요청이 전송되는 master 서버와 분리하여 slave 서버에서만 데이터를 가져와 분석하게 함으로써 서버 부하를 줄일 수 있다.
- scale-out : 급격히 증가하는 트래픽에 대응하기 위해 서버를 늘려 성능을 개선하기 위한 용도로 사용됨.
- replication의 단점
- master와 slave의 데이터베이스 버전을 동일하게 맞춰줘야 하는 버전 관리가 필수.
- master에서 slave로 데이터를 가져올 때 동기 방식으로 가져올 경우 그만큼 시간이 걸려 속도가 느리므로 보통 비동기적으로 데이터를 가져온다고 한다. 이로 인해 master - slave 간의 데이터가 불일치할 수도 있다. 이 외에도 master와 slave 서버 각각의 데이터 처리 속도가 달라도 데이터 일관성이 깨질 수 있다.
- master 서버에서 장애 발생 시 이를 대처하기가 어렵다고 한다. master 서버 다운 시 어떤 slave를 master로 변경할 것인지에 대한 대비를 해야한다는 점, master - slave 간의 데이터 동기화에도 악영향을 끼쳐 최신 데이터를 영구적으로 손실할 수도 있다는 점 등의 이유 때문이라고 한다.
Load balancing
로드 밸런싱(Load balancing)은 클라어언트로부터의 요청 트래픽 부하를 여러 서버에 분산시키기 위한 기술이다. 앞서 여러 대의 서버들로 구성하여 서버 클러스터링을 구축하였다면 로드 밸런싱은 필수라 볼 수 있다. 이러한 로드 밸런싱을 구현하는 여러가지 알고리즘들이 있다.
참고로 여기서 언급할 로드 밸런싱 알고리즘들은 필자가 조사했을 때 대부분 DB 클러스터링이 아닌 HTTP 요청 분산을 위한 웹 서버 클러스터링을 기반으로 설명하는 자료들이 많아서 이 글에서도 웹 서버 클러스터링을 기반으로 설명하겠다.
Load balancing 알고리즘
- 라운드 로빈 (Round Robin) - 가장 간단한 알고리즘으로, 서버로 들어온 요청 순서대로 돌아가며 서버에 순차적으로 배정하는 방식이다. 예를 들어 1번 요청은 1번 서버에, 2번 요청은 2번 서버에 배정하고, 마지막 서버 이후 또 다른 요청이 들어오면 다시 1번 서버에 배정하는 순회적인 방식을 취한다. 매우 간단한 알고리즘이라 간단한 클러스터링 구조에서는 괜찮겠지만, 서버 간의 성능 차이, 특정 서버 장애 여부 등을 전혀 고려하지 않기 때문에 이 알고리즘을 제대로 활용하려면 모든 서버들의 성능이 균일해야 할 것이다.
- 가중 라운드 로빈 (Weighted Round Robin) - 각 서버들의 성능을 고려하여 각 서버마다 가중치를 부여하고, 가중치가 높은 서버에 우선적으로 요청을 배정하는 방식이다. 예를 들어 A, B 이 두 서버의 가중치 비율이 3:7이라면 A 서버는 3개의 요청을, B 서버에는 7개의 요청을 배분하는 방식인 것이다. 서버 간 성능 차이를 고려하기 때문에 더 효과적인 트래픽 분산을 할 수 있다.
- 최소 연결 (Least Connection) - 현재 클라이언트와의 연결 수가 가장 적은 서버에 요청을 배정하는 방식이다. 예를 들어 A 서버에 7개의 요청이, B 서버에 3개의 요청에 대한 클라이언트와의 연결이 되어 있는 상태라면, 다음 요청은 연결 수가 가장 적은 B 서버에 배정된다. 트래픽 분산이 균일하지 않을 때 사용할 수 있으나, 이를 위해선 계속 모든 서버들의 클라이언트와의 연결 상태를 모니터링해야 한다는 단점도 있다.
- IP 해시 (IP Hash) - 클라이언트의 IP 주소를 해싱(hashing)하여 이를 특정 서버와 매핑하여 요청을 할당하는 방식이다. 이에 따르면 같은 클라이언트는 항상 같은 서버로 배정되므로, 같은 클라이언트가 항상 동일한 서버로의 연결성을 보장해야 할 때, 또는 세션 지속성(sticky session) 및 일관성이 필요할 때 사용할 수 있다.
- 여기서 말하는 세션(session)은 클라이언트와 서버가 물리적 또는 논리적으로 연결되어 상호작용의 흐름을 의미한다. 이러한 새션은 클라이언트-서버 간 “연결”의 생성, 유지, 종료라는 라이프 사이클을 가진다.
- 한 편, 네트워크 로드 밸런싱에 대해 OSI 7계층 중 전송 게층인 4번째 계층과 응용 계층인 7번째 계층을 활용한 로드밸런싱을 각각 L4 로드밸런싱, L7 로드 밸런싱이라 부른다고 한다.
Failover
Failover는 우리말로 “장애 극복 기능”이라고도 하며, 메인 컴퓨터 시스템, 서버, 네트워크 등에서 문제가 발생했을 때 이를 대처하기 위해 예비 시스템으로 자동 전환하는 것을 의미한다. 서버에 장애가 발생해도 사용자에게 지속적인 서비스를 제공할 수 있는 고가용성을 필요로 할 때 필수적인 기능이라 볼 수 있다. 한 편, failover는 “자동” 전환을 의미하며, 사람이 수동으로 전환하면 이것을 switchover라 부른다.
Failover하면 failback이란 개념도 같이 언급되는 경우가 있다. failback은 메인 시스템의 장애로 인해 failover를 통해 예비 시스템으로 전환한 후에 장애가 해결되면 장애 발생 전의 상황으로 되돌리는 것을 의미한다.
예를 들어 두 개의 서버가 각각 active, stand-by 상태의 서버로 존재한다면, 장애 발생 시 active에서 stand-by 서버로 자동 전환하는 것을 failover, 그 후 장애가 해결되었을 때 다시 active 서버로 전환하고, stand-by 서버는 다시 대기 상태로 되돌리는 것을 failback이라 부르는 것이다.
Quartz의 관점에서 되돌아보기
이 글을 쓰게 된 계기인 Quartz 라이브러리에서는 그 소개로 “DB 클러스터링 지원, failover, random 기반의 load balancing 기능 제공”라 소개되곤 하는데, 이것의 의미를 짚어보자.
우선 지난 Quartz 글에서도 소개했듯, Quartz는 in-memory 방식으로 스케줄링 관련 정보들을 RAM에 저장할 수 있을 뿐만 아니라, 아예 DB에 저장하는 기능도 지원한다. 이러한 스케줄링 관련 정보의 영속화 기능 지원으로 인해 특정 서버에서 장애가 발생하여 해당 서버에서의 스케줄링이 중단되더라도, 스케줄링 관련 정보가 이미 DB에 저장되어 있기 때문에 다른 서버에서 이 정보를 토대로 계속 스케줄링 작업을 이어나갈 수 있는 failover가 가능한 것이다.
또한, 여러 대의 서버로 운영하는 클러스터링 환경에서, 클라이언트 또는 trigger에 의한 스케줄링 작업 요청이 들어오면 이를 어떤 서버에 할당할 것인지 결정해야할 것이다. 여기서 스케줄링할 작업은 이미 개발자가 코드 상에서 Job 인터페이스의 구현체로 정의하였고, JobDetail 객체를 통해 해당 작업의 정보들이 JobStore를 거쳐 DB에 저장된 상태이다. 따라서 스케줄링 작업 실행을 위해 모든 서버들이 공유 DB에 접근하여 해당 job 정보를 가져가려고 할 것이다. 이 과정에서 어떤 서버에 job을 배정할 것인지에 대한 “로드 밸런싱”의 문제는 순수히 “가장 먼저 DB에 접근한 서버”에게 Job 실행을 배정하는 방식으로 해결한다고 한다. 여기서 어떤 서버가 먼저 DB에 접근하느냐는 각 서버들의 성능, 네트워크 지연 정도, 특정 서버의 부하 또는 장애 여부 등 여러 가지 조건들에 영향을 받아 예측할 수 없으므로 “랜덤 기반 알고리즘”이라 불린다고 한다. 따라서 스케줄링의 로드 밸런싱 알고리즘을 상황에 맞게끔 커스텀할 수 없다는 것이 흠이기도 하다.
이렇게 스케줄링 정보를 공유 DB에 저장하는 기능을 제공하는 덕분에 Quartz에서는 하나의 작업을 둘 이상의 서버가 중복하여 실행하는 것을 방지할 수 있다. 이러한 의미에서 DB 기반 클러스터링을 지원한다는 것이다.
다시 말하자면, Quartz에서 DB 기반 클러스터링, failover, random 기반 load balancing 기능 모두 가능한 것은 스케줄링 작업 관련 정보들을 DB에도 저장할 수 있다는 Quartz만의 독보적인 특징 덕분에 가능한 것이다.
글을 마치며…
이번 글에서는 지난 글에서 다룬 Quartz 라이브러리의 특징으로 언급되었던 것을 계기로 서버, DB 기반 클러스터링 및 failover, 로드 밸런싱의 개념에 대해 각각 살펴보았다. 이 개념들이 공통적으로 가리키는 것은 결국 단일 서버 사용 시 서버 장애 문제로 인한 서비스 제공의 지속성 확보 어려움 및 요청 트래픽 분산을 위해 여러 서버들로 구성하는 것에서부터 파생된 개념이라는 것이다.
여기서 소개한 기술들과 더불어 모든 기술들은 단순히 “새로 배운 개념이니 무조건 적용해봐야지” 내지 “단일 서버는 무조건 안좋은 것이다”란 생각으로 접근하기보다는 현재 맞딱뜨린 상황에 따라 어떤 기술을 적용해야할지 잘 판단하고 적용하는 접근 방식이 중요하다는 것을 다시 한 번 되새김하며 이 글을 마치겠다.
References
[1] 서버 클러스터링 개념
[2] Quartz 클러스터링 예시
[Quartz] Spring Boot에서 Quartz 클러스터 적용
[3] Fail-over & fail-back
[4] DB 클러터링 및 리플리케이션
[5] [CS Study] Database - Clustering, Replication
[6] 데이터베이스 확장 방식, 클러스터링과 리플리케이션의 차이점 > 블로그 | WhaTap
[7] 참고) 서버 종류
서버의 종류 총정리: 웹 서버, 데이터베이스 서버, 파일 서버 개념과 차이점 이해하기
[8] 참고) 서버 종류
2.2. 클라이언트 and 서버 그리고 WAS, DB서버
[7] 로드 밸런싱
[8] 로드 밸런싱
[네트워크] 로드밸런싱(Load Balancing)이란? 종류와 기법
[9] 로드 밸런싱
로드 밸런싱이란 무엇인가요? - 로드 밸런싱 알고리즘 설명 - AWS
[10] 로드 밸런싱
[11] 로드 밸런싱
Introduction to Load Balancing
[12] https://ko.wikipedia.org/wiki/장애_극복_기능#:~:text=장애 극복 기능
This content is licensed under
CC BY-NC 4.0
![]()
![]()
![]()

댓글남기기